

一、进程和内存管理
内核功用:进程管理、内存管理、文件系统、网络功能、驱动程序、安全功能等

1.1 什么是进程
Process:运行中的程序的一个副本,是被载入内存的一个指令集合,是资源分配的单位
- 进程ID(Process ID,PID)号码被用来标记各个进程
- UID、GID和SELinux语境决定对文件系统的存取和访问权限
- 通常从执行进程的用户来继承
- 存在生命周期
进程创建:
- init:第一个进程,从Centos7以后为systemd
- 进程:都由其父进程创建,fork(),父子关系,Cow:Copy On Write
进程,线程和协程
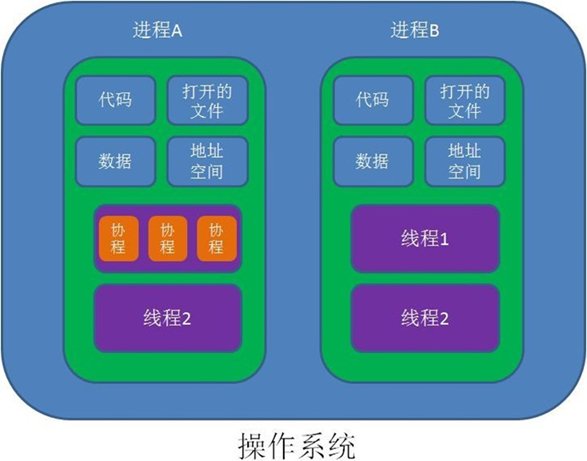
1.1.1 进程
进程是一个具有一定独立功能的程序在一个数据集上的一次动态执行的过程,是操作系统进行资源分配和调度的一个独立单位,是应用程序运行的载体。进程是一种抽象的概念,从来没有统一的标志定义
进程的组成:
进程一般由程序、数据集合和进程控制块三部分组成。
程序用于描述进程要完成的功能,是控制进程执行的指令集:
数据集合是程序在执行时所需要的数据和工作区:
程序控制块(Program Control Block,简称PCB),包含进程的描述信息和控制信息,是进程存在的唯一标志。
进程具有的特征:
动态性:进程是程序的一次执行过程,是临时的,有生命期的,是动态产生,动态消亡的:
并发性:任何进程都可以同其他进程一起并发执行
独立性:进程是系统进行资源分配和调度的一个独立单位:
结构性:进程是由程序、数据和进程控制块三部分组成。
1.1.2 线程
在早期的操作系统中并没有线程的概念,进程是能拥有资源和独立运行的最小单位,也是程序执行的最小单位。任务调度采用的是时间片轮转的抢占式调度方式,而进程是任务调度的最小单位,每个进程有各自独立的一块内存,使得各个进程之间内存地址相互隔离。后来,随着计算机的发展,对CPU的要求越来越高,进程之间的切换开销较大,已经无法满足越来越复杂的程序的要求了。于是就发明了线程。
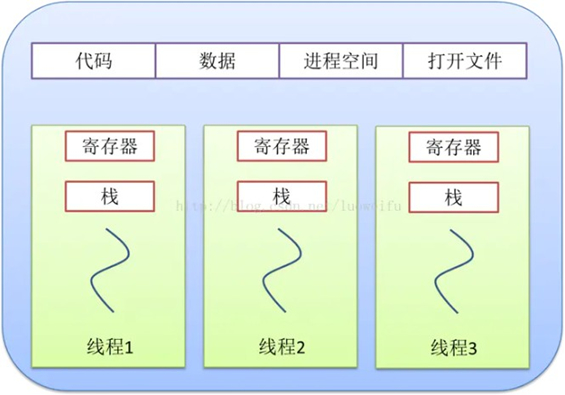
线程是程序执行中一个单一的顺序控制流程,是程序执行流的最小单元,是处理器调度和分派的基本单位。一个进程可以有一个或多个线程,各个线程之间共享程序的内存空间(也就是所在进程的内存空间)。一个标准的线程由线程ID、当前指令指针(PC)、寄存器和堆栈组成。而进程是由内存空间(代码、数据、进程空间、打开的文件)和一个或多个线程组成。
进程与线程的区别
线程是程序执行的最小单位,而进程是操作系统分配资源的最小单位:
一个进程由一个或多个线程组成,线程是一个进程中代码的不同执行路线:
进程之间相互独立,但同一进程下的各个线程之间共享程序的内存空间(包括代码段、数据集、堆等)及一些进程级的资源(如打开文件和信号),某个进程内的线程在其他进程不可见:
调度和切换:线程上下文切换比进程上下文切换要快的多
1.1.3 协程
协程,英文Coroutines,是一种基于线程之上,但又比线程更加轻量级的存在,这种由程序员自己写程序来管理的轻量级线程叫做(用户空间线程),具有对内核来说不可见的特性。
因为是自主开辟的异步任务,所以很多人也更喜欢叫它们纤程(Fiber),或者绿色线程(GreenThread)。正如一个进程可以拥有多个线程一样,一个线程也可以拥有多个协程。
协程的目的:
在传统的J2EE系统中都是基于每个请求占用一个线程去完成完整的业务逻辑(包扣事务)。所以系统的吞吐能力取决于每个线程的操作耗时。如果遇到很耗时的I/O行为,则整个系统的吞吐立刻下降,因为这个时候线程一直处于阻塞状态,如果线程很多的时候,会存在很多线程处于空闲状态(等待该线程执行完才能执行),造成了资源应用不彻底
最常见的例子就是JDBC(他是同步阻塞的),这也是为什么很多人都说数据库是瓶颈的原因。这里的耗时其实是让CPU一直在等待I/O返回,说白了线程根本没有利用CPU去做运算,而是处于空转状态。而另外过多的线程,也会带来更多的ContextSwitch开销。
对于上述问题,现阶段行业里的比较流行的解决方案之一就是单线程加上异步回调。其代表派是node.js以及java里的新秀vert.x。
而协程的目的就是当出现长时间的I/O操作时,通过让出目前的协程调度,执行下一个任务的方式,来消除ContextSwitch上的开销。
协程的特点
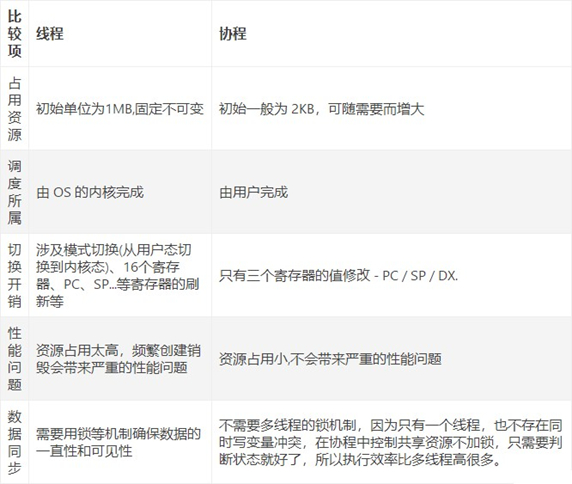
线程的切换由操作系统负责调度,协程由用户自己进行调度,因此减少了上下文切换,提高了效率。
线程的默认Stack大小是1M,而协程更轻量,接近1K。因此可以在相同的内存中开启更多的协程
由于在同一个线程上,因此可以避免竞争关系而使用锁
适用于被阻塞的,且需要大量并发的场景。但不适用于大量计算的多线程,遇到此种情况,更好实用线程去解决
协程的原理:
当出现IO阻塞的时候,由协程的调度器进行调度,通过将数据流立刻yield掉(主动让出),并且记录当前栈上的数据,阻塞完后立刻在通过线程恢复栈,并把阻塞的结果放到这个线程上去跑,这样看上去好像跟写同步代码没有任何差别,这整个流程可以称为coroutine,而跑在由coroutine负责调度的线程称为Fiber。比如Golang里的go关键字其实就是负责开启一个Fiber,让func逻辑跑在上面
由于协程的暂停完全由程序控制,发生在用户态上:而线程的阻塞状态是由操作系统内核来进行切换,发生在内核态上。因此,协程的开销远远小于线程的开销,也就没有了ContextSwitch上的开销。
1.1.4 协程和线程的比较
1.1.5 查看进程中的线程
[17:56:04 root@centos8 ~]#grep -i threads /proc/945/status
Threads: 6
1.2 进程结构
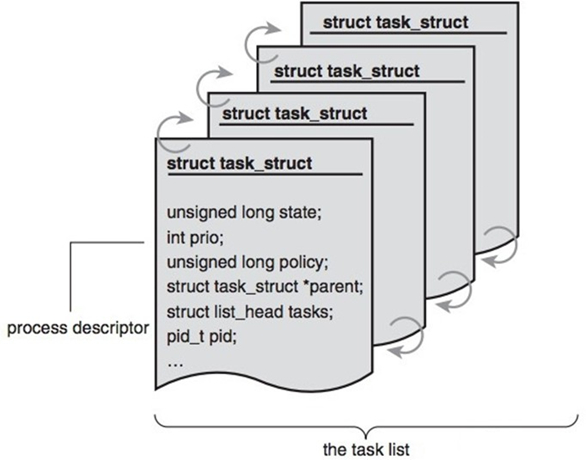
内核把进程存放在叫做任务队列(task list)的双向循环链表中
链表中的每一项都是类型为task_struct,称为进程控制块(Processing Control Block),PCB中包含一个具体进程的所有信息
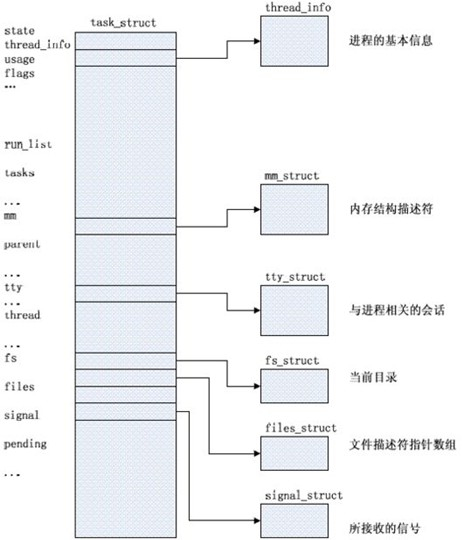
进程控制块PCB包含信息:
- 进程id、用户id和组id
- 程序计数器
- 进程的状态(由就绪、运行、阻塞)
- 进程切换时需要保存和恢复的CPU寄存器的值
- 描述虚拟地址空间的信息
- 描述控制终端的信息
- 当前工作目录
- 文件描述符表,包含很多指向file结构体的指针
- 进程可以使用的资源上限(ulimit -a 命令可以查看)
- 输入输出状态:配置进程使用I/O设备
1.3 进程相关概念
Page Frame:页框,用存储页面数据,存储Page 4K
[18:46:50 root@centos8 ~]#getconf -a | grep -i size
PAGESIZE 4096
PAGE_SIZE 4096
SSIZE_MAX 32767
_POSIX_SSIZE_MAX 32767
_POSIX_THREAD_ATTR_STACKSIZE 200809
FILESIZEBITS 64
POSIX_ALLOC_SIZE_MIN 4096
POSIX_REC_INCR_XFER_SIZE
POSIX_REC_MAX_XFER_SIZE
POSIX_REC_MIN_XFER_SIZE 4096
LEVEL1_ICACHE_SIZE 32768
LEVEL1_ICACHE_LINESIZE 64
LEVEL1_DCACHE_SIZE 32768
LEVEL1_DCACHE_LINESIZE 64
LEVEL2_CACHE_SIZE 262144
LEVEL2_CACHE_LINESIZE 64
LEVEL3_CACHE_SIZE 6291456
LEVEL3_CACHE_LINESIZE 64
LEVEL4_CACHE_SIZE 0
LEVEL4_CACHE_LINESIZE 0
1.3.1 物理地址空间和虚拟地址空间
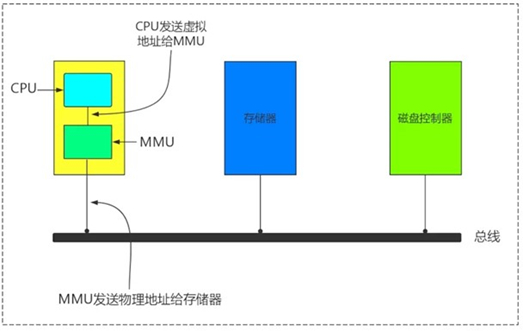
MMU:Menmory Management Unit 负责虚拟地址转换为物理地址
程序在访问一个内存地址指向的内存时,CPU不是直接把这个地址传送到内存总线上,而是被传送到MMU,然后把这个内存地址映射到实际的物理内存地址上,然后通过总线再去访问内存,程序操作的地址称为虚拟内存地址
TLB:Translation Lookaside Buffer翻译后备缓冲区,用于保存虚拟地址和物理地址映射关系的缓存
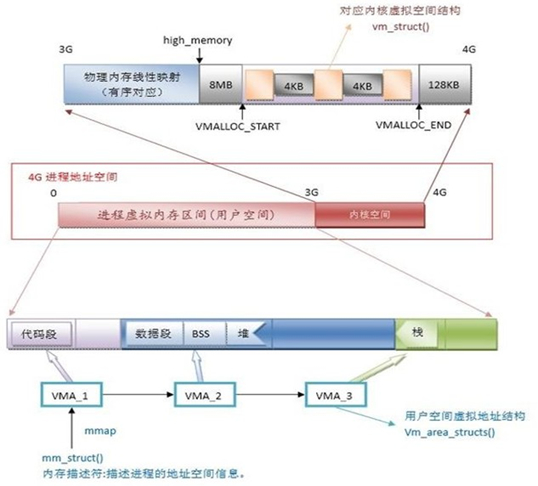
1.3.2 用户和内核空间
1.3.3 C代码和内存布局之间的对应关系
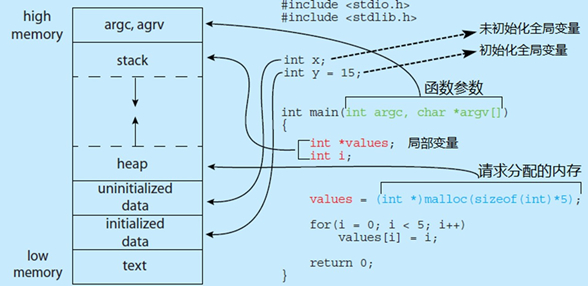
每个进程都包扣5种不同的数据段
- 代码段:用来存放可执行文件的操作指令,也就是说是它是可执行程序在内存中的镜像。代码需要防止在运行时被非法修改,所以只允许读取操作,而不允许写入(修改)操作——它是不可写的
- 数据段:用来存放可执行文件中已初始化全局变量,换句话说就是存放程序静态分配的变量和全局变量
- BSS段:Block Started by Symbol的缩写,意为“以符号开始的块,BSS段包含了程序中未初始化的全局变量,在内存中bss段全部置零
- 堆(heap):存放数组和对象,堆是用于存放进程运行中被动态分配的内存段,他的大小并不固定,可动态扩张或缩减。当进程调用malloc等函数分配内存时,新分配的内存就被动态添加到堆上(堆被扩张);当利用free等函数释放内存时,被释放的内存从堆中被剔除(堆被缩减)
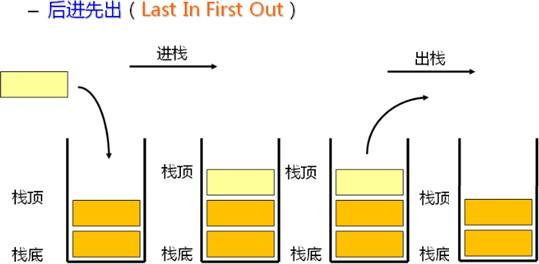
- 栈(stack):栈是用户存放程序临时创建的局部变量,也就是说我们函数括弧”{}“中定义的变量(但不包括static声明的变量,static意味着在数据段中存放变量)。除此以外,在函数被调用时,其参数也会被压入发起调用的进程栈中,并且待到调用结束后,函数的返回值也会被存放会栈中。由于栈的后进先出特点,所以栈特别方便用来保存/恢复调用现场。可以把栈堆看成一个寄存器、交换临时数据的内存区
喝多了吐就是栈,吃多了拉就是队列:栈先进后出,队列先进先出
1.3.4 进程使用内存问题
1.3.4.1 内存泄露:Memory Leak
指程序中用malloc或new申请了一块内存,但是没有用free或delete将内存释放,导致这块内存一直处于占用状态
1.3.4.2 内存溢出:Memory Overflow
指程序申请了10M的空间,但是在这个空间写入10M以上字节的数据,就是溢出。
1.3.4.3 内存不足:OOM
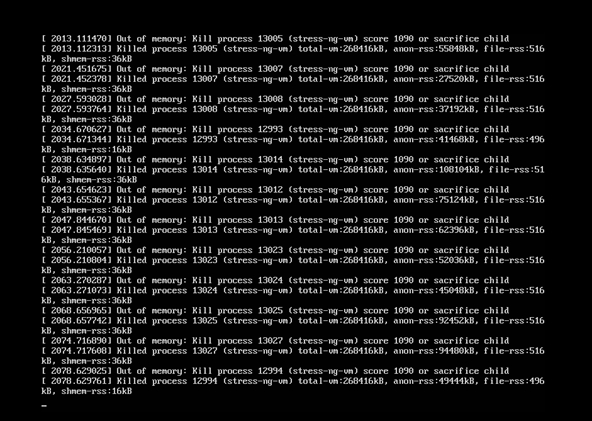
OOM 即 Out Of Memory,“内存用完了”,在情况在java程序中比较常见。系统会选一个进程将之杀死, 在日志messages中看到类似下面的提示
Jul 10 10:20:30 kernel: Out of memory: Kill process 9527 (java) score 88 or sacrifice child
当JVM因为没有足够的内存来为对象分配空间并且垃圾回收器也已经没有空间可回收时,就会抛出这个error,因为这个问题已经严重到不足以被应用处理)。
原因:
- 给应用分配内存太少:比如虚拟机本身可使用的内存(一般通过启动时的VM参数指定)太少。
- 应用用的太多,并且用完没释放,浪费了。此时就会造成内存泄露或者内存溢出。
使用的解决办法:
1,限制java进程的max heap,并且降低java程序的worker数量,从而降低内存使用2,给系统增加swap空间
设置内核参数(不推荐),不允许内存申请过量:
echo 2 > /proc/sys/vm/overcommit_memory
echo 80 > /proc/sys/vm/overcommit_ratio
echo 2 > /proc/sys/vm/panic_on_oom
说明:
Linux默认是允许memory overcommit的,只要你来申请内存我就给你,寄希望于进程实际上用不到那么多内存,但万一用到那么多了呢?Linux设计了一个OOM killer机制挑选一个进程出来杀死,以腾出部分内存,如果还不够就继续。也可通过设置内核参数 vm.panic_on_oom 使得发生OOM时自动重启系统。这都是有风险的机制,重启有可能造成业务中断,杀死进程也有可能导致业务中断。所以
Linux 2.6之后允许通过内核参数 vm.overcommit_memory 禁止memory overcommit。
vm.panic_on_oom 决定系统出现oom的时候,要做的操作。接受的三种取值如下:
0 - 默认值,当出现oom的时候,触发oom killer
1 - 程序在有cpuset、memory policy、memcg的约束情况下的OOM,可以考虑不panic,而是启动OOM killer。其它情况触发 kernel panic,即系统直接重启
2 - 当出现oom,直接触发kernel panic,即系统直接重启
vm.overcommit_memory 接受三种取值:
0 – Heuristic overcommit handling. 这是缺省值,它允许overcommit,但过于明目张胆的overcommit会被拒绝,比如malloc一次性申请的内存大小就超过了系统总内存。Heuristic的意思是“试 探式的”,内核利用某种算法猜测你的内存申请是否合理,它认为不合理就会拒绝overcommit。
1 – Always overcommit. 允许overcommit,对内存申请来者不拒。内核执行无内存过量使用处理。使用这个设置会增大内存超载的可能性,但也可以增强大量使用内存任务的性能。
2 – Don’t overcommit. 禁止overcommit。 内存拒绝等于或者大于总可用 swap 大小以及overcommit_ratio 指定的物理 RAM 比例的内存请求。如果希望减小内存过度使用的风险,这个设置就是最好的。
Heuristic overcommit算法:
单次申请的内存大小不能超过以下值,否则本次申请就会失败。
free memory + free swap + pagecache的大小 + SLAB
vm.overcommit_memory=2 禁止overcommit,那么怎样才算是overcommit呢?
kernel设有一个阈值,申请的内存总数超过这个阈值就算overcommit,在/proc/meminfo中可以看到 这个阈值的大小:
[18:46:58 root@centos8 ~]#grep -i commit /proc/meminfo
CommitLimit: 2584584 kB
Committed_AS: 297536 kB
CommitLimit 就是overcommit的阈值,申请的内存总数超过CommitLimit的话就算是overcommit。此值通过内核参数vm.overcommit_ratio或vm.overcommit_kbytes间接设置的,公式如下:
CommitLimit = (Physical RAM * vm.overcommit_ratio / 100) + Swap
vm.overcommit_ratio 是内核参数,缺省值是50,表示物理内存的50%。如果你不想使用比率,也可以直接指定内存的字节数大小,通过另一个内核参数 vm.overcommit_kbytes 即可;
如果使用了huge pages,那么需要从物理内存中减去,公式变成:
CommitLimit = ([total RAM] – [total huge TLB RAM]) * vm.overcommit_ratio / 100 + swap
/proc/meminfo中的 Committed_AS 表示所有进程已经申请的内存总大小,(注意是已经申请的,不是已经分配的),如果 Committed_AS 超过 CommitLimit 就表示发生了 overcommit,超出越多表示overcommit 越严重。Committed_AS 的含义换一种说法就是,如果要绝对保证不发生OOM (out of memory) 需要多少物理内存。
范例:
[root@centos8 ~]#cat /proc/sys/vm/panic_on_oom 0
[root@centos8 ~]#cat /proc/sys/vm/overcommit_memory 0
[root@centos8 ~]#cat /proc/sys/vm/overcommit_ratio 50
[root@centos8 ~]#grep -i commit /proc/meminfo
CommitLimit: 3021876 kB
Committed_AS: 340468 kB
1.4 进程状态
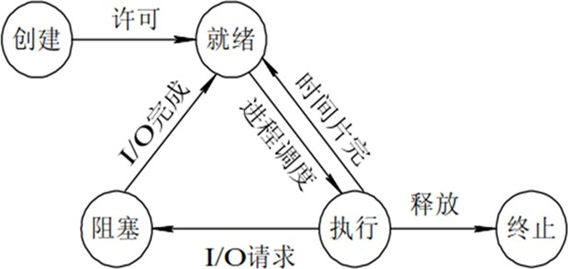
进程的基本状态
- 创建状态:进程在创建时需要申请一个空白PCB(process control block进程控制块),向其中填写 控制和管理进程的信息,完成资源分配。如果创建工作无法完成,比如资源无法满足,就无法被调 度运行,把此时进程所处状态称为创建状态
- 就绪状态:进程已准备好,已分配到所需资源,只要分配到CPU就能够立即运行执行状态:进程处于就绪状态被调度后,进程进入执行状态
- 阻塞状态:正在执行的进程由于某些事件(I/O请求,申请缓存区失败)而暂时无法运行,进程受 到阻塞。在满足请求时进入就绪状态等待系统调用
- 终止状态:进程结束,或出现错误,或被系统终止,进入终止状态。无法再执行
状态之间转换六种情况
- 运行——>就绪:1,主要是进程占用CPU的时间过长,而系统分配给该进程占用CPU的时间是有限的; 2,在采用抢先式优先级调度算法的系统中,当有更高优先级的进程要运行时,该进程就被迫让出CPU, 该进程便由执行状态转变为就绪状态
- 就绪——>运行:运行的进程的时间片用完,调度就转到就绪队列中选择合适的进程分配CPU
- 运行——>阻塞:正在执行的进程因发生某等待事件而无法执行,则进程由执行状态变为阻塞状态,如 发生了I/O请求
- 阻塞——>就绪:进程所等待的事件已经发生,就进入就绪队列
以下两种状态是不可能发生的:
- 阻塞——>运行:即使给阻塞进程分配CPU,也无法执行,操作系统在进行调度时不会从阻塞队列进行挑选,而是从就绪队列中选取
- 就绪——>阻塞:就绪态根本就没有执行,谈不上进入阻塞态
进程更多的状态:
- 运行态:running
- 就绪态:ready
- 睡眠态:分为两种,可中断:interruptable,不可中断:uninterruptable
- 停止态:stopped,暂停于内存,但不会被调度,除非手动启动
- 僵死态:zombie,僵尸态,结束进程,父进程结束前,子进程不关闭,杀死父进程可以关闭僵死态 的子进程

范例:僵尸态
[root@centos8 ~]#bash [root@centos8 ~]#echo $BASHPID 1809
[root@centos8 ~]#echo $PPID 1436
#将父进程设为停止态
[root@centos8 ~]#kill -19 1436
#杀死子进程,使其进入僵尸态
[root@centos8 ~]#kill -9 1809
[root@centos8 ~]#ps aux #可以看到上面图示的结果,STAT为Z,表示为僵尸态
#方法1:恢复父进程
[root@centos8 ~]#kill -18 1436 #方法2:杀死父进程
[root@centos8 ~]#kill -9 1436
#再次观察,可以僵尸态的进程不存在了
[root@centos8 ~]#ps aux
1.5 LRU算法
LRU:Least Recently Used 近期最少使用算法(喜新厌旧),释放内存
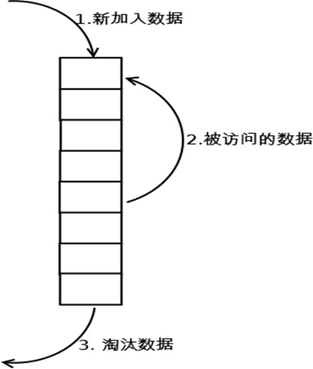
范例:
假设序列为 4 3 4 2 3 1 4 2, 物理块有3个,则
第1轮 4调入内存 4
第2轮 3调入内存 3 4
第3轮 4调入内存 4 3
第4轮 2调入内存 2 4 3
第5轮 3调入内存 3 2 4
第6轮 1调入内存 1 3 2
第7轮 4调入内存 4 1 3
第8轮 2调入内存 2 4 1
1.6 IPC进程间通信
IPC: Inter Process Communication
- 同一主机:
pipe 管道,单向传输
socket 套接字文件
Memory-maped file 文件映射,将文件中的一段数据映射到物理内存,多个进程共享这片内存
shm shared memory 共享内存
signal 信号
Lock 对资源上锁,如果资源已被某进程锁住,则其它进程想修改甚至读取这些资源,都将被 阻塞,直到锁被打开
semaphore 信号量,一种计数器
- 不同主机:socket=IP和端口号
RPC remote procedure call
MQ 消息队列,生产者和消费者,如:Kafka,RabbitMQ,ActiveMQ
范例:利用管道文件实现进IPC
[19:28:52 root@centos8 ~]#mkfifo /root/test.fifo
[19:33:27 root@centos8 ~]#ll /root/test.fifo
prw-r--r-- 1 root root 0 Jan 2 19:33 /root/test.fifo
[19:33:35 root@centos8 ~]#cat > /root/test.fifo
zhangzhuo
#在另一个终端可以从文件中读取数据
[19:34:12 root@centos8 ~]#cat /root/test.fifo
zhangzhuo
范例:查找socket文件
[19:36:17 root@centos8 ~]#find / -type s -ls
1.7 进程优先级
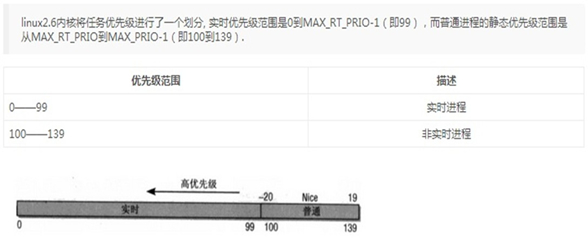
CentOS 优先级

进程优先级:
系统优先级:0-139, 数字越小,优先级越高,各有140个运行队列和过期队列
实时优先级: 99-0 值最大优先级最高
nice值:-20到19,对应系统优先级100-139或
Big O:时间(空间)复杂度,用时(空间)和规模的关系
O(1), O(logn), O(n)线性, O(n^2)抛物线, O(2^n)
1.8 进程分类
操作系统分类:
- 协作式多任务:早期 windows 系统使用,即一个任务得到了 CPU 时间,除非它自己放弃使用CPU ,否则将完全霸占 CPU ,所以任务之间需要协作——使用一段时间的 CPU ,主动放弃使用
- 抢占式多任务:Linux内核,CPU的总控制权在操作系统手中,操作系统会轮流询问每一个任务是否需要使用 CPU ,需要使用的话就让它用,不过在一定时间后,操作系统会剥夺当前任务的 CPU 使用权,把它排在询问队列的最后,再去询问下一个任务
进程类型:
- 守护进程: daemon,在系统引导过程中启动的进程,和终端无关进程
- 前台进程:跟终端相关,通过终端启动的进程
注意:两者可相互转化
按进程资源使用的分类:
- CPU-Bound:CPU 密集型,非交互
- IO-Bound:IO 密集型,交互
1.9 IO调度算法
- NOOP
- NOOP算法的全写为No Operation。该算法实现了最简单的FIFO队列,所有IO请求大致按照先来 后到的顺序进行操作。之所以说“大致”,原因是NOOP在FIFO的基础上还做了相邻IO请求的合并, 并不是完完全全按照先进先出的规则满足IO请求。NOOP假定I/O请求由驱动程序或者设备做了优 化或者重排了顺序(就像一个智能控制器完成的工作那样)。在有些SAN环境下,这个选择可能是最好选择。Noop 对于 IO 不那么操心,对所有的 IO请求都用 FIFO 队列形式处理,默认认为 IO 不会存在性能问题。这也使得 CPU 也不用那么操心。当然,对于复杂一点的应用类型,使用这个调度器,用户自己就会非常操心。
- CFQ
- CFQ算法的全写为Completely Fair Queuing。该算法的特点是按照IO请求的地址进行排序,而不是按照先来后到的顺序来进行响应。 在传统的SAS盘上,磁盘寻道花去了绝大多数的IO响应时间。CFQ的出发点是对IO地址进行排序,以尽量少的磁盘旋转次数来满足尽可能多的IO请求。在CFQ算法下,SAS盘的吞吐量大大提高了。但是相比于NOOP的缺点是,先来的IO请求并不一定能 被满足,可能会出现饿死的情况。
- Completely Fair Queuing (cfq, 完全公平队列) 在 2.6.18 取代了 Anticipatory scheduler 成为Linux Kernel 默认的 IO scheduler 。cfq 对每个进程维护一个 IO 队列,各个进程发来的 IO 请求会被 cfq 以轮循方式处理。也就是对每一个 IO 请求都是公平的。这使得 cfq 很适合离散读的应用(eg: OLTP DB)
- Deadline scheduler
- DEADLINE在CFQ的基础上,解决了IO请求饿死的极端情况。deadline 算法保证对于既定的 IO 请求以最小的延迟时间,除了CFQ本身具有的IO排序队列之外,DEADLINE额外分别为读IO和写IO提 供了FIFO队列。读FIFO队列的最大等待时间为500ms,写FIFO队列的最大等待时间为5s。FIFO队 列内的IO请求优先级要比CFQ队列中的高,,而读FIFO队列的优先级又比写FIFO队列的优先级高。优先级可以表示如下:
- FIFO(Read) > FIFO(Write) > CFQ
- Anticipatory scheduler
- CFQ和DEADLINE考虑的焦点在于满足零散IO请求上。对于连续的IO请求,比如顺序读,并没有做 优化。为了满足随机IO和顺序IO混合的场景,Linux还支持ANTICIPATORY调度算法。
- ANTICIPATORY的在DEADLINE的基础上,为每个读IO都设置了6ms 的等待时间窗口。如果在这6ms内OS收到了相邻位置的读IO请求,就可以立即满足 Anticipatory scheduler(as) 曾经一度是 Linux 2.6 Kernel 的 IO scheduler 。Anticipatory 的中文含义是”预料的, 预想的”, 这个词的确揭示了这个算法的特点,简单的说,有个 IO 发生的时候,如果又有进程请求 IO 操作,则将产生一个默认的 6 毫秒猜测时间,猜测下一个 进程请求 IO 是要干什么的。这对于随即读取会造成比较大的延时,对数据库应用很糟糕,而对于 Web Server 等则会表现的不错。这个算法也可以简单理解为面向低速磁盘的,因为那个”猜测”实际上的目的是为了减少磁头移动时间。
范例:查看IO调度算法
[19:36:37 root@centos8 ~]#cat /sys/block/sda/queue/scheduler
[mq-deadline] kyber bfq none
#每个Linux发行版可能都不一样
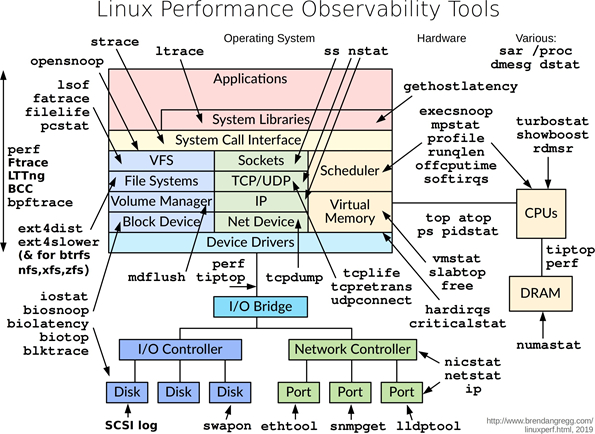
二、进程管理和性能工具
参考链接:http://www.brendangregg.com/linuxperf.html
2.1 进程树pstree
pstree 可以用来显示进程的父子关系,以树形结构显示
格式:
pstree [OPTION] [ PID | USER ]
常用选项:
-p 显示PID
-T 不显示线程thread,默认显示线程
-u 显示用户切换
-H pid 高亮显示指定进程及其前辈进程
范例:
[19:17:24 root@centos8 ~]#pstree 1
[19:18:01 root@centos8 ~]#pstree zhang
bash───ping
[19:18:47 root@centos8 ~]#pstree -pT
[19:19:05 root@centos8 ~]#pstree -u
2.2 进程信息ps
ps 即 process state,可以进程当前状态的快照,默认显示当前终端中的进程,Linux系统各进程的相关信息均保存在/proc/PID目录下的各文件中
ps格式
ps [OPTION]...
支持三种选项:
- UNIX选项如: -A -e
- BSD选项如: a
- GNU选项如: --help
常用选项:
a 选项包括所有终端中的进程x 选项包括不链接终端的进程u 选项显示进程所有者的信息
f 选项显示进程树,相当于 --forest
k|--sort 属性 对属性排序,属性前加 - 表示倒序
o 属性… 选项显示定制的信息 pid、cmd、%cpu、%mem L 显示支持的属性列表
-C cmdlist 指定命令,多个命令用,分隔
-L 显示线程
-e 显示所有进程,相当于-A
-f 显示完整格式程序信息
-F 显示更完整格式的进程信息
-H 以进程层级格式显示进程相关信息
-u userlist 指定有效的用户ID或名称
-U userlist 指定真正的用户ID或名称
-g gid或groupname 指定有效的gid或组名称
-G gid或groupname 指定真正的gid或组名称
-p pid 显示指pid的进程
--ppid pid 显示属于pid的子进程
-t ttylist 指定tty,相当于 t
-M 显示SELinux信息,相当于Z
ps输出属性
C : ps -ef 显示列 C 表示cpu利用率
VSZ: Virtual memory SiZe,虚拟内存集,线性内存RSS: ReSident Size, 常驻内存集
STAT:进程状态
R:running
S: interruptable sleeping
D: uninterruptable sleeping
T: stopped
Z: zombie
+: 前台进程
l: 多线程进程L:
内存分页并带锁N:
低优先级进程
<: 高优先级进程
s: session leader,会话(子进程)发起者
I:Idle kernel thread,CentOS 8 新特性
ni: nice值
pri: priority 优先级
rtprio: 实时优先级
psr: processor CPU编号
示例:
[19:19:25 root@centos8 ~]#ps axo pid,cmd,psr,ni,pri,rtprio
常用组合
aux
-ef
-eFH
-eo pid,tid,class,rtprio,ni,pri,psr,pcpu,stat,comm
axo stat,euid,ruid,tty,tpgid,sess,pgrp,ppid,pid,pcpu,comm
范例:查看进程详细信息
[19:23:25 root@centos8 ~]#ps -ef
[19:24:57 root@centos8 ~]#ps aux
#查看进程特定属性
[19:25:59 root@centos8 ~]#ps axo pid,cmd,%mem,%cpu
范例:针对属性排序,Centos6以下版本不支持
#按CPU利用率倒序排序
[19:27:36 root@centos8 ~]#ps aux k -%cpu
#按内存倒序排序
[19:29:46 root@centos8 ~]#ps axo pid,cmd,%cpu,%mem k -%mem
范例:有效用户和实际用户
[zhang@centos8 ~]$ passwd
Changing password for user zhang.
Current password:
[19:30:34 root@centos8 ~]#ps axo pid,cmd,%cpu,%mem,user,euser,ruser | grep passwd
1878 passwd 0.0 0.8 root root zhang
1880 grep --color=auto passwd 0.0 0.1 root root root
euser:为有效用户,执行这个进程生效的用户,一般执行文件带有suid权限会出现实际用户和有效用户不一样
ruser:为实际用户,实际执行这个进程的用户
范例:
#查询你拥有的所有进程
[19:38:23 root@centos8 ~]#ps -x
#显示指定用户名(RUID)或用户ID的进程
[19:38:52 root@centos8 ~]#ps -u postfix
[19:39:22 root@centos8 ~]#ps -u 89
#显示指定用户名(EUID)或用户ID的进程
[19:39:54 root@centos8 ~]#ps -fu postfix
[19:39:29 root@centos8 ~]#ps -fu 89
#查看以root用户权限(实际和有效ID)运行的每个进程
[19:40:36 root@centos8 ~]#ps -U root -u root
#列出某个组拥有的所有进程(实际组ID:RGID或名称)
[19:40:36 root@centos8 ~]#ps -fG postfix
#列出有效组名称(或会话)所拥有的所有进程
[19:41:53 root@centos8 ~]#ps -fg postfix
[19:42:37 root@centos8 ~]#ps -fg 89
#显示指定的进程ID对应的进程
[19:43:30 root@centos8 ~]#ps -fp 1853
#以父进程ID来显示其下所有的进程,如显示父进程为855的所有进程
[19:45:04 root@centos8 ~]#ps -f --ppid 855
#显示指定PID的多个进程
[19:46:42 root@centos8 ~]#ps -fp 1,835
#要按tty显示所属进程
[19:46:46 root@centos8 ~]#ps -ft pts/0
#以进程树显示系统中的进程如何相互链接
[19:47:30 root@centos8 ~]#ps -e --forest
#以进程树显示指定的进程
[19:48:18 root@centos8 ~]#ps -e --forest -C sshd
[19:48:18 root@centos8 ~]#ps -e --forest | grep -v grep | grep sshd
#要显示一个进程的所有线程,将显示LWP(轻量级进程)以及NLWP(轻量级进程数)列
[19:50:05 root@centos8 ~]#ps -fL -C nginx
#要列出所有格式说明符
[19:50:23 root@centos8 ~]#ps -L
#查看进程的PID,PPID,用户名和命令
[19:51:14 root@centos8 ~]#ps -eo pid,ppid,user,cmd
#自定义格式显示文件系统组,ni值开始时间和进程的时间
[19:51:28 root@centos8 ~]#ps -p 1 -o pid,ppid,fgroup,ni,lstart,etime
#使用其PID查找进程名称:
[19:52:06 root@centos8 ~]#ps -p 1830 -o comm=
#要以其名称选择特定进程,显示其所有子进程
[19:52:50 root@centos8 ~]#ps -C sshd,bash
#查找指定进程名所有的所属PID,在编写需要从std输出或文件读取PID的脚本时这个参数很有用
[19:53:11 root@centos8 ~]#ps -C sshd -o pid=
#检查一个进程的执行时间
[19:53:38 root@centos8 ~]#ps -eo comm,etime,user | grep nginx
#排序,查找占用最多内存和CPU的进程
[19:54:06 root@centos8 ~]#ps -eo pid,ppid,cmd,%cpu,%mem --sort=-%mem | head
[19:55:04 root@centos8 ~]#ps -eo pid,ppid,cmd,%cpu,%mem --sort=-%cpu | head
#显示安全信息
[19:55:38 root@centos8 ~]#ps -eM
[19:55:50 root@centos8 ~]#ps --context
#使用以下命令以用户定义的格式显示安全信息
[19:56:51 root@centos8 ~]#ps -eo euser,ruser,suser,fuser,f,comm,label
#使用watch实用程序执行重复的输出以实现对就程进行实时的监视,如下面的命令显示每秒钟的监视
[19:58:12 root@centos8 ~]#watch -n 1 'ps -eo pid,ppid,cmd,%mem,%cpu --sort=-%mem | head
面试题:查看未知进程的执行程序文件路径
[20:00:27 root@centos8 ~]#ls -l /proc/1852/exe
lrwxrwxrwx 1 root root 0 Jan 4 19:31 /proc/1852/exe -> /usr/bin/su
范例:查看优先级和CPU绑定关系
[20:02:06 root@centos8 ~]#ps axo pid,cmd,ni,pri,psr,rtprio | grep bash
1363 -bash 0 19 0 -
1830 -bash 0 19 0 -
1853 -bash 0 19 0 -
4324 grep --color=auto bash 0 19 0 -
范例:实现进程和CPU的绑定
[20:04:14 root@centos8 ~]#taskset --help
Usage: taskset [options] [mask | cpu-list] [pid|cmd [args...]]
#并不能固定永久绑定,只要pid号变化就无效了
2.3 查看进程信息 prtstat
可以显示进程信息,来自于psmisc包
格式:
prtstat [options] PID ...
选项:
-r raw格式显示
[20:06:56 root@centos8 ~]#prtstat -r 4325
[20:07:38 root@centos8 ~]#prtstat 4325
2.4 设置和调整进程优先级
进程优先级调整
- 静态优先级:100-139
- 进程默认启动时的nice值为0,优先级为120
- 只有根用户才能降低nice值(提高优先性)
nice命令
以指定的优先级来启动进程
nice [OPTION] [COMMAND [ARG]...]
-n, --adjustment=N add integer N to the niceness (default 10)
renice命令
可以调整正在执行中的进程的优先级
renice [-n] priority pid...
查看
ps axo pid,comm,ni
范例:
[20:08:03 root@centos8 ~]#nice -n -10 ping 127.0.0.1
[20:10:24 root@centos8 ~]#ps axo pid,cmd,nice | grep ping
4409 ping 127.0.0.1 -10
4415 grep --color=auto ping 0
[20:11:35 root@centos8 ~]#renice -n 20 4417
4417 (process ID) old priority -10, new priority 19
[20:11:46 root@centos8 ~]#ps axo pid,cmd,nice | grep ping
4417 ping 127.0.0.1 19
4422 grep --color=auto ping 0
2.5 搜索进程
按条件搜索进程
- ps 选项 | grep 'pattern' 灵活
- pgrep 按预定义的模式
- /sbin/pidof 按确切的程序名称查看pid
2.5.1 pgrep
命令格式
pgrep [options] pattern
常用选项
-u uid: effective user,生效者
-U uid: real user,真正发起运行命令者
-t terminal: 与指定终端相关的进程
-l: 显示进程名
-a: 显示完整格式的进程名
-P pid: 显示指定进程的子进程
范例:
[20:14:23 root@centos8 ~]#pgrep -u zhang
4427
[20:14:29 root@centos8 ~]#pgrep -lu zhang
4427 bash
[20:14:36 root@centos8 ~]#pgrep -au zhang
[20:14:49 root@centos8 ~]#pgrep -aP 4427
4455 dd if=/dev/zero of=/dev/null
[20:15:27 root@centos8 ~]#pgrep -at pts/1
1830 -bash
4426 su - zhang
4427 -bash
4455 dd if=/dev/zero of=/dev/null
[20:15:47 root@centos8 ~]#
2.5.2 pidof
命令格式:
pidof [options] [program [...]]
常用选项
-x 按脚本名称查找pid
范例:
[20:15:47 root@centos8 ~]#pidof bash
4476 1830 1363
[20:17:39 root@centos8 ~]#pidof 1.sh
[20:17:43 root@centos8 ~]#pidof -x 1.sh
4476
2.6 负载查询 uptime
/proc/uptime 包括两个值,单位 s
- 系统启动时长
- 空闲进程的总时长(按总的CPU核数计算)
uptime 和 w 显示以下内容
- 当前时间
- 系统已启动的时间
- 当前上线人数
- 系统平均负载(1、5、15分钟的平均负载,一般不会超过1,超过5时建议警报)
系统平均负载: 指在特定时间间隔内运行队列中的平均进程数,通常每个CPU内核的当前活动进程数不大于3,那么系统的性能良好。如果每个CPU内核的任务数大于5,那么此主机的性能有严重问题
如:linux主机是1个双核CPU,当Load Average 为6的时候说明机器已经被充分使用
范例:
[20:18:04 root@centos8 ~]#uptime
20:19:22 up 2:33, 2 users, load average: 0.10, 0.42, 0.42
[20:19:22 root@centos8 ~]#w
20:19:27 up 2:33, 2 users, load average: 0.09, 0.41, 0.42
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
root pts/0 192.168.10.1 19:07 1:40 0.29s 0.29s -bash
root pts/1 192.168.10.1 19:31 6.00s 0.03s 0.00s w
2.7 显示CPU相关统计mpstat
来自于sysstat包
范例:
[20:20:44 root@centos8 ~]#mpstat
Linux 4.18.0-193.el8.x86_64 (centos8) 01/04/2021 _x86_64_ (1 CPU)
08:20:48 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
08:20:48 PM all 3.36 0.02 3.17 0.08 0.14 0.08 0.00 0.00 0.00 93.15
[20:20:48 root@centos8 ~]#mpstat 1 3
Linux 4.18.0-193.el8.x86_64 (centos8) 01/04/2021 _x86_64_ (1 CPU)
08:20:59 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
08:21:00 PM all 0.00 0.00 0.00 0.00 1.00 0.00 0.00 0.00 0.00 99.00
08:21:01 PM all 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
08:21:02 PM all 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
Average: all 0.00 0.00 0.00 0.00 0.33 0.00 0.00 0.00 0.00 99.67
2.8 查看进程实时状态top和htop
2.8.1 top
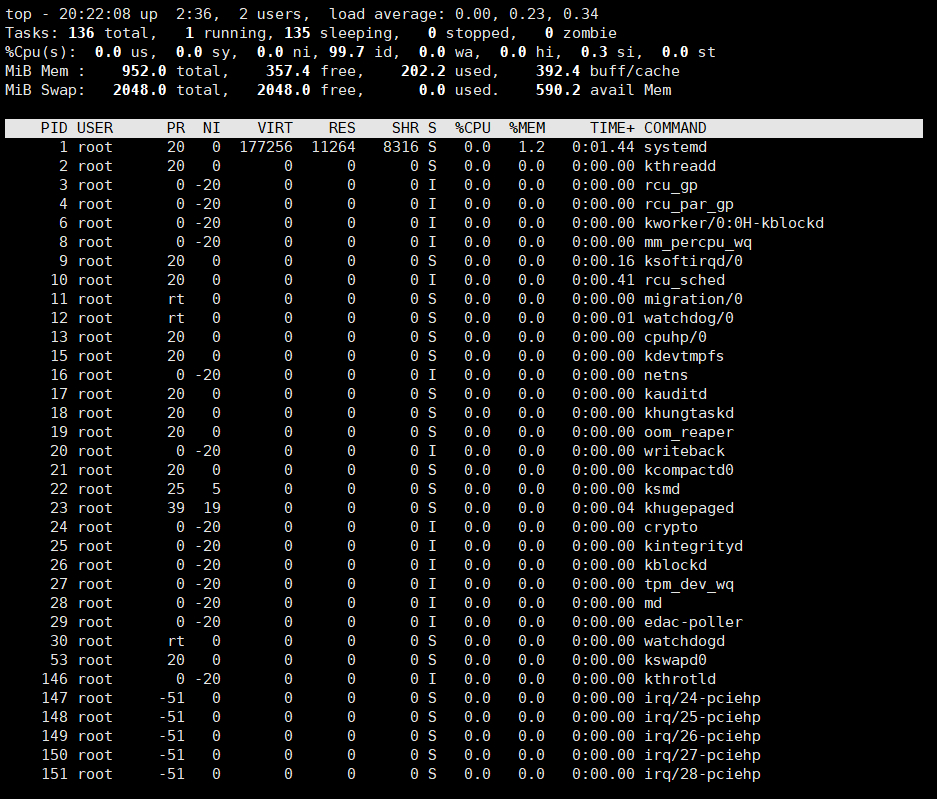
top提供动态的实时进程状态
有许多内置命令
帮助:h 或 ? ,按 q 或esc 退出帮助
排序:
P:以占据的CPU百分比,%CPU
M:占据内存百分比,%MEM
T:累积占据CPU时长,TIME+
首部信息显示:
uptime信息:l命令
tasks及cpu信息:t命令
cpu分别显示:1 (数字)
memory信息:m命令
退出命令:q
修改刷新时间间隔:s
终止指定进程:k
保存文件:W
top命令栏位信息简介
us: 用 户 空 间
sy: 内 核 空 间
ni:调整nice时间
id: 空 闲
wa:等待IO时间
hi:硬中断
si:软中断(模式切换)
st:虚拟机偷走的时间
top选项
-d # 指定刷新实际间隔,默认为3秒
-b 全部显示所有进程
-n # 刷新多少次后退出
-H 线程模式
示例:
[20:28:03 root@centos8 ~]#top -H -p 855
2.8.2 htop
htop 命令是增强版的TOP命令,来自EPEL源,比top功能更强
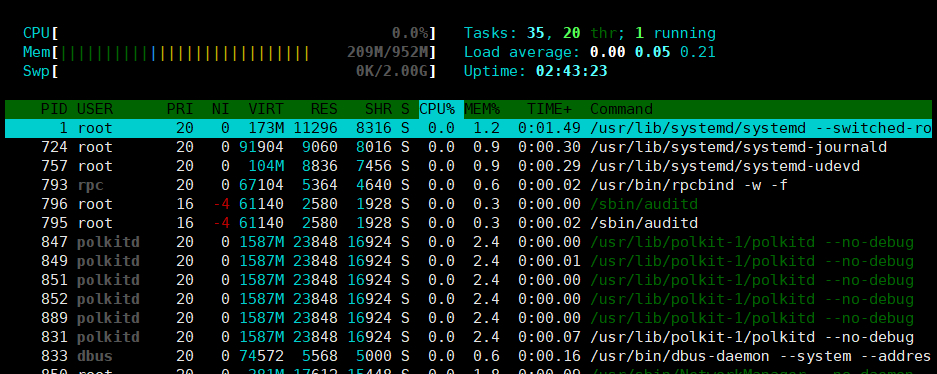
选项:
-d #: 指定延迟时间;
-u UserName: 仅显示指定用户的进程
-s COLUME: 以指定字段进行排序
子命令:
s:跟踪选定进程的系统调用
l:显示选定进程打开的文件列表
a:将选定的进程绑定至某指定CPU核心
t:显示进程树
2.9 内存空间free

向/proc/sys/vm/drop_caches中写入相应的修改值,会清理缓存。建议先执行sync(sync 命令将所有未写的系统缓冲区写到磁盘中,包含已修改的 i-node、已延迟的块 I/O 和读写映射文件)。执行echo 1、2、3 至 /proc/sys/vm/drop_caches, 达到不同的清理目的
如果因为是应用有像内存泄露、溢出的问题时,从swap的使用情况是可以比较快速可以判断的,但通 过执行free 反而比较难查看。但核心并不会因为内存泄露等问题并没有快速清空buffer或cache(默认值是0),生产也不应该随便去改变此值。
一般情况下,应用在系统上稳定运行了,free值也会保持在一个稳定值的。当发生内存不足、应用获取 不到可用内存、OOM错误等问题时,还是更应该去分析应用方面的原因,否则,清空buffer,强制腾 出free的大小,可能只是把问题给暂时屏蔽了。
排除内存不足的情况外,除非是在软件开发阶段,需要临时清掉buffer,以判断应用的内存使用情况; 或应用已经不再提供支持,即使应用对内存的时候确实有问题,而且无法避免的情况下,才考虑定时清 空buffer。
说明: man 5 proc
[root@centos8 ~]#man proc
.....
To free pagecache, use:
echo 1 > /proc/sys/vm/drop_caches
To free dentries and inodes, use:
echo 2 > /proc/sys/vm/drop_caches
To free pagecache, dentries and inodes, use:
echo 3 > /proc/sys/vm/drop_caches
范例:清理缓存
[20:32:40 root@centos8 ~]#cat /proc/sys/vm/drop_caches
0
[20:32:52 root@centos8 ~]#free -h
total used free shared buff/cache available
Mem: 952Mi 202Mi 353Mi 6.0Mi 395Mi 590Mi
Swap: 2.0Gi 0B 2.0Gi
[20:32:58 root@centos8 ~]#echo 3 > /proc/sys/vm/drop_caches
[20:33:19 root@centos8 ~]#free -h
total used free shared buff/cache available
Mem: 952Mi 181Mi 649Mi 6.0Mi 121Mi 636Mi
Swap: 2.0Gi 0B 2.0Gi
2.10 进程对应的内存映射pmap
格式:
pmap [options] pid [...]
常用选项
-x: 显示详细格式的信息
范例:
[20:33:20 root@centos8 ~]#pmap 1
[20:35:04 root@centos8 ~]#cat /proc/1/maps
范例:查看系统调用与库调用
#系统调用
[20:36:16 root@centos8 ~]#strace ls
#库调用
[20:37:01 root@centos8 ~]#ltrace ls
2.11 虚拟内存信息vmstat
格式:
vmstat [options] [delay [count]]
显示项说明
procs:
r:可运行(正运行或等待运行)进程的个数,和核心数有关
b:处于不可中断睡眠态的进程个数(被阻塞的队列的长度)
memory:
swpd: 交换内存的使用总量
free:空闲物理内存总量
buffer:用于buffer的内存总量
cache:用于cache的内存总量
swap:
si:从磁盘交换进内存的数据速率(kb/s)
so:从内存交换至磁盘的数据速率(kb/s)
io:
bi:从块设备读入数据到系统的速率(kb/s)
bo: 保存数据至块设备的速率
system:
in: interrupts 中断速率,包括时钟
cs: context switch 进程切换速率
cpu:
us:Time spent running non-kernel code
sy: Time spent running kernel code
id: Time spent idle. Linux 2.5.41前,包括IO-wait time.
wa: Time spent waiting for IO. 2.5.41前,包括in idle.
st: Time stolen from a virtual machine. 2.6.11前, unknown.
选项:
-s 显示内存的统计数据
范例:
[20:39:42 root@centos8 ~]#vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 0 495288 72 276680 0 0 41 27 113 129 3 3 94 0 0
[20:39:46 root@centos8 ~]#vmstat 1 3
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 0 495288 72 276700 0 0 41 27 113 129 3 3 94 0 0
0 0 0 495228 72 276700 0 0 0 0 60 109 0 0 100 0 0
0 0 0 495228 72 276700 0 0 0 0 58 110 0 0 100 0 0
[20:39:54 root@centos8 ~]#vmstat -s
974876 K total memory
202756 K used memory
210360 K active memory
83320 K inactive memory
495348 K free memory
72 K buffer memory
276700 K swap cache
2097148 K total swap
0 K used swap
2097148 K free swap
31561 non-nice user cpu ticks
213 nice user cpu ticks
29939 system cpu ticks
978883 idle cpu ticks
889 IO-wait cpu ticks
1465 IRQ cpu ticks
877 softirq cpu ticks
0 stolen cpu ticks
427309 pages paged in
284609 pages paged out
0 pages swapped in
0 pages swapped out
1182780 interrupts
1347479 CPU context switches
1609753548 boot time
6035 forks
2.12 统计CPU和设备IO信息iostat
iostat 可以提供更丰富的IO性能状态数据
此工具由sysstat包提供
常用选项:
-c 只显示CPU行
-d 显示设备〈磁盘)使用状态
-k 以千字节为为单位显示输出
-t 在输出中包括时间戳
-x 在输出中包括扩展的磁盘指标
范例:
[20:42:19 root@centos8 ~]#iostat 1 3
Linux 4.18.0-193.el8.x86_64 (centos8) 01/04/2021 _x86_64_ (1 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
2.98 0.02 3.06 0.08 0.00 93.85
Device tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 1.63 40.34 26.87 427409 284764
dm-0 1.68 39.25 26.87 415920 284752
dm-1 0.01 0.21 0.00 2220 0
avg-cpu: %user %nice %system %iowait %steal %idle
0.00 0.00 0.00 0.00 0.00 100.00
Device tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 0.00 0.00 0.00 0 0
dm-0 0.00 0.00 0.00 0 0
dm-1 0.00 0.00 0.00 0 0
avg-cpu: %user %nice %system %iowait %steal %idle
0.00 0.00 0.00 0.00 0.00 100.00
Device tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 0.00 0.00 0.00 0 0
dm-0 0.00 0.00 0.00 0 0
dm-1 0.00 0.00 0.00 0 0
tps:该设备每秒的传输次数(Indicate the number of transfers per second that were
issued to the device.)。"一次传输"意思是"一次I/O请求"。多个逻辑请求可能会被合并为"一次I/O
请求"。"一次传输"请求的大小是未知的。
kB_read/s:每秒从设备(drive expressed)读取的数据量;
kB_wrtn/s:每秒向设备(drive expressed)写入的数据量;
kB_read: 读 取 的 总 数 据 量 ;
kB_wrtn:写入的总数量数据量;这些单位都为Kilobytes。
范例:
[20:44:09 root@centos8 ~]#iostat -d sda -x
Linux 4.18.0-193.el8.x86_64 (centos8) 01/04/2021 _x86_64_ (1 CPU)
Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
sda 1.06 0.55 39.92 26.60 0.01 0.08 0.64 12.94 0.94 0.51 0.00 37.62 48.31 0.43 0.07
r/s: 每秒合并后读的请求数w/s: 每秒合并后写的请求数rsec/s:每秒读取的扇区数; wsec/:每秒写入的扇区数。
rKB/s:The number of read requests that were issued to the device per second; wKB/s:The number of write requests that were issued to the device per second; rrqm/s:每秒这个设备相关的读取请求有多少被Merge了(当系统调用需要读取数据的时候,VFS将请求发到 各个FS,如果FS发现不同的读取请求读取的是相同Block的数据,FS会将这个请求合并Merge); wrqm/s:每秒这个设备相关的写入请求有多少被Merge了。
%rrqm: The percentage of read requests merged together before being sent to the device.
%wrqm: The percentage of write requests merged together before being sent to the device.
avgrq-sz 平均请求扇区的大小
avgqu-sz 是平均请求队列的长度。毫无疑问,队列长度越短越好。
await: 每一个IO请求的处理的平均时间(单位是微秒毫秒)。这里可以理解为IO的响应时间,一般地系 统IO响应时间应该低于5ms,如果大于10ms就比较大了。这个时间包括了队列时间和服务时间,也就是说,一 般情况下,await大于svctm,它们的差值越小,则说明队列时间越短,反之差值越大,队列时间越长,说明 系统出了问题。
svctm 表示平均每次设备I/O操作的服务时间(以毫秒为单位)。如果svctm的值与await很接近,表示 几乎没有I/O等待,磁盘性能很好,如果await的值远高于svctm的值,则表示I/O队列等待太长,系统上运 行的应用程序将变慢。
%util: 在统计时间内所有处理IO时间,除以总共统计时间。例如,如果统计间隔1秒,该设备有0.8秒在处理IO,而0.2秒闲置,那么该设备的%util = 0.8/1 = 80%,所以该参数暗示了设备的繁忙程度。一般地,如果该参数是100%表示设备已经接近满负荷运行了(当然如果是多磁盘,即使%util是100%,因为磁盘 的并发能力,所以磁盘使用未必就到了瓶颈)。
2.13 监视磁盘I/O iotop
来自于iotop包
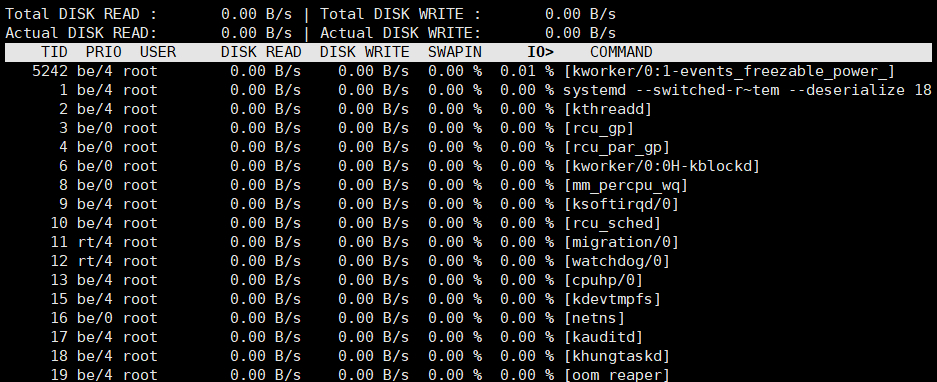
iotop命令是一个用来监视磁盘I/O使用状况的top类工具iotop具有与top相似的UI,其中包括PID、用 户、I/O、进程等相关信息,可查看每个进程是如何使用IO
iotop输出
- 第一行:Read和Write速率总计
- 第二行:实际的Read和Write速率
- 第三行:参数如下:
- 线程ID(按p切换为进程ID)
- 优先级
- 用户
- 磁盘读速率
- 磁盘写速率
- swap交换百分比
- IO等待所占的百分比
iotop常用参数
-o, --only只显示正在产生I/O的进程或线程,除了传参,可以在运行过程中按o生效
-b, --batch非交互模式,一般用来记录日志
-n NUM, --iter=NUM设置监测的次数,默认无限。在非交互模式下很有用
-d SEC, --delay=SEC设置每次监测的间隔,默认1秒,接受非整形数据例如1.1
-p PID, --pid=PID指定监测的进程/线程
-u USER, --user=USER指定监测某个用户产生的I/O
-P, --processes仅显示进程,默认iotop显示所有线程
-a, --accumulated显示累积的I/O,而不是带宽
-k, --kilobytes使用kB单位,而不是对人友好的单位。在非交互模式下,脚本编程有用
-t, --time 加上时间戳,非交互非模式
-q, --quiet 禁止头几行,非交互模式,有三种指定方式
-q 只在第一次监测时显示列名
-qq 永远不显示列名
-qqq 永远不显示I/O汇总
交互按键
left和right方向键:改变排序
r:反向排序
o:切换至选项--only
p:切换至--processes选项
a:切换至--accumulated选项
q:退出
i:改变线程的优先级
2.14 显示网络带宽使用情况iftop
通过EPEL源的iftop包安装
[20:50:46 root@centos8 ~]#iftop -ni eth0

2.15 查看网络实时吞吐量nload
nload 是一个实时监控网络流量和带宽使用情况,以数值和动态图展示进出的流量情况,通过EPEL源安装
界面操作
上下方向键、左右方向键、enter键或者tab键都就可以切换查看多个网卡的流量情况
按 F2 显示选项窗口
按 q 或者 Ctrl+C 退出 nload
范例:
#默认只查看第一个网络的流量进出情况
[20:51:51 root@centos8 ~]#nload
#在nload后面指定网卡,可以指定多个,按左右键分别显示网卡状态
[20:52:51 root@centos8 ~]#nload eth0 eth1
#设置刷新间隔:默认刷新间隔是100毫秒,可通过 -t 命令设置刷新时间(单位是毫秒)
[20:54:19 root@centos8 ~]#nload -t 500 eth0
#设置单位:显示两种单位一种是显示Bit/s、一种是显示Byte/s,默认是以Bit/s,也可不显示/s
#-u h|b|k|m|g|H|B|K|M|G 表示的含义: h: auto, b: Bit/s, k: kBit/s, m: MBit/s, H: auto, B: Byte/s, K: kByte/s, M: MByte/s
[20:54:52 root@centos8 ~]#nload -u M eth0
2.16 网络监视工具iptraf-ng
来自于iptraf-ng包,可以进网络进行监控,对终端窗口大小有要求.图形化操作。
2.17 系统资源统计dstat
dstat由pcp-system-tools包提供,但安装dstat包即可, 可用于代替 vmstat,iostat功能格
格式:
dstat [-afv] [options..] [delay [count]]
常用选项:
-c 显示cpu相关信息
-C #,#,...,total
-d 显示disk相关信息
-D total,sda,sdb,...
-g 显示page相关统计数据
-m 显示memory相关统计数据
-n 显示network相关统计数据
-p 显示process相关统计数据
-r 显示io请求相关的统计数据
-s 显示swapped相关的统计数据
--tcp
--udp
--unix
--raw
--socket
--ipc
--top-cpu:显示最占用CPU的进程
--top-io: 显示最占用io的进程
--top-mem: 显示最占用内存的进程
--top-latency: 显示延迟最大的进程
范例:
[20:58:56 root@centos8 ~]#dstat 1 3

2.18 综合监控工具glances
此工具可以通过EPEL源安装,CentOS 8 目前没有提供(已提供,但测试问题)
格式:
glances [-bdehmnrsvyz1] [-B bind] [-c server] [-C conffile] [-p port] [-P password] [--password] [-t refresh] [-f file] [-o output]
内建命令:

常用选项
-b: 以Byte为单位显示网卡数据速率
-d: 关闭磁盘I/O模块
-f /path/to/somefile: 设定输入文件位置
-o {HTML|CSV}:输出格式
-m: 禁用mount模块
-n: 禁用网络模块
-t #: 延迟时间间隔
-1:每个CPU的相关数据单独显示
C/S模式下运行glances命令
- 服务器模式:
- glances -s -B IPADDR
- IPADDR: 指明监听的本机哪个地址,端口默认为61209/tcp
- glances -s -B IPADDR
- 客户端模式:
- glances -c IPADDR
- IPADDR:要连入的服务器端地址注意: 不同版本不兼容
- glances -c IPADDR
注意: 不同版本不兼容
2.19 查看进程打开文件lsof
lsof:list open files,查看当前系统文件的工具。在linux环境下,一切皆文件,用户通过文件不仅可以访问常规数据,还可以访问网络连接和硬件如传输控制协议 (TCP) 和用户数据报协议 (UDP)套接字等, 系统在后台都为该应用程序分配了一个文件描述符
命令选项:
-a:列出打开文件存在的进程
-c<进程名>:列出指定进程所打开的文件
-g:列出GID号进程详情
-d<文件号>:列出占用该文件号的进程
+d<目录>:列出目录下被打开的文件
+D<目录>:递归列出目录下被打开的文件
-n<目录>:列出使用NFS的文件
-i<条件>:列出符合条件的进程(4、6、协议、:端口、 @ip )
-p<进程号>:列出指定进程号所打开的文件
-u:列出UID号进程详情
-h:显示帮助信息
-v:显示版本信息。
-n: 不反向解析网络名字
范例:
#lsof 列出当前所有打开的文件
[20:59:14 root@centos8 ~]#lsof | head
COMMAND PID TID TASKCMD USER FD TYPE DEVICE SIZE/OFF NODE NAME
systemd 1 root cwd DIR 253,0 244 128 /
systemd 1 root rtd DIR 253,0 244 128 /
systemd 1 root txt REG 253,0 1609264 50745933 /usr/lib/systemd/systemd
systemd 1 root mem REG 253,0 2191808 16963 /usr/lib64/libm-2.28.so
systemd 1 root mem REG 253,0 628744 537890 /usr/lib64/libudev.so.1.6.11
systemd 1 root mem REG 253,0 969832 20530 /usr/lib64/libsepol.so.1
systemd 1 root mem REG 253,0 1805368 76817 /usr/lib64/libunistring.so.2.1.0
systemd 1 root mem REG 253,0 355456 93758 /usr/lib64/libpcap.so.1.9.0
systemd 1 root mem REG 253,0 145984 39813 /usr/lib64/libgpg-error.so.0.24.2
#查看当前那个进程正在使用此文件
[21:05:01 root@centos8 ~]#lsof /var/log/messages
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
rsyslogd 963 root 5w REG 253,0 474858 17000254 /var/log/messages
#查看由登录用户启动而非系统启动的进程
[21:05:17 root@centos8 ~]#lsof /dev/pts/0
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
bash 1363 root 0u CHR 136,0 0t0 3 /dev/pts/0
bash 1363 root 1u CHR 136,0 0t0 3 /dev/pts/0
bash 1363 root 2u CHR 136,0 0t0 3 /dev/pts/0
bash 1363 root 255u CHR 136,0 0t0 3 /dev/pts/0
#指定进程号,可以查看该进程打开的文件
[21:08:15 root@centos8 ~]#lsof -p 3967
#查看程序打开的文件
[21:10:06 root@centos8 ~]#lsof -c bc
#查看指定用户打开的文件
[21:11:07 root@centos8 ~]#lsof -u zhang | more
#查看指定目录下被打开的文件,参数+D为递归列出目录下被打开的文件,参数+d为列出目录下被打开的文件
[21:11:16 root@centos8 ~]#lsof +D /var/log/
[21:11:50 root@centos8 ~]#lsof +d /var/log/
#查看所有网络连接,通过参数-i查看网络连接的情况,包括连接的ip、端口等以及一些服务的连接情况,例 如:sshd等。也可以通过指定ip查看该ip的网络连接情况
[21:12:02 root@centos8 ~]#lsof -i -n
[21:12:38 root@centos8 ~]#lsof -i@127.0.0.1
#查看端口连接情况,通过参数-i:端口可以查看端口的占用情况,-i参数还有查看协议,ip的连接情况等
[21:12:48 root@centos8 ~]#lsof -i :80 -n
#查看指定进程打开的网络连接,参数-i、-a、-p等,-i查看网络连接情况,-a查看存在的进程,-p指定进 程
[21:13:28 root@centos8 ~]#lsof -i -n -a -p 7531
#查看指定状态的网络连接,-n:no host names, -P:no port names,-i TCP指定协议,-s指定协议状态通过多个参数可以清晰的查看网络连接情况、协议连接情况等
[21:14:05 root@centos8 ~]#lsof -n -P -i TCP -s TCP:ESTABLISHED
范例:利用lsof恢复正在使用中的误删除的文件
[21:16:17 root@centos8 ~]#lsof | grep /home/zhang/fstab
[21:16:55 root@centos8 ~]#cat /proc/7812/fd/3
[21:17:02 root@centos8 ~]#cat /proc/7812/fd/3 > /home/zhang/fstab
2.20 综合管理平台 webmin

下载:http://www.webmin.com/download.html
Webmin是目前功能最强大的基于Web的Unix系统管理工具。管理员通过浏览器访问Webmin的各种管 理功能并完成相应的管理动作。目前Webmin支持绝大多数的Unix系统,这些系统除了各种版本的linux 以外还包括:AIX、HPUX、Solaris、Unixware、Irix和FreeBSD等
[09:12:59 root@centos8 ~]#yum install /root/webmin-1.962-1.noarch.rpm
[09:13:20 root@centos8 ~]#chkconfig --list
Note: This output shows SysV services only and does not include native
systemd services. SysV configuration data might be overridden by native
systemd configuration.
If you want to list systemd services use 'systemctl list-unit-files'.
To see services enabled on particular target use
'systemctl list-dependencies [target]'.
webmin 0:off 1:off 2:on 3:on 4:off 5:on 6:off
[09:15:21 root@centos8 ~]#service webmin start
[09:15:39 root@centos8 ~]#ss -ntl
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 0.0.0.0:111 0.0.0.0:*
LISTEN 0 128 0.0.0.0:10000 0.0.0.0:*
LISTEN 0 128 0.0.0.0:22 0.0.0.0:*
LISTEN 0 128 [::]:111 [::]:*
LISTEN 0 128 [::]:22
2.21 Centos8新特性cockpit
由cockpit包提供
Cockpit 是CentOS 8 取入的新特性,是一个基于 Web 界面的应用,它提供了对系统的图形化管理
- 监控系统活动(CPU、内存、磁盘 IO 和网络流量)
- 查看系统日志条目
- 查看磁盘分区的容量
- 查看网络活动(发送和接收) 查看用户帐户
- 检查系统服务的状态提取已安装应用的信息
- 查看和安装可用更新(如果以 root 身份登录)并在需要时重新启动系统
- 打开并使用终端窗口
范例:安装 cockpit
[09:24:24 root@centos8 ~]#dnf install cockpit
[09:25:04 root@centos8 ~]#systemctl start cockpit
[09:25:20 root@centos8 ~]#ss -ntl
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 0.0.0.0:111 0.0.0.0:*
LISTEN 0 128 0.0.0.0:22 0.0.0.0:*
LISTEN 0 128 *:9090 *:*
LISTEN 0 128 [::]:111 [::]:*
LISTEN 0 128 [::]:22 [::]:*
2.22 信号发送kill
kill:内部命令,可用来向进程发送控制信号,以实现对进程管理,每个信号对应一个数字,信号名称以SIG开头(可省略),不区分大小写
显示当前系统可用信号:
[09:25:23 root@centos8 ~]#kill -l
[09:27:54 root@centos8 ~]#trap -l
查看帮助:man 7 signal
常用信号:
1) SIGHUP 无须关闭进程而让其重读配置文件
2) SIGINT 中止正在运行的进程;相当于Ctrl+c
3) SIGQUIT 相当于ctrl+\
4) SIGKILL 强制杀死正在运行的进程
5) SIGTERM 终止正在运行的进程,默认信号
6) SIGCONT 继续运行
7) SIGSTOP 后台休眠
指定信号的方法:
- 信号的数字标识:1, 2, 9
- 信号完整名称:SIGHUP,sighup
- 信号的简写名称:HUP,hup
向进程发送信号:
按PID:
kill [-s sigspec | -n signum | -sigspec] pid | jobspec ... or kill -l [sigspec]
范例:
[09:35:10 root@centos8 ~]#kill -1 9548
[09:37:14 root@centos8 ~]#kill -n 9 11440
[09:41:30 root@centos8 ~]#kill -s SIGINT 11440
按名称:killall 来自于psmisc包
killall [-SIGNAL] comm…
[09:45:12 root@centos8 ~]#killall -n 1 vim
按模式:
pkill [options] pattern
常用选项
-SIGNAL
-u uid: effective user,生效者
-U uid: real user,真正发起运行命令者
-t terminal: 与指定终端相关的进程
-l: 显示进程名(pgrep可用)
-a: 显示完整格式的进程名(pgrep可用)
-P pid: 显示指定进程的子进程
范例:查看HUP信号
#许多服务的支持的reload操作,实际就是发送了HUP信号#service httpd reload 即相当于 killall -1 httpd
[root@centos6 ~]#grep -A 10 -w reload -m 1 /etc/init.d/httpd
reload() {
echo -n $"Reloading $prog: "
if ! LANG=$HTTPD_LANG $httpd $OPTIONS -t >&/dev/null; then
RETVAL=6
echo $"not reloading due to configuration syntax error"
failure $"not reloading $httpd due to configuration syntax error"
else
# Force LSB behaviour from killproc
LSB=1 killproc -p ${pidfile} $httpd -HUP RETVAL=$?
if [ $RETVAL -eq 7 ]; then
[root@centos6 ~]#
范例:利用 0 信号实现进程的健康性检查
[09:45:13 root@centos8 ~]#killall -0 ping
[09:48:48 root@centos8 ~]#echo $?
0
[09:48:53 root@centos8 ~]#killall -0 ping
ping: no process found
[09:49:02 root@centos8 ~]#echo $?
1
#此方式有局限性,即使进程处于停止或僵尸状态,此方式仍然认为是进程是健康的
范例: pkill和pgrep支持正则表达式
[09:51:14 root@centos8 ~]#pkill '^p'
[09:51:47 root@centos8 ~]#pgrep -a '^p'
11993 ping 127.1
2.23 作业管理
Linux的作业控制
- 前台作业:通过终端启动,且启动后一直占据终端
- 后台作业:可通过终端启动,但启动后即转入后台运行(释放终端)
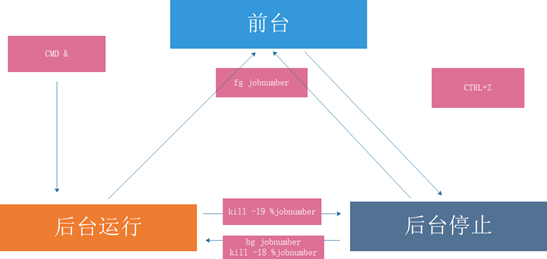
让作业运行于后台
- 运行中的作业: Ctrl+z
- 尚未启动的作业: COMMAND &
后台作业虽然被送往后台运行,但其依然与终端相关;退出终端,将关闭后台作业。如果希望送往后台 后,剥离与终端的关系
- nohup COMMAND &>/dev/null &
- screen;COMMAND tmux;
- COMMAND
查看当前终端所有作业:
[09:54:35 root@centos8 ~]#jobs
[1]+ Stopped ping 127.1
作业控制:
fg [[%]JOB_NUM]:把指定的后台作业调回前台
bg [[%]JOB_NUM]:让送往后台的作业在后台继续运行
kill [%JOB_NUM]: 终止指定的作业
范例:后台运行的进程和终端关系
#终端1运行后台进程
[10:03:30 root@centos8 ~]#ping 127.1 &
#终端2 可以查看到进程
[10:02:59 root@centos8 ~]#ps aux | grep ping
root 12100 0.0 0.2 32424 2248 pts/0 T 10:03 0:00 ping 127.1
root 12105 0.0 0.1 12112 1092 pts/1 R+ 10:04 0:00 grep --color=auto ping
#关闭终端1后,在终端2查看不到进程
[10:04:04 root@centos8 ~]#ps aux | grep ping
root 12108 0.0 0.1 12112 1096 pts/1 R+ 10:04 0:00 grep --color=auto ping
范例:nohup
[10:05:49 root@centos8 ~]#nohup ping 127.1
nohup: ignoring input and appending output to 'nohup.out'
[10:06:42 root@centos8 ~]#tail -f nohup.out
64 bytes from 127.0.0.1: icmp_seq=48 ttl=64 time=0.031 ms
64 bytes from 127.0.0.1: icmp_seq=49 ttl=64 time=0.040 ms
64 bytes from 127.0.0.1: icmp_seq=50 ttl=64 time=0.024 ms
[10:07:15 root@centos8 ~]#nohup ping 127.0.0.1 &>/dev/null &
[1] 12181
[10:07:37 root@centos8 ~]#pstree -p | grep ping
├─sshd(951)─┬─sshd(12112)───sshd(12114)───bash(12115)─┬─ping(12181)
#关闭对应的终端在观察进程的父进程
[10:07:13 root@centos8 ~]#pstree -p
├─ping(12181)
2.24 并行运行
利用后台执行,实现并行功能,即同时运行多个进程,提高效率
方法1
cat all.sh
f1.sh&
f2.sh&
f3.sh&
方法2
(f1.sh&);(f2.sh&);(f3.sh&)
方法3
f1.sh&f2.sh&f3.sh&
范例:多组命令实现并行
[root@centos8 ~]#{ ping -c3 127.1; ping 127.2; }& { ping -c3 127.3 ;ping 127.4;}&
范例:
NET=192.168.10
for i in {1..254};do
{
ping -c1 -W1 $NET.$i &>/dev/null && echo $NET.$i is up || echo $NET.$i is down
}&
done
wait
使用并行可以加快网段扫描速度,wait命令的意思是后台运行结束后自动退出
2.25 watch对命令实时监控
使用watch实用程序执行重复的输出以实现对就程进行实时的监视,如下面的命令显示每秒钟的监视
[19:58:12 root@centos8 ~]#watch -n 1 'ps -eo pid,ppid,cmd,%mem,%cpu --sort=-%mem | head
三、任务计划
通过任务计划,可以让系统自动的按时间或周期性任务执行任务
注意: 学习本节需要实现邮件通知,学习内容前必须安装并启动邮件服务
范例:环境准备
[root@centos8 ~]#yum -y install postfix
[root@centos8 ~]#systemctl enable --now postfix
未来的某时间点执行一次任务
- at 指定时间点,执行一次任务
- batch 系统自行选择空闲时间去执行此处指定的任务
周期性运行某任务
- cron
3.1 一次性任务
at工具
- 由包at提供
- 依赖与atd服务,需要启动才能实现at任务
- at队列存放在/var/spool/at目录中,ubuntu存放在/var/spool/cron/atjobs目录下
- 执行任务时PATH变量的值和当前定义任务的用户身份一致
at 命令:
at [option] TIME
常用选项:
-V 显示版本信息
-t time 时间格式[[CC]YY]MMDDhhmm[.ss]
-l 列出指定队列中等待运行的作业;相当于atq
-d N 删除指定的N号作业;相当于atrm
-c N 查看具体作业N号任务
-f file 指定的文件中读取任务
-m 当任务被完成之后,将给用户发送邮件,即使没有标准输出
注意:
- 作业执行命令的结果中的标准输出和错误以执行任务的用户身份发邮件通知给 root
- 默认CentOS 8 最小化安装没有安装邮件服务,需要自行安装
TIME:定义出什么时候进行 at 这项任务的时间
HH:MM [YYYY-mm-dd]
noon, midnight, teatime(4pm),tomorrow
now+#{minutes,hours,days, OR weeks}
范例:at 时间格式
HH:MM 在今日的 HH:MM 进行,若该时刻已过,则明天此时执行任务
02:00
HH:MM YYYY-MM-DD 规定在某年某月的某一天的特殊时刻进行该项任务
02:00 2016-09-20
HH:MM[am|pm] [Month] [Date]
06pm March 17
17:20 tomorrow
HH:MM[am|pm] + number [minutes|hours|days|weeks], 在某个时间点再加几个时间后才进行该项任务
now + 5 min
02pm + 3 days
at 任务执行方式:
- 交互式
- 输入重定向
- at -f file
/etc/at.{allow,deny} 控制用户是否能执行at任务
- 白名单:/etc/at.allow 默认不存在,只有该文件中的用户才能执行at命令
- 黑名单:/etc/at.deny 默认存在,拒绝该文件中用户执行at命令,而没有在at.deny 文件中的使用者则可执行
- 如果两个文件都不存在,只有 root 可以执行 at 命令
范例: ubuntu at任务存放路径
[root@ubuntu2004 ~]#ll /var/spool/cron/
[root@ubuntu2004 ~]#ll /var/spool/cron/atjobs/
3.2 周期性任务计划cron
周期性任务计划cron相关的程序包:
- cronie:主程序包,提供crond守护进程及相关辅助工具
- crontabs:包含CentOS提供系统维护任务
- cronie-anacron:cronie的补充程序,用于监控cronie任务执行状况,如:cronie中的任务在过去该运行的时间点未能正常运行,则anacron会随后启动一次此任务
cron 依赖于crond服务,确保crond守护处于运行状态:
#CentOS 7 以 后 版 本 :
systemctl status crond
#CentOS 6:
service crond status
cron任务分为
- 系统cron任务:系统维护作业,/etc/crontab 主配置文件, /etc/cron.d/ 子配置文件
- 用户cron任务:保存在 /var/spool/cron/USERNAME(ubuntu 系统存放在/var/spool/cron/crontabs/USERNAME),利用 crontab 命令管理
计划任务日志:/var/log/cron
3.2.1 系统cron计划任务
/etc/crontab 格式说明,详情参见 man 5 crontab
注释行以 # 开头
[14:36:58 root@centos8 ~]#cat /etc/crontab
SHELL=/bin/bash
PATH=/sbin:/bin:/usr/sbin:/usr/bin
MAILTO=root
# For details see man 4 crontabs
# Example of job definition:
# .---------------- minute (0 - 59)
# | .------------- hour (0 - 23)
# | | .---------- day of month (1 - 31)
# | | | .------- month (1 - 12) OR jan,feb,mar,apr ...
# | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat
# | | | | |
# * * * * * user-name command to be executed
计划任务时间表示法:
(1) 特定值
给定时间点有效取值范围内的值
(2) *
给定时间点上有效取值范围内的所有值,表示“每...”,放在星期的位置表示不确定
(3) 离散取值
#,#,#
(4) 连续取值
#-#
(5) 在指定时间范围上,定义步长
/#: #即为步长
(6) 特定关健字
@yearly 0 0 1 1 *
@annually 0 0 1 1 *
@monthly 0 0 1 * *
@weekly 0 0 * * 0
@daily 0 0 * * *
@hourly 0 * * * *
@reboot Run once after reboot
范例:每个月日期和星期几字段的关系
星期几如果和日期冲突它俩的关系为或者,其余的关系都为并且
[root@centos8 ~]#man 5 crontab
范例:
#晚上9点10分运行echo命令,输出信息仍会发送到root 邮箱
10 21 * * * wang /bin/echo "Howdy!"
#每3小时echo和wall命令
0 */3 * * * wang /bin/echo “howdy”; wall “welcome to Magedu!”
crond任务相关文件:
/etc/crontab 配置文件
/etc/cron.d/ 配置文件
/etc/cron.hourly/ 脚本
/etc/cron.daily/ 脚本
/etc/cron.weekly/ 脚本
/etc/cron.monthly/ 脚本
3.2.2 anacron
运行计算机关机时cron不运行的任务,CentOS6以后版本取消anacron服务,由crond服务管理,对笔 记本电脑、台式机、工作站、偶尔要关机的服务器及其它不一直开机的系统很重要对很有用
由/etc/cron.hourly/0anacron执行,当执行任务时,更新/var/spool/anacron/cron.daily 文件的时间戳
配置文件:/etc/anacrontab,负责执行/etc/ cron.daily /etc/cron.weekly /etc/cron.monthly中系统任务
/etc/anacrontab格式说明
字段1:如果在这些日子里没有运行这些任务……
字段2:在重新引导后等待这么多分钟后运行它
字段3:任务识别器,在日志文件中标识
字段4:要执行的任务
3.2.3 管理临时文件
CentOS 7 使用 systemd-tmpfiles-setup服务实现
CentOS 6 使用/etc/cron.daily/tmpwatch定时清除临时文件
配置文件:
/etc/tmpfiles.d/*.conf
/run/tmpfiles.d/*.conf
/usr/lib/tmpfiles/*.conf
/usr/lib/tmpfiles.d/tmp.conf
d /tmp 1777 root root 10d
d /var/tmp 1777 root root 30d
命令:
systemd-tmpfiles –clean|remove|create configfile
3.2.4 用户计划任务
crontab命令:
- 每个用户都有专用的cron任务文件:/var/spool/cron/USERNAME
- 默认标准输出和错误会被发邮件给对应的用户,如:wang创建的任务就发送至wang的邮箱
- root能够修改其它用户的作业
- 用户的cron 中默认 PATH=/usr/bin:/bin,如果使用其它路径,在任务文件的第一行加PATH=/path或者加入到计划任务执行的脚本中
- 第六个字段指定要运行的命令。 该行的整个命令部分,直至换行符或“%”字符,指定的shell执行. 除非使用反斜杠(\)进行转义,否则该命令中的“%”字符将变为换行符,并且第一个%之后的所 有数据将作为标准输入发送到该命令。
crontab命令格式:
crontab [-u user] [-l | -r | -e] [-i]
常用选项:
-l 列出所有任务
-e 编辑任务
-r 移除所有任务
-i 同-r一同使用,以交互式模式移除指定任务
-u user 指定用户管理cron任务,仅root可运行
控制用户执行计划任务:
/etc/cron.{allow,deny}
范例:修改默认的cron的文本编辑工具
root@ubuntu1804:~# crontab -e
no crontab for root - using an empty one
Select an editor. To change later, run 'select-editor'.
1. /bin/nano <----- easiest
2. /usr/bin/vim.basic
3. /usr/bin/vim.tiny
4. /bin/ed
Choose 1-4 [1]:
root@ubuntu1804:~# cat /etc/profile.d/env.sh
export EDITOR=vim
范例:PATH变量
#方法1,在计划任务配置中指定PATH
[root@centos8 ~]#crontab -l
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
* * * * * useradd hehe;echo $PATH
#方法2,在脚本中指定PATH变量
[root@centos8 ~]#crontab -l
* * * * * /data/test.sh
[root@centos8 ~]#cat /data/test.sh
#!/bin/bash
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
useradd hehe
echo $PATH
面试题:11月每天的6-12点之间每隔2小时执行/app/bin/test.sh
[root@centos8 ~]#crontab -l
0 6-12/2 * 11 * /app/bin/test.sh
注意:运行结果的标准输出和错误以邮件通知给相关用户
(1) COMMAND > /dev/null
(2) COMMAND &> /dev/null
cron任务中不建议使用%,它有特殊用途,它表示换行的特殊意义,且第一个%后的所有字符串会被将成当作命令的标准输入,如果在命令中要使用%,则需要用 \ 转义
注意:将%放置于单引号中是不支持的
范例: 在crontab中%的用法
30 2 * * * /bin/cp -a /etc/ /data/etc`date +\%F_\%T`
30 2 * * * /bin/cp -a /etc/ /data/etc`date +‘%F_%T’` 有问题
范例: 在crontab中%的用法
[root@centos8 ~]#crontab -l
* * * * * mail -s "test" wang%wang,%%how are you?%
[root@centos8 ~]# cat /var/spool/mail/wang
From root@centos8.localdomain Sat Jul 4 23:58:01 2020
Return-Path:
X-Original-To: wang
Delivered-To: wang@centos8.localdomain
Received: by centos8.localdomain (Postfix, from userid 0)
id 0B03860272; Sat, 4 Jul 2020 23:58:01 +0800 (CST)
Date: Sat, 04 Jul 2020 23:58:01 +0800
To: wang@centos8.localdomain
Subject: test
User-Agent: Heirloom mailx 12.5 7/5/10
MIME-Version: 1.0
Content-Type: text/plain; charset=us-ascii
Content-Transfer-Encoding: 7bit
Message-Id: <20200704155801.0B03860272@centos8.localdomain>
From: root@centos8.localdomain (root)
wang,
how are you?
[root@centos8 ~]#
思考:
如何在秒级别运行任务?
for min in 0 1 2; do echo "hi"; sleep 20; done
如何实现每7分钟运行一次任务?
sleep命令:
sleep NUMBER[SUFFIX]...
SUFFIX:
s: 秒, 默认
m: 分
h: 小时
d: 天
范例:
[11:01:57 root@centos8 ~]#usleep
warning: usleep is deprecated, and will be removed in near future!
warning: use "sleep 1e-06" instead...
范例:
[10:31:58 root@centos8 ~]#time usleep 1000000
warning: usleep is deprecated, and will be removed in near future!
warning: use "sleep 1" instead...
real 0m1.014s
user 0m0.001s
sys 0m0.001s
[11:01:37 root@centos8 ~]#time ls
1.sh nohup.out scanhost.sh webmin-1.962-1.noarch.rpm
real 0m0.003s
user 0m0.001s
sys 0m0.001s
[11:01:47 root@centos8 ~]#time sleep 0.2
real 0m0.302s
user 0m0.002s
sys 0m0.001s
练习:
- 每周的工作日1:30,将/etc备份至/backup目录中,保存的文件名称格式为“etcbak-yyyy-mm-dd- HH.tar.xz”,其中日期是前一天的时间
[13:57:19 root@centos8 ~]#cat back-etc.sh
#!/bin/bash
#
#********************************************************************
#Author:zhangzhuo
#QQ: 1191400158
#Date: 2021-01-05
#FileName:back-etc.sh
#URL: https://www.zhangzhuo.ltd
#Description:The test script
#Copyright (C): 2021 All rights reserved
#********************************************************************
DIR=/etc
BACKDIR=/backup/etcbak-`date -d '-1 days' +%F-%H-%M-%S`
{
tar Jcvf $BACKDIR.tar.xz $DIR &>/dev/null
}&
[13:53:42 root@centos8 backup]#crontab -l
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin
30 1 * * 1-5 /root/back-etc.sh
- 每两小时取出当前系统/proc/meminfo文件中以S或M开头的信息追加至/tmp/meminfo.txt文件中
[14:01:21 root@centos8 ~]#crontab -l
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin
0 */2 * * * grep -E '^S|^M' /proc/meminfo >> /tmp/meminfo.txt
- 工作日时间,每10分钟执行一次磁盘空间检查,一旦发现任何分区利用率高于80%,就执行wall警报
[14:22:07 root@centos8 ~]#cat diskwall.sh
#!/bin/bash
#
#********************************************************************
#Author:zhangzhuo
#QQ: 1191400158
#Date: 2020-01-05
#FileName:diskwall.sh
#URL: https://www.zhangzhuo.ltd
#Description:The test script
#Copyright (C): 2020 All rights reserved
#********************************************************************
df | sed -rn '/^\/dev/s@([^ ]*) .* ([0-9]+)%.*@\1 \2@p'| while read disk per;do
if [ $per -gt 80 ];then
echo Wall `hostname -I` host $disk disk the absence | mail -s "Wall" 1191400158@qq.com
fi
done
[14:22:26 root@centos8 ~]#crontab -l
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin
30 1 * * 1-5 /root/back-etc.sh
0 */2 * * * grep -E '^S|^M' /proc/meminfo >> /tmp/meminfo.txt
*/10 * * * * /root/diskwall.sh