

一、关系型数据库理论
1.1 实体-联系模型E-R
- 实体Entity:客观存在并可以相互区分的客观事物或抽象事件称为实体,在E-R图中用矩形框表示实体,把实体名写在框内
- 属性:实体所具有的特征或性质
- 联系:联系是数据之间的关联集合,是客观存在的应用语义链
- 实体内部的联系:指组成实体的各属性之间的联系。如职工实体中,职工号和部门经理号之有一种关联关系
- 实体之间的联系:指不同实体之间联系。例:学生选课实体和学生基本信息实体之间
- 实体之间的联系用菱形框表示
1.2 联系类型
- 一对一联系(1:1)
- 一对多联系(1:n):外键
- 多对多联系(m:n):增加第三张表
1.3 数据的操作
开发工程师 CURD (Create,Update,Read,Delete)
- 数据提取:在数据集合中提取感兴趣的内容。SELECT
- 数据更新:变更数据库中的数据。INSERT、DELETE、UPDATE
1.4 数据库规划流程
-
收集数据,得到字段
- 收集必要且完整的数据项
- 转换成数据表的字段
-
把字段分类,归入表,建立表的关联
- 关联:表和表间的关系
- 分割数据表并建立关联的优点
- 节省空间
- 减少输入错误
- 方便数据修改
- 规范化数据库
1.5.1 第一范式:1NF
无重复的列,每一列都是不可分割的基本数据项,同一列中不能有多个值,即实体中的某个属性不能有多个值或者不能有重复的属性,确保每一列的原子性。除去同类型的字段,就是无重复的列说明:第一范式(1NF)是对关系模式的基本要求,不满足第一范式(1NF)的数据库就不是关系数据库
1.5.2 第二范式:2NF
第二范式必须先满足第一范式,属性完全依赖于主键,要求表中的每个行必须可以被唯一地区分,通常为表加上每行的唯一标识PK,非PK的字段需要与整个PK有直接相关性,即非PK的字段不能依赖于部分主键
1.5.3 第三范式:3NF
满足第三范式必须先满足第二范式属性,非主键属性不依赖于其它非主键属性。第三范式要求一个数据表中不包含已在其它表中已包含的非主关键字信息,非PK的字段间不能有从属关系
1.6 SQL 结构化查询语言简介
SQL:Structure Query Language,结构化查询语言是1974年由Boyce和Chamberlin提出的一个通用的、功能极强的关系性数据库语言
SQL解释器:将SQL语句解释成机器语言
数据存储协议:应用层协议,C/S
- S:server, 监听于套接字,接收并处理客户端的应用请求
- C:Client
客户端程序接口
- CLI
- GUI
应用编程接口
- ODBC:Open Database Connectivity
- JDBC:Java Data Base Connectivity
1.7 SQL 基本概念
- 约束:constraint,表中的数据要遵守的限制
- 主键:一个或多个字段的组合,填入的数据必须能在本表中唯一标识本行;必须提供数据,即NOT NULL,一个表只能有一个
- 唯一键:一个或多个字段的组合,填入的数据必须能在本表中唯一标识本行;允许为NULL,一个表可以存在多个
- 外键:一个表中的某字段可填入的数据取决于另一个表的主键或唯一键已有的数据
- 检查:字段值在一定范围内
- 索引:将表中的一个或多个字段中的数据复制一份另存,并且按特定次序排序存储
1.8 关系运算
- 选择:挑选出符合条件的行
- 投影:挑选出需要的字段
- 连接:表间字段的关联
1.9 数据抽象
- 物理层:数据存储格式,即RDBMS在磁盘上如何组织文件
- 逻辑层:DBA角度,描述存储什么数据,以及数据间存在什么样的关系
- 视图层:用户角度,描述DB中的部分数据
1.10 关系模型的分类
- 关系模型
- 基于对象的关系模型
- 半结构化的关系模型:XML数据
二、MySQL安装和基本使用
2.1 MySQL 介绍
2.1.1 MySQL 历史
1979年:TcX公司 Monty Widenius,Unireg
1996年:发布MySQL1.0,Solaris版本,Linux版本
1999年:MySQL AB公司,瑞典
2003年:MySQL 5.0版本,提供视图、存储过程等功能
2008年:Sun公司 以10亿美元收购MySQL
2009年:Oracle公司以 75 亿美元收购 sun 公司
2009年:Monty成立MariaDB
2.2.2 MySQL系列
2.2.2.1 MySQL 的三大主要分支
- mysql
- mariadb
- percona Server
2.2.2.2 官方网址
2.2.2.3 官方文档
https://www.percona.com/software/mysql-database/percona-server
2.2.2.4 版本演变
MySQL:5.1 --> 5.5 --> 5.6 --> 5.7 -->8.0
MariaDB:5.1 -->5.5 -->10.0--> 10.1 --> 10.2 --> 10.3 --> 10.4 --> 10.5
MySQL被Sun收购后,搞了个过渡的6.0版本,没多久就下线了,后来被Oracle收购后,终于迎来了像样的5.6版本,之后就是5.7、8.0版本。由于6.0版本号已被用过,7.x系列版本专用于NDB Cluster,因而新版本号从8.0开始。
2.2.3 MySQL的特性
- 开源免费
- 插件式存储引擎:也称为“表类型”,存储管理器有多种实现版本,功能和特性可能均略有差别;用户可根据需要灵活选择,Mysql5.5.5开始innoDB引擎是MYSQL默认引擎
MyISAM ==> Aria
InnoDB ==> XtraDB
- 单进程,多线程
#判断多线程
[09:57:23 root@centos8 ~]#grep -i threads /proc/1074/status
Threads: 39
- 诸多扩展和新特性
- 提供了较多测试组件
2.2 MySQL 安装方式介绍和快速安装
2.2.1 安装方式介绍
- 程序包管理器管理的程序包
- 源代码编译安装
- 二进制格式的程序包:展开至特定路径,并经过简单配置后即可使用
2.2.2 RPM包安装MySQL
CentOS 安装光盘
项目官方:https://downloads.mariadb.org/mariadb/repositories/
国内镜像:https://mirrors.tuna.tsinghua.edu.cn/mariadb/yum/
https://mirrors.tuna.tsinghua.edu.cn/mysql/yum/
CentOS 8:安装光盘直接提供
- mysql-server:8.0
- mariadb-server : 10.3.17
CentOS 7:安装光盘直接提供
- mariadb-server:5.5 服务器包
- mariadb 客户端工具包
CentOS 6:
- mysql-server:5.1 服务器包
- mysql 客户端工具包
范例: CentOS 7 安装MySQL5.7
[10:54:25 root@centos7 ~]#cat /etc/yum.repos.d/mysql57.repo
[mysql57]
name=mysql57
baseurl=https://mirrors.tuna.tsinghua.edu.cn/mysql/yum/mysql-5.7-community-el7-x86_64/
gpgcheck=0
[10:55:08 root@centos7 ~]#yum list | grep mysql57
mysql-community-client.i686 5.7.33-1.el7 mysql57
mysql-community-client.x86_64 5.7.33-1.el7 mysql57
mysql-community-common.i686 5.7.33-1.el7 mysql57
mysql-community-common.x86_64 5.7.33-1.el7 mysql57
mysql-community-devel.i686 5.7.33-1.el7 mysql57
mysql-community-devel.x86_64 5.7.33-1.el7 mysql57
mysql-community-embedded.i686 5.7.33-1.el7 mysql57
mysql-community-embedded.x86_64 5.7.33-1.el7 mysql57
mysql-community-embedded-compat.i686 5.7.33-1.el7 mysql57
mysql-community-embedded-compat.x86_64 5.7.33-1.el7 mysql57
mysql-community-embedded-devel.i686 5.7.33-1.el7 mysql57
mysql-community-embedded-devel.x86_64 5.7.33-1.el7 mysql57
mysql-community-libs.i686 5.7.33-1.el7 mysql57
mysql-community-libs.x86_64 5.7.33-1.el7 mysql57
mysql-community-libs-compat.i686 5.7.33-1.el7 mysql57
mysql-community-libs-compat.x86_64 5.7.33-1.el7 mysql57
mysql-community-server.x86_64 5.7.33-1.el7 mysql57
mysql-community-test.x86_64 5.7.33-1.el7 mysql57
[10:55:17 root@centos7 ~]#yum install mysql-community-server -y
[11:00:53 root@centos7 ~]#systemctl enable --now mysqld
[11:04:08 root@centos7 ~]#ss -ntl
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 *:111 *:*
LISTEN 0 128 *:22 *:*
LISTEN 0 100 127.0.0.1:25 *:*
LISTEN 0 80 [::]:3306 [::]:*
LISTEN 0 128 [::]:111 [::]:*
LISTEN 0 128 [::]:22 [::]:*
LISTEN 0 100 [::1]:25 [::]:*
[11:04:26 root@centos7 ~]#mysql
ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: NO)
[11:05:15 root@centos7 ~]#grep password /var/log/mysqld.log
2021-01-28T03:04:05.376619Z 1 [Note] A temporary password is generated for root@localhost: j9eNwN#IsToD
2021-01-28T03:05:15.225574Z 2 [Note] Access denied for user 'root'@'localhost' (using password: NO)
#修改初始密码方法1
[11:37:14 root@centos7 ~]#mysql -uroot -p'j9eNwN#IsToD'
mysql> alter user root@'localhost' identified by 'Zhangzhuo@0705';
Query OK, 0 rows affected (0.00 sec)
mysql> status
#修改初始密码方法2
[11:38:28 root@centos7 ~]#mysqladmin -uroot -p'j9eNwN#IsToD' password 'Zhangzhuo@0705'
范例:centos7安装Mariadb
[11:42:44 root@centos7 ~]#cat /etc/yum.repos.d/mariadb.repo
[mariadb105]
name=mariadb105
baseurl=https://mirrors.tuna.tsinghua.edu.cn/mariadb/yum/10.5/centos/7/x86_64/
gpgcheck=0
[11:47:06 root@centos7 ~]#yum install -y MariaDB-server
[11:47:43 root@centos7 ~]#systemctl enable --now mariadb.service
[11:48:08 root@centos7 ~]#mysql
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 3
Server version: 10.5.8-MariaDB MariaDB Server
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [(none)]> status
------------------------
mysql Ver 15.1 Distrib 10.5.8-MariaDB, for Linux (x86_64) using readline 5.1
Connection id: 3
Current database:
Current user: root@localhost
SSL: Not in use
Current pager: stdout
Using outfile: ''
Using delimiter: ;
Server: MariaDB
Server version: 10.5.8-MariaDB MariaDB Server
Protocol version: 10
Connection: Localhost via UNIX socket
Server characterset: latin1
Db characterset: latin1
Client characterset: utf8
Conn. characterset: utf8
UNIX socket: /var/lib/mysql/mysql.sock
Uptime: 18 sec
Threads: 2 Questions: 4 Slow queries: 0 Opens: 16 Open tables: 10 Queries per second avg: 0.222
2.3 初始化脚本提高安全性
运行脚本:mysql_secure_installation
设置数据库管理员root口令
禁止root远程登录
删除anonymous用户帐号
删除test数据库
2.4 MYSQL组成
2.4.1 客户端程序
- mysql: 交互式或非交互式的CLI工具
- mysqldump:备份工具,基于mysql协议向mysqld发起查询请求,并将查得的所有数据转换成insert等写操作语句保存文本文件中
- mysqladmin:基于mysql协议管理mysqld
- mysqlimport:数据导入工具
MyISAM存储引擎的管理工具:
- myisamchk:检查MyISAM库
- myisampack:打包MyISAM表,只读
2.4.2 服务器端程序
- mysqld_safe
- mysqld
- mysqld_multi 多实例 ,示例:mysqld_multi --example
2.4.3 用户账号
mysql用户账号由两部分组成:
'USERNAME'@'HOST'
说明:
HOST限制此用户可通过哪些远程主机连接mysql服务器
支持使用通配符:
% 匹配任意长度的任意字符,相当于shell中*, 示例: 172.16.0.0/255.255.0.0 或 172.16.%.%
_ 匹配任意单个字符,相当于shell中?
2.4.4 mysql 客户端命令
2.4.4.1 mysql 运行命令类型
- 客户端命令:本地执行,每个命令都完整形式和简写格式
mysql> \h, help
mysql> \u,use
mysql> \s,status
mysql> \!,system
- 服务端命令:通过mysql协议发往服务器执行并取回结果,命令末尾都必须使用命令结束符号,默认为分号
#示例:
mysql>SELECT VERSION();
2.4.4.2 mysql 使用模式
- 交互模式
- 脚本模式:
mysql -uUSERNAME -pPASSWORD < /path/somefile.sql
cat /path/somefile.sql | mysql -uUSERNAME -pPASSWORD
mysql>source /path/from/somefile.sql
2.4.4.3 mysql命令使用格式
mysql [OPTIONS] [database]
mysql客户端常用选项:
-A, --no-auto-rehash 禁止补全
-u, --user= 用户名,默认为root
-h, --host= 服务器主机,默认为localhost
-p, --passowrd= 用户密码,建议使用-p,默认为空密码
-P, --port= 服务器端口
-S, --socket= 指定连接socket文件路径
-D, --database= 指定默认数据库
-C, --compress 启用压缩
-e “SQL“ 执行SQL命令
-V, --version 显示版本
-v --verbose 显示详细信息
--print-defaults 获取程序默认使用的配置
登录系统:
[11:50:57 root@centos7 ~]#mysql -uroot -p123456 #默认不写空密码
运行mysql命令:
mysql>use mysql
mysql> select user();
mysql>SELECT User,Host,Password FROM user;
范例:mysql的配置文件,修改提示符
[12:30:27 root@centos7 ~]#vim /etc/my.cnf
#添加这行
[mysql]
prompt="\\r:\\m:\\s(\\u@\\h) [\\d]>\\_"
[12:30:27 root@centos7 ~]#mysql -uroot -p'Zhangzhuo@0705'
12:31:06(root@localhost) [(none)]>
范例:配置所有MySQL客户端自动登录
[12:35:05 root@centos7 ~]#vim /etc/my.cnf
[client]
user=root
password=Zhangzhuo@0705
2.4.4.4 mysqladmin命令
mysqladmin 命令格式
mysqladmin [OPTIONS] command command....
范例:
#查看mysql服务是否正常,如果正常提示mysqld is alive
[12:36:10 root@centos7 ~]#mysqladmin -uroot -p'Zhangzhuo@0705' ping
mysqladmin: [Warning] Using a password on the command line interface can be insecure.
mysqld is alive
#关闭mysql服务,但mysqladmin命令无法开启
[12:36:30 root@centos7 ~]#mysqladmin -uroot -p'Zhangzhuo@0705' shutdown
#创建数据库testdb
[12:37:39 root@centos7 ~]#mysqladmin -uroot -p'Zhangzhuo@0705' create testdb
#删除数据库testdb
[12:38:21 root@centos7 ~]#mysqladmin -uroot -p'Zhangzhuo@0705' drop testdb
#修改root密码
[12:39:26 root@centos7 ~]#mysqladmin -uroot -p'Zhangzhuo@0705' password 'Admin@123'
#日志滚动,生成新文件/var/lib/mysql/mariadb-bin.00000N
[12:39:33 root@centos7 ~]#mysqladmin -uroot -p'Admin@123' flush-logs
2.4.4.5 服务器端配置
服务器端(mysqld):工作特性有多种配置方式
- 命令行选项:
- 配置文件:类ini格式,集中式的配置,能够为mysql的各应用程序提供配置信息
服务器端配置文件:
- /etc/my.cnf #Global选项
- /etc/mysql/my.cnf #Global选项
- ~/.my.cnf #User-specific 选项
配置文件格式:
- [mysqld]
- [mysqld_safe]
- [mysqld_multi]
- [mysql]
- [mysqldump]
- [server]
- [client]
格式:
parameter = value
说明:
_和- 相同
1,ON,TRUE意义相同, 0,OFF,FALSE意义相同,无区分大小写
2.4.4.6 socket地址
服务器监听的两种 socket 地址:
- ip socket: 监听在tcp的3306端口,支持远程通信 ,侦听3306/tcp端口可以在绑定有一个或全部接口IP上
- unix sock: 监听在sock文件上,仅支持本机通信, 如:/var/lib/mysql/mysql.sock)说明:host为localhost 时自动使用unix sock
2.4.4.7 关闭mysqld网络连接
只侦听本地客户端, 所有客户端和服务器的交互都通过一个socket文件实现,socket的配置存放
在/var/lib/mysql/mysql.sock) 可在/etc/my.cnf修改
范例:
vim /etc/my.cnf
[mysqld]
skip-networking=1 #表示关闭网络连接1关闭0开启
bind_address=127.0.0.1 #绑定端口
2.5 通用二进制格式安装 MySQL
2.5.1 准备用户
[12:48:56 root@centos7 ~]#useradd -r -s /sbin/nologin -d /data/mysql mysql
2.5.2 准备数据目录,建议使用逻辑卷
#可选做,后面的脚本mysql_install_db可自动生成此目录
[12:50:20 root@centos7 ~]#mkdir -p /data/mysql
[12:50:24 root@centos7 ~]#chown mysql: /data/mysql/
2.5.3 准备二进制程序
[13:56:35 root@centos7 ~]#tar xvf mysql-5.6.50-linux-glibc2.12-x86_64.tar.gz -C /usr/local/
[13:56:35 root@centos7 ~]#cd /usr/local/
[13:57:43 root@centos7 local]#ln -sv mysql-5.6.50-linux-glibc2.12-x86_64 mysql
[13:58:14 root@centos7 local]#chown -R root: /usr/local/mysql
2.5.4 准备配置文件
[14:16:18 root@centos7 mysql]#cd /usr/local/mysql
[14:16:20 root@centos7 mysql]#cp -d support-files/my-default.cnf /etc/my.cnf
[14:17:54 root@centos7 mysql]#vim /etc/my.cnf
[mysqld]
datadir = /data/mysql
innodb_file_per_table = on #在mariadb5.5以上版的是默认值,可不加
skip_name_resolve = no #禁止主机名解析,建议使用
2.5.5 创建数据库文件
[14:21:09 root@centos7 mysql]#./scripts/mysql_install_db --datadir=/data/mysql --user=mysql
[14:28:12 root@centos7 mysql]#ls /data/mysql/ -l
total 110600
-rw-rw---- 1 mysql mysql 12582912 Jan 28 14:28 ibdata1
-rw-rw---- 1 mysql mysql 50331648 Jan 28 14:28 ib_logfile0
-rw-rw---- 1 mysql mysql 50331648 Jan 28 14:28 ib_logfile1
drwx------ 2 mysql mysql 4096 Jan 28 14:28 mysql
drwx------ 2 mysql mysql 4096 Jan 28 14:28 performance_schema
drwx------ 2 mysql mysql 6 Jan 28 14:27 test
2.5.6 准备服务脚本,并启动服务
[14:28:17 root@centos7 mysql]#cp /usr/local/mysql/support-files/mysql.server /etc/init.d/mysqld
[14:28:58 root@centos7 mysql]#chkconfig --add mysqld
[14:29:22 root@centos7 mysql]#service mysqld start
#如果有对应的service 文件可以执行下面
cp /usr/local/mysql/support-files/systemd/mariadb.service
/usr/lib/systemd/system/
systemctl daemon-reload
systemctl enable --now mariadb
2.5.7 PATH路径
[14:30:50 root@centos7 mysql]#echo 'PATH=/usr/local/mysql/bin:$PATH' >/etc/profile.d/mysql.sh
[14:32:09 root@centos7 mysql]#. /etc/profile.d/mysql.sh
2.5.8 安全初始化
[14:34:03 root@centos7 mysql]#mysql_secure_installation
2.6 实战案例:一键安装mysql-5.6二进制包的脚本
2.6.1 离线安装mysql-5.6二进制包的脚本
#!/bin/bash
#
#********************************************************************
#Author:zhangzhuo
#QQ: 1191400158
#Date: 2021-01-28
#FileName:install_mysql5.6.sh
#URL: https://www.zhangzhuo.ltd
#Description:The test script
#Copyright (C): 2021 All rights reserved
#********************************************************************
NAME=$1
NAME=`echo $NAME | grep -Eo '[^/]+$'`
DIRNAME=`echo $NAME | sed -rn 's/(.*).tar.*/\1/p'`
DIR=/usr/local
DATADIR=/data/mysql
install_mysql_user(){
if id mysql &>/dev/null;then
echo "MYSQL用户已经存在,无需从新创建!"
else
useradd -r -s /sbin/nologin -d $DATADIR mysql
fi
}
install_mysql_datadir(){
if [ -d $DATADIR ];then
echo "${DATADIR}目录已经存在,无需从新创建!"
else
mkdir -p $DATADIR
chown mysql: $DATADIR
fi
}
install_mysql_my(){
cat /etc/profile.d/mysql.sh
. /etc/profile.d/mysql.sh
cp $DIR/mysql/support-files/mysql.server /etc/init.d/mysqld
chkconfig --add mysqld
service mysqld start
else
echo -e "\033[1;31m二进制文件不存在请检查\033[0m";exit
fi
}
install_mysql_user
install_mysql_datadir
install_mysql
2.6.2 在线安装mysql-5.6二进制包的脚本
#!/bin/bash
#
#********************************************************************
#Author:zhangzhuo
#QQ: 1191400158
#Date: 2021-01-28
#FileName:install_online_mysql5.6_for_centos.sh
#URL: https://www.zhangzhuo.ltd
#Description:The test script
#Copyright (C): 2021 All rights reserved
#********************************************************************
. /etc/init.d/functions
DIR=`pwd`
URL=https://repo.huaweicloud.com/mysql/Downloads/MySQL-5.6/mysql-5.6.50-linux-glibc2.12-x86_64.tar.gz
NAME=`echo $URL | grep -Eo '[^/]+$'`
DIRNAME=`echo $NAME | sed -rn 's/(.*).tar.*/\1/p'`
DATA_DIR=/data/mysql
FULL_NAME=${DIR}/${NAME}
install_mysql_wget(){
rpm -q wget &>/dev/null || yum install -y wget
yum install -y -q libaio perl-Data-Dumper autoconf
if [ -f ${FULL_NAME} ];then
action "安装文件已经存在不需要下载"
else
action "安装文件不存在开始下载" false
wget $URL || { action "下载失败,异常退出" false;exit 10; }
fi
}
install_mysql_user(){
if id mysql &>/dev/null;then
action "MYSQL用户已经存在,无需从新创建!"
else
useradd -r -s /sbin/nologin -d $DATA_DIR mysql
action "mysql用户创建成功"
fi
}
install_mysql_datadir(){
if [ -d $DATA_DIR ];then
action "${DATA_DIR}目录已经存在,无需从新创建!"
chown mysql: $DATA_DIR
else
mkdir -p $DATA_DIR
chown mysql: $DATA_DIR
fi
}
install_mysql_my(){
cat /dev/null
echo "PATH=/usr/local/mysql/bin":'$PATH' >/etc/profile.d/mysql.sh
cp /usr/local/mysql/support-files/mysql.server /etc/init.d/mysqld
chkconfig --add mysqld
service mysqld start
source /etc/profile.d/mysql.sh
mysqladmin ping && action "服务启动成功" || action "服务启动失败请检查" false
fi
}
install_mysql_wget
install_mysql_user
install_mysql_datadir
install_mysql
2.7 实战案例:二进制安装安装MySQL 5.7 和 MySQL8.0
2.7.1 安装相关包
[18:20:20 root@centos7 ~]#yum install libaio numactl-libs
2.7.2 用户和组
[18:27:30 root@centos7 ~]#useradd -r -s /sbin/nologin -d /data/mysql mysql
[18:46:02 root@centos7 local]#mkdir -p /data/mysql
[18:46:10 root@centos7 local]#chown mysql: /data/mysql
2.7.3 准备程序文件
[18:29:25 root@centos7 ~]#wget https://repo.huaweicloud.com/mysql/Downloads/MySQL-5.7/mysql-5.7.31-linux-glibc2.12-x86_64.tar.gz
[18:35:03 root@centos7 ~]#tar xf mysql-5.7.31-linux-glibc2.12-x86_64.tar.gz -C /usr/local/
[18:36:36 root@centos7 ~]#cd /usr/local/
[18:36:59 root@centos7 local]#ln -s mysql-5.7.31-linux-glibc2.12-x86_64 mysql
[18:37:37 root@centos7 local]#chown -R root: /usr/local/mysql
2.7.4准备环境变量
[18:38:55 root@centos7 local]#echo 'PATH=/usr/local/mysql/bin:$PATH' >/etc/profile.d/mysql.sh
[18:39:08 root@centos7 local]#. /etc/profile.d/mysql.sh
2.7.5 准备配置文件
[18:43:53 root@centos7 local]#grep -Ev '^#|$^' /etc/my.cnf
[mysqld]
datadir=/data/mysql
skip_name_resolve=1
socket=/date/mysql/mysql.sock
log-error=/var/log/mysql.log
[client]
socket=/data/mysql/mysql.sock
!includedir /etc/my.cnf.d
[18:51:01 root@centos7 local]#touch /var/log/mysql.log
[18:51:16 root@centos7 local]#chown mysql: /var/log/mysql.log
2.7.6 生成数据库文件,并提取root密码
[18:46:25 root@centos7 local]#mysqld --initialize --user=mysql --datadir=/data/mysql
[18:52:20 root@centos7 local]#grep password /var/log/mysql.log
2021-01-28T10:51:39.397031Z 1 [Note] A temporary password is generated for root@localhost: ggtorsg(H6wj
2.7.7 准备服务脚本和启动
[19:17:02 root@centos7 ~]#cp /usr/local/mysql/support-files/mysql.server /etc/init.d/mysqld
[19:17:27 root@centos7 ~]#chkconfig --add mysqld
[19:27:59 root@centos7 ~]#service mysqld start
2.7.8 修改口令
[19:28:59 root@centos7 ~]#mysqladmin -uroot -p'gEG?>*c=E8oL' password 123456
2.7.9 测试登录
[19:53:56 root@centos7 ~]#mysql -uroot -p123456
2.8 实战案例:一键安装MySQL5.7 和 MySQL8.0 二进制包的脚本
2.8.1 在线安装脚本
#!/bin/bash
#
#********************************************************************
#Author:zhangzhuo
#QQ: 1191400158
#Date: 2021-01-28
#FileName:install_mysql5.7-8.0.sh
#URL: https://www.zhangzhuo.ltd
#Description:The test script
#Copyright (C): 2021 All rights reserved
#********************************************************************
. /etc/init.d/functions
DIR=`pwd`
URL=https://repo.huaweicloud.com/mysql/Downloads/MySQL-5.7/mysql-5.7.31-linux-glibc2.12-x86_64.tar.gz
NAME=`echo $URL | grep -Eo '[^/]+$'`
DIRNAME=`echo $NAME | sed -rn 's/(.*).tar.*/\1/p'`
DATA_DIR=/data/mysql
FULL_NAME=${DIR}/${NAME}
PASSWORD=123456
install_mysql_wget(){
rpm -q wget &>/dev/null || yum install -y wget
yum install -y -q libaio perl-Data-Dumper autoconf
if [ -f ${FULL_NAME} ];then
action "安装文件已经存在不需要下载"
else
action "安装文件不存在开始下载" false
wget $URL || { action "下载失败,异常退出" false;exit 10; }
fi
}
install_mysql_user(){
if id mysql &>/dev/null;then
action "MYSQL用户已经存在,无需从新创建!"
else
useradd -r -s /sbin/nologin -d $DATA_DIR mysql
action "mysql用户创建成功"
fi
}
install_mysql_datadir(){
if [ -d $DATA_DIR ];then
action "${DATA_DIR}目录已经存在,无需从新创建!"
chown mysql: $DATA_DIR
else
mkdir -p $DATA_DIR
chown mysql: $DATA_DIR
action "${DATA_DIR}目录创建完成!"
fi
}
install_mysql_my(){
cat /etc/profile.d/mysql.sh
source /etc/profile.d/mysql.sh
mysqld --initialize --user=mysql --datadir=/data/mysql &>/dev/null
cp /usr/local/mysql/support-files/mysql.server /etc/init.d/mysqld
chkconfig --add mysqld
service mysqld start && action "服务启动完成" || action "服务启动失败" false
mysql_set_passwd
fi
}
install_mysql_wget
install_mysql_user
install_mysql_datadir
install_mysql
2.9 源码编译安装 MySQL 5.6
建议:内存4G以上,CPU 核数越多越好
2.9.1 安装相关依赖包
yum -y install gcc gcc-c++ cmake bison bison-devel zlib-devel libcurl-devel libarchive-devel boost-devel ncurses-devel gnutls-devel libxml2-devel openssl-devel libevent-devel libaio-devel perl-Data-Dumper
2.9.2 做准备用户和数据目录
useradd -r -s /sbin/nologin -d /data/mysql mysql
2.9.3 准备数据库目录
mkdir /data/mysql
chown mysql.mysql /data/mysql
2.9.4 源码编译安装
编译安装说明
利用cmake编译,而利用传统方法,cmake的重要特性之一是其独立于源码(out-of-source)的编译功能,即编译工作可以在另一个指定的目录中而非源码目录中进行,这可以保证源码目录不受任何一次编译的影响,因此在同一个源码树上可以进行多次不同的编译,如针对于不同平台编译
编译选项:https://dev.mysql.com/doc/refman/5.7/en/source-configuration-options.html
2.9.4.1 下载并解压缩源码包
2.9.4.2 源码编译安装mariadb
cmake . -DCMAKE_INSTALL_PREFIX=/apps/mysql -DMYSQL_DATADIR=/data/mysql/ -DSYSCONFDIR=/etc/ -DMYSQL_USER=mysql -DWITH_INNOBASE_STORAGE_ENGINE=1 -DWITH_ARCHIVE_STORAGE_ENGINE=1 -DWITH_BLACKHOLE_STORAGE_ENGINE=1 -DWITH_PARTITION_STORAGE_ENGINE=1 -DWITHOUT_MROONGA_STORAGE_ENGINE=1 -DWITH_DEBUG=0 -DWITH_READLINE=1 -DWITH_SSL=system -DWITH_ZLIB=system -DWITH_LIBWRAP=0 -DENABLED_LOCAL_INFILE=1 -DMYSQL_UNIX_ADDR=/data/mysql/mysql.sock -DDEFAULT_CHARSET=utf8 -DDEFAULT_COLLATION=utf8_general_ci
[21:17:56 root@centos7 mysql-5.6.49]#make
[21:20:36 root@centos7 mysql-5.6.49]#make install
提示:如果出错,执行rm -f CMakeCache.txt
2.9.5 准备环境变量
[21:22:01 root@centos7 mysql-5.6.49]#echo 'PATH=/apps/mysql/bin:$PATH' >/etc/profile.d/mysql.sh
[21:22:08 root@centos7 mysql-5.6.49]#source /etc/profile.d/mysql.sh
2.9.6 生成数据库文件
[21:22:29 root@centos7 mysql]#scripts/mysql_install_db --datadir=/data/mysql --user=mysql
2.9.7 准备配置文件
[21:23:44 root@centos7 mysql]#cp -b /apps/mysql/support-files/my-default.cnf /etc/my.cnf
2.9.8 准备启动脚本,并启动服务
[21:24:46 root@centos7 mysql]#cp /apps/mysql/support-files/mysql.server /etc/init.d/mysqld
[21:25:18 root@centos7 mysql]#chkconfig --add mysqld
[21:25:30 root@centos7 mysql]#service mysqld start
Starting MySQL.Logging to '/data/mysql/centos7.err'.
. SUCCESS!
2.9.9 安全初始化
[21:26:52 root@centos7 mysql]#mysql_secure_installation
2.10 基于 dockcer 容器创建MySQL
范例:
[14:39:24 root@centos7 ~]#docker run --name mysql -d -p 3306:3306 -e MYSQL_ROOT_PASSWORD=123456 mysql:8.0
2.11 MySQL多实例
2.11.1 多实例介绍
-
什么是数据库多实例
- MySQL多实例就是在一台服务器上同时开启多个不同的服务端口(如:3306、3307等),同时运行多个MySQL服务进程,这些服务进程通过不同的Socket监听不同的服务端口来提供服务。多实例可能是MySQL的不同版本,也可能是MySQL的同一版本实现
-
多实例的好处
- 可有效利用服务器资源。当单个服务器资源有剩余时,可以充分利用剩余资源提供更多的服务,且可以实现资源的逻辑隔离节约服务器资源。例如公司服务器资源紧张,但是数据库又需要各自尽量独立的提供服务,并且还需要到主从复制等技术,多实例就是最佳选择
-
多实例弊端
- 存在资源互相抢占的问题。比如:当某个数据库实例并发很高或者SQL查询慢时,整个实例会消耗大量的CPU、磁盘I/O等资源,导致服务器上面其他的数据库实例在提供服务的质量也会下降,所以具体的需求要根据自己的实际情况而定。
2.11.2 实战案例 1: CentOS 8 实现 MySQL 8.0 二进制安装的多实例
本案例适用于以版本
mysql-8.0.23-linux-glibc2.12-x86_64.tar.xz
mysql-5.7.33-linux-glibc2.12-x86_64.tar.gz
实战目标
CentOS8 二进制安装MySQL8.0,并实现三个实例
环境说明
一台系统CentOS 8.X主机
前提准备
关闭SElinux
关闭防火墙
时间同步
2.11.2.1 实现步骤
下载MySQL二进制文件并解压缩
[14:48:49 root@centos8 ~]##wget http://mirrors.163.com/mysql/Downloads/MySQL-8.0/mysql-8.0.23-linux-glibc2.12-x86_64.tar
[14:49:55 root@centos8 ~]#tar -xvf mysql-8.0.21-linux-glibc2.12-x86_64.tar -C /usr/local/
[14:50:06 root@centos8 ~]#cd /usr/local/
[14:50:11 root@centos8 local]#ln -sv mysql-8.0.21-linux-glibc2.12-x86_64 mysql
[14:50:46 root@centos8 local]#ll mysql/
total 408
drwxr-xr-x 2 7161 31415 4096 Jun 17 2020 bin
drwxr-xr-x 2 7161 31415 55 Jun 17 2020 docs
drwxr-xr-x 3 7161 31415 282 Jun 17 2020 include
drwxr-xr-x 6 7161 31415 201 Jun 17 2020 lib
-rw-r--r-- 1 7161 31415 404759 Jun 17 2020 LICENSE
drwxr-xr-x 4 7161 31415 30 Jun 17 2020 man
-rw-r--r-- 1 7161 31415 687 Jun 17 2020 README
drwxr-xr-x 28 7161 31415 4096 Jun 17 2020 share
drwxr-xr-x 2 7161 31415 77 Jun 17 2020 support-files
创建用户和组配置权限
[14:50:58 root@centos8 local]#useradd -r -s /sbin/nologin mysql
[14:51:45 root@centos8 local]#chown -R mysql: /usr/local/mysql/
[14:52:17 root@centos8 local]#ll /usr/local/mysql/
total 408
drwxr-xr-x 2 mysql mysql 4096 Jun 17 2020 bin
drwxr-xr-x 2 mysql mysql 55 Jun 17 2020 docs
drwxr-xr-x 3 mysql mysql 282 Jun 17 2020 include
drwxr-xr-x 6 mysql mysql 201 Jun 17 2020 lib
-rw-r--r-- 1 mysql mysql 404759 Jun 17 2020 LICENSE
drwxr-xr-x 4 mysql mysql 30 Jun 17 2020 man
-rw-r--r-- 1 mysql mysql 687 Jun 17 2020 README
drwxr-xr-x 28 mysql mysql 4096 Jun 17 2020 share
drwxr-xr-x 2 mysql mysql 77 Jun 17 2020 support-files
配置环境变量
[14:52:29 root@centos8 local]#echo 'export PATH=/usr/local/mysql/bin:$PATH' >/etc/profile.d/mysql.sh
[14:53:33 root@centos8 local]#. /etc/profile.d/mysql.sh
创建各实例数据存放的目录
[14:53:42 root@centos8 local]#mkdir -p /mysql/{3306,3307,3308}
[14:54:46 root@centos8 local]#chown -R mysql: /mysql/
[14:55:13 root@centos8 local]#ll /mysql/
total 0
drwxr-xr-x 2 mysql mysql 6 Jan 30 14:54 3306
drwxr-xr-x 2 mysql mysql 6 Jan 30 14:54 3307
drwxr-xr-x 2 mysql mysql 6 Jan 30 14:54 3308
[14:55:18 root@centos8 local]#tree /mysql/
/mysql/
├── 3306
├── 3307
└── 3308
初始化各实例数据库文件
#针对每个实例初始化
[14:55:22 root@centos8 local]#mysqld --initialize-insecure --user=mysql --datadir=/mysql/3306
[14:56:34 root@centos8 local]#mysqld --initialize-insecure --user=mysql --datadir=/mysql/3307
[14:56:46 root@centos8 local]#mysqld --initialize-insecure --user=mysql --datadir=/mysql/3308
[14:57:38 root@centos8 local]#tree /mysql/ -d
/mysql/
├── 3306
│ ├── #innodb_temp
│ ├── mysql
│ ├── performance_schema
│ └── sys
├── 3307
│ ├── #innodb_temp
│ ├── mysql
│ ├── performance_schema
│ └── sys
└── 3308
├── #innodb_temp
├── mysql
├── performance_schema
└── sys
准备配置文件/etc/my.cnf
[14:57:50 root@centos8 local]#file `which mysqld_multi`
/usr/local/mysql/bin/mysqld_multi: Perl script text executable
[14:59:17 root@centos8 local]#vim /etc/my.cnf
[mysqld_multi]
mysqld=/usr/local/mysql/bin/mysqld_safe
mysqladmin=/usr/local/mysql/bin/mysqladmin
[mysqld3306]
datadir=/mysql/3306
port=3306
socket=/mysql/3306/mysql3306.sock
pid-file=/mysql/3306/mysql3306.pid
log-error=/mysql/3306/mysql3306.log
[mysqld3307]
datadir=/mysql/3307
port=3307
socket=/mysql/3307/mysql3307.sock
pid-file=/mysql/3307/mysql3307.pid
log-error=/mysql/3307/mysql3307.log
[mysqld3308]
datadir=/mysql/3308
port=3308
socket=/mysql/3308/mysql3308.sock
pid-file=/mysql/3308/mysql3308.pid
log-error=/mysql/3308/mysql3308.log
启动多实例
#说明:用 mysqld_multi start N 启动多个实例,
#注意数字N和my.cnf中的[mysqldN]对应,示例:1-3就是启动[mysqld1]、[mysqld2]、[mysqld3]配置段的MySQL实例
#启动三个MySQL实例
[root@centos8 ~]#mysqld_multi start 3306
[root@centos8 ~]#mysqld_multi start 3307
[root@centos8 ~]#mysqld_multi start 3308
# 或者用下面命令批量启动多个实例
[15:25:47 root@centos8 ~]#mysqld_multi start 3306-3308
[15:24:45 root@centos8 ~]#ss -ntl
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 0.0.0.0:111 0.0.0.0:*
LISTEN 0 128 0.0.0.0:22 0.0.0.0:*
LISTEN 0 70 *:33060 *:*
LISTEN 0 128 *:3306 *:*
LISTEN 0 128 *:3307 *:*
LISTEN 0 128 *:3308 *:*
LISTEN 0 128 [::]:111 [::]:*
LISTEN 0 128 [::]:22 [::]:*
关闭多实例
[15:25:47 root@centos8 ~]#mysqld_multi stop 3306-3308
安全加固
#批量修改多个实例root密码
[15:28:43 root@centos8 ~]#for i in {3306..3308};do mysqladmin -S /mysql/$i/mysql$i.sock password 123456;done
#批量验证密码连接
[15:28:46 root@centos8 ~]#for i in {3306..3308};do mysqladmin -uroot -p123456 -S /mysql/$i/mysql$i.sock ping;done
配置开机启动多实例
[15:29:46 root@centos8 ~]#vim /etc/rc.d/rc.local
. /etc/profile.d/mysql.sh
mysqld_multi start 3306-3308
[15:31:18 root@centos8 ~]#chmod +x /etc/rc.d/rc.local
rc.local文件中首行必须有shebang机制才可以生效
#!/bin/bash
2.12.3 实战案例 2:CentOS 8 实现mariadb的yum安装的多实例
实战目的
CentOS 8 yum安装mariadb-10.3.17并实现三个实例
环境要求
一台系统CentOS 8.X主机
前提准备
关闭SElinux
关闭防火墙
时间同步
2.12.3.1 实现步骤
安装mariadb
[10:27:54 root@centos8 ~]#yum install -y mariadb-server
准备三个实例的目录
[10:27:54 root@centos8 ~]#mkdir -pv /mysql/{3306,3307,3308}/{data,etc,socket,log,bin,pid}
[10:28:29 root@centos8 ~]#chown -R mysql:mysql /mysql
[10:28:35 root@centos8 ~]#tree /mysql/
/mysql/
├── 3306
│ ├── bin
│ ├── data
│ ├── etc
│ ├── log
│ ├── pid
│ └── socket
├── 3307
│ ├── bin
│ ├── data
│ ├── etc
│ ├── log
│ ├── pid
│ └── socket
└── 3308
├── bin
├── data
├── etc
├── log
├── pid
└── socket
21 directories, 0 files
生成数据库文件
[10:30:21 root@centos8 ~]#mysql_install_db --user=mysql --datadir=/mysql/3306/data
[10:30:21 root@centos8 ~]#mysql_install_db --user=mysql --datadir=/mysql/3307/data
[10:30:21 root@centos8 ~]#mysql_install_db --user=mysql --datadir=/mysql/3308/data
准备配置文件
[10:30:28 root@centos8 ~]#vim /mysql/3306/etc/my.cnf
[mysqld]
port=3306
datadir=/mysql/3306/data
socket=/mysql/3306/socket/mysql.sock
log-error=/mysql/3306/log/mysql.log
pid-file=/mysql/3306/pid/mysql.pid
#重复上面步骤设置3307,3308
[10:34:49 root@centos8 ~]#sed 's/3306/3307/' /mysql/3306/etc/my.cnf >/mysql/3307/etc/my.cnf
[10:35:01 root@centos8 ~]#sed 's/3306/3308/' /mysql/3306/etc/my.cnf >/mysql/3308/etc/my.cnf
准备启动脚本
[10:58:36 root@centos8 ~]#vim /mysql/3306/bin/mysqld
#!/bin/bash
port=3306
mysql_user="root"
mysql_pwd="123456"
cmd_path="/usr/bin"
mysql_basedir="/mysql"
mysql_sock="${mysql_basedir}/${port}/socket/mysql.sock"
function_start_mysql(){
if [ ! -e "$mysql_sock" ];then
printf "Starting MySQL...\n"
${cmd_path}/mysqld_safe --defaults-file=${mysql_basedir}/${port}/etc/my.cnf &>/dev/null &
else
printf "MySQL is running...\n"
exit
fi
}
function_stop_mysql(){
if [ ! -e "$mysql_sock" ];then
printf "MySQL is stopped...\n"
exit
else
printf "Stoping MySQL...\n"
${cmd_path}/mysqladmin -u${mysql_user} -p${mysql_pwd} -S ${mysql_sock} shutdown
fi
}
function_restart_mysql(){
printf "Restarting MySQL...\n"
function_stop_mysql
sleep 2
function_start_mysql
}
case $1 in
start)
function_start_mysql
;;
stop)
function_stop_mysql
;;
restart)
function_restart_mysql
;;
*)
printf "Usage:${mysql_basedir}/${port}/bin/mysqld {start|stop|restart}\n"
esac
[10:59:22 root@centos8 ~]#chmod +x /mysql/3306/bin/mysqld
#重复上述过程,分别建立3307,3308的启动脚本
启动服务
[11:06:50 root@centos8 ~]#/mysql/3306/bin/mysqld start
[11:06:50 root@centos8 ~]#/mysql/3307/bin/mysqld start
[11:06:50 root@centos8 ~]#/mysql/3308/bin/mysqld start
[11:06:50 root@centos8 ~]#ss -ntl
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 0.0.0.0:111 0.0.0.0:*
LISTEN 0 128 0.0.0.0:22 0.0.0.0:*
LISTEN 0 80 *:3306 *:*
LISTEN 0 80 *:3307 *:*
LISTEN 0 80 *:3308 *:*
LISTEN 0 128 [::]:111 [::]:*
LISTEN 0 128 2.8.3.4.7 登录实例 [::]:22 [::]:*
登录实例
[11:07:51 root@centos8 ~]#mysql -h 127.0.0.1 -P 3308
确认登录的端口
MariaDB [(none)]> show variables like 'port';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| port | 3308 |
+---------------+-------+
1 row in set (0.001 sec)
#关闭数据库,需要手动输入root的密码请吧stop中的-p后面的变量删除
[11:09:53 root@centos8 ~]#/mysql/3308/bin/mysqld stop
Stoping MySQL...
Enter password:
修改root密码
#加上root的口令
[11:12:18 root@centos8 ~]#mysqladmin -uroot -S /mysql/3306/socket/mysql.sock password 123456
[11:12:18 root@centos8 ~]#mysqladmin -uroot -S /mysql/3307/socket/mysql.sock password 123456
[11:12:18 root@centos8 ~]#mysqladmin -uroot -S /mysql/3308/socket/mysql.sock password 123456
#或者登录mysql,执行下面也可以
Mariadb>update mysql.user set password=password("centos") where user='root';
Mariadb>flush privileges;
测试连接
[11:12:40 root@centos8 ~]#mysql -uroot -p -S /mysql/3306/socket/mysql.sock
Enter password:
#提示输入口令才能登录
三、SQL 语言
3.1 关系型数据库的常见组件
- 数据库:database
- 表:table,行:row 列:column
- 索引:index
- 视图:view
- 存储过程:procedure
- 存储函数:function
- 触发器:trigger
- 事件调度器:event scheduler,任务计划
- 用户:user
- 权限:privilege
3.2 SQL语言的兴起与语法标准
目前,所有主要的关系数据库管理系统支持某些形式的SQL,大部分数据库至少遵守ANSI SQL89标准,虽然有这一标准的存在,但大部分的SQL代码在不同的数据库系统中并不具有完全的跨平台性业内标准
微软和Sybase的T-SQL,Oracle的PL/SQL
3.2.1 SQL 语言规范
在数据库系统中,SQL 语句不区分大小写,建议用大写
SQL语句可单行或多行书写,默认以 " ; " 结尾
关键词不能跨多行或简写
用空格和TAB 缩进来提高语句的可读性
子句通常位于独立行,便于编辑,提高可读性
注释:
- SQL标准:
#单行注释,注意有空格
-- 注释内容
#多行注释
/*注释内容
注释内容
注释内容*/
- MySQL注释:
# 注释内容
3.2.2 数据库对象和命名
数据库的组件(对象):
- 数据库、表、索引、视图、用户、存储过程、函数、触发器、事件调度器等
命名规则:
- 必须以字母开头,后续可以包括字母,数字和三个特殊字符(# _ $)
- 不要使用MySQL的保留字
3.2.3 SQL语句分类
- DDL: Data Defination Language 数据定义语言
- CREATE,DROP,ALTER
- DML: Data Manipulation Language 数据操纵语言
- INSERT,DELETE,UPDATE
- DQL:Data Query Language 数据查询语言
- SELECT
- DCL:Data Control Language 数据控制语言
- GRANT,REVOKE
- 软件开发:CRUD
3.2.4 SQL语句构成
关健字Keyword组成子句clause,多条clause组成语句
示例:
SELECT * #SELECT子句
FROM products #FROM子句
WHERE price>666 #WHERE子句
说明:一组SQL语句由三个子句构成,SELECT,FROM和WHERE是关键字
获取SQL 命令使用帮助:
官方帮助:https://dev.mysql.com/doc/refman/8.0/en/sql-statements.html
mysql> HELP KEYWORD
3.2.5 字符集和排序
早期MySQL版本默认为latin1,从MySQL8.0开始默认字符集已经为 utf8mb4
查看支持所有字符集:
11:37:27(root@localhost) [(none)]> show character set;
#特别注意mysql中utf8并不是真正的uft8
正确的utf8最大应该占4个字节而mysql中utf8占3个字节,所以会导致一些生僻字显示不了
如要使用utf8应使用utf8mb4
utf8 | UTF-8 Unicode | utf8_general_ci | 3
查看支持所有排序规则:
11:37:42(root@localhost) [(none)]> show collation;
查看当前使用的排序规则
11:38:29(root@localhost) [(none)]> show variables like 'collation%';
设置服务器默认的字符集
[11:44:27 root@centos8 ~]#vim /etc/my.cnf
[mysqld]
character-set-server=utf8
设置客户端默认的字符集
#针对mysql客户端
[mysql]
default-character-set=utf8
#针对所有mysql客户端
[client]
default-character-set=utf8
范例:字符集和相关文件
11:47:48(root@localhost) [(none)]> show character set;
[11:48:20 root@centos8 ~]#ll /usr/share/mysql/charsets/
查看当前字符集的使用情况
11:49:01(root@localhost) [(none)]> show variables like 'character%';
3.3 管理数据库
3.3.1 创建数据库
CREATE DATABASE|SCHEMA [IF NOT EXISTS] 'DB_NAME'
CHARACTER SET 'character set name'
COLLATE 'collate name';
范例:
#创建数据库
11:49:20(root@localhost) [(none)]> create database db1;
Query OK, 1 row affected (0.00 sec)
#查看你创建的数据库
11:51:58(root@localhost) [(none)]> 11:51:58(root@localhost) [(none)]> show create database db1;
+----------+-------------------------------------------------------------------------------------------------+
| Database | Create Database |
+----------+-------------------------------------------------------------------------------------------------+
| db1 | CREATE DATABASE `db1` /*!40100 DEFAULT CHARACTER SET utf8 */ /*!80016 DEFAULT ENCRYPTION='N' */ |
+----------+-------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
#使用的字符集和排序规则存放位置
[root@centos8 ~]#cat /var/lib/mysql/db1/db.opt
default-character-set=latin1
default-collation=latin1_swedish_ci
11:55:31(root@localhost) [(none)]> create database db1;
ERROR 1007 (HY000): Can't create database 'db1'; database exists
11:55:41(root@localhost) [(none)]> create database IF NOT EXISTS db1;
Query OK, 1 row affected, 1 warning (0.00 sec)
11:56:22(root@localhost) [(none)]> show warnings;
+-------+------+----------------------------------------------+
| Level | Code | Message |
+-------+------+----------------------------------------------+
| Note | 1007 | Can't create database 'db1'; database exists |
+-------+------+----------------------------------------------+
1 row in set (0.00 sec)
范例:指定字符集创建新数据库
11:56:33(root@localhost) [(none)]> create database IF NOT EXISTS db2 CHARACTER SET 'utf8mb4';
Query OK, 1 row affected (0.00 sec)
11:58:17(root@localhost) [(none)]> 11:58:17(root@localhost) [(none)]> show create database db2;
+----------+-------------------------------------------------------------------------------------------------------------------------------+
| Database | Create Database |
+----------+-------------------------------------------------------------------------------------------------------------------------------+
| db2 | CREATE DATABASE `db2` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci */ /*!80016 DEFAULT ENCRYPTION='N' */ |
+----------+-------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
范例: 创建数据库指定字符集,并且指定排序规则
12:00:16(root@localhost) [(none)]> create database zabbix character set utf8 collate utf8_bin;
3.3.2 修改数据库
ALTER DATABASE DB_NAME character set utf8;
范例:
12:04:43(root@localhost) [(none)]> alter database db1 character set utf8mb4;
Query OK, 1 row affected (0.00 sec)
12:05:14(root@localhost) [(none)]> show create database db1;
+----------+-------------------------------------------------------------------------------------------------------------------------------+
| Database | Create Database |
+----------+-------------------------------------------------------------------------------------------------------------------------------+
| db1 | CREATE DATABASE `db1` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci */ /*!80016 DEFAULT ENCRYPTION='N' */ |
+----------+-------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
3.3.3 删除数据库
DROP DATABASE|SCHEMA [IF EXISTS] 'DB_NAME';
范例:
12:05:30(root@localhost) [(none)]> drop database db1;
Query OK, 0 rows affected (0.01 sec)
12:06:41(root@localhost) [(none)]> show databases;
+--------------------+
| Database |
+--------------------+
| db2 |
| information_schema |
| mysql |
| performance_schema |
| sys |
| zabbix |
+--------------------+
6 rows in set (0.01 sec)
[12:07:11 root@centos8 ~]#tree /var/lib/mysql -d
/var/lib/mysql
├── db2
├── #innodb_temp
├── mysql
├── performance_schema
├── sys
└── zabbix
3.3.4 查看数据库列表
SHOW DATABASES;
范例:
12:07:58(root@localhost) [(none)]> show databases;
+--------------------+
| Database |
+--------------------+
| db2 |
| information_schema |
| mysql |
| performance_schema |
| sys |
| zabbix |
+--------------------+
6 rows in set (0.00 sec)
3.4 数据类型
数据类型:
- 数据长什么样
- 数据需要多少空间来存放
数据类型
- 系统内置数据类型
- 用户定义数据类型
MySQL支持多种内置数据类型
- 数值类型
- 日期/时间类型
- 字符串(字符)类型
数据类型参考链接
https://dev.mysql.com/doc/refman/8.0/en/data-types.html
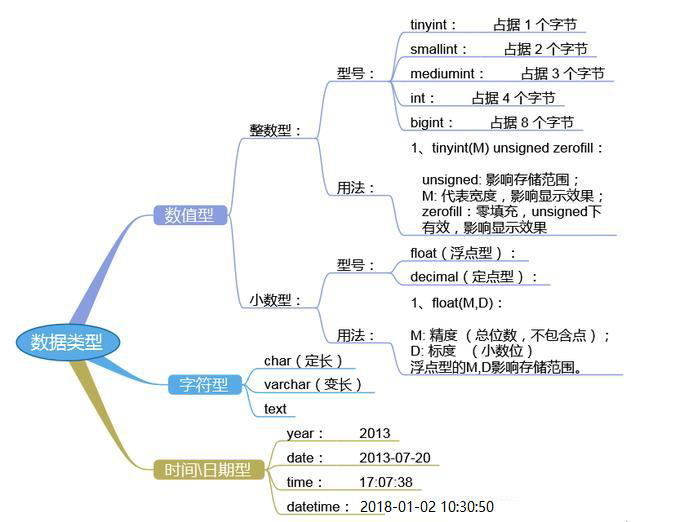
选择正确的数据类型对于获得高性能至关重要,三大原则:
- 更小的通常更好,尽量使用可正确存储数据的最小数据类型
- 简单就好,简单数据类型的操作通常需要更少的CPU周期
- 尽量避免NULL,包含为NULL的列,对MySQL更难优化
3.4.1 整数型
tinyint(m) 1个字节 范围(-128~127)
smallint(m) 2个字节 范围(-32768~32767)
mediumint(m) 3个字节 范围(-8388608~8388607)
int(m) 4个字节 范围(-2147483648~2147483647)
bigint(m) 8个字节 范围(+-9.22*10的18次方)
上述数据类型,如果加修饰符unsigned后,则最大值翻倍
如:tinyint unsigned的取值范围为(0~255)
int(m)里的m是表示SELECT查询结果集中的显示宽度,并不影响实际的取值范围,规定了MySQL的一些交互工具(例如MySQL命令行客户端)用来显示字符的个数。对于存储和计算来说,Int(1)和Int(20)是相同的
BOOL,BOOLEAN:布尔型,是TINYINT(1)的同义词。zero值被视为假,非zero值视为真
3.4.2 浮点型(float和double),近似值
float(m,d) 单精度浮点型 8位精度(4字节) m总个数,d小数位
double(m,d) 双精度浮点型16位精度(8字节) m总个数,d小数位
设一个字段定义为float(6,3),如果插入一个数123.45678,实际数据库里存的是123.457,但总个数还以实际为准,即6位
3.4.3 定点数
在数据库中存放的是精确值,存为十进制
decimal(m,d) 参数m<65 是总个数,d<30且 d<m 是小数位
MySQL5.0和更高版本将数字打包保存到一个二进制字符串中(每4个字节存9个数字)。
例如: decimal(18,9)小数点两边将各存储9个数字,一共使用9个字节:其中,小数点前的9个数字用4个字节,小数点后的9个数字用4个字节,小数点本身占1个字节
浮点类型在存储同样范围的值时,通常比decimal使用更少的空间。float使用4个字节存储。double占用8个字节
因为需要额外的空间和计算开销,所以应该尽量只在对小数进行精确计算时才使用decimal,例如存储财务数据。但在数据量比较大的时候,可以考虑使用bigint代替decimal
3.4.4 字符串(char,varchar,text)
char(n) 固定长度,最多255个字符,注意不是字节
varchar(n) 可变长度,最多65535个字符
tinytext 可变长度,最多255个字符
text 可变长度,最多65535个字符
mediumtext 可变长度,最多2的24次方-1个字符
longtext 可变长度,最多2的32次方-1个字符
BINARY(M) 固定长度,可存二进制或字符,长度为0-M字节
VARBINARY(M) 可变长度,可存二进制或字符,允许长度为0-M字节
内建类型:ENUM枚举, SET集合
char和varchar的比较:
参考:https://dev.mysql.com/doc/refman/8.0/en/char.html
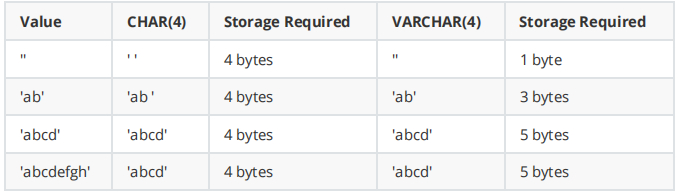
- char(n) 若存入字符数小于n,则以空格补于其后,查询之时再将空格去掉,所以char类型存储的字符串末尾不能有空格,varchar不限于此
- char(n) 固定长度,char(4)不管是存入几个字符,都将占用4个字节,varchar是存入的实际字符数+1个字节(n< n>255),所以varchar(4),存入3个字符将占用4个字节
- char类型的字符串检索速度要比varchar类型的快
varchar 和 text:
- varchar可指定n,text不能指定,内部存储varchar是存入的实际字符数+1个字节(n< n>255),text是实际字符数+2个字节。
- text类型不能有默认值
- varchar可直接创建索引,text创建索引要指定前多少个字符。varchar查询速度快于text
3.4.5 二进制数据BLOB
BLOB和text存储方式不同,TEXT以文本方式存储,英文存储区分大小写,而Blob以二进制方式存储,不分大小写
BLOB存储的数据只能整体读出
TEXT可以指定字符集,BLOB不用指定字符集
3.4.6 日期时间类型
date 日期 '2008-12-2'
time 时间 '12:25:36'
datetime 日期时间 '2008-12-2 22:06:44'
timestamp 自动存储记录修改时间
YEAR(2), YEAR(4):年份
timestamp字段里的时间数据会随其他字段修改的时候自动刷新,这个数据类型的字段可以存放这条记录最后被修改的时间
3.4.7 修饰符
NULL 数据列可包含NULL值,默认值
NOT NULL 数据列不允许包含NULL值,相当于网站注册表中的 * 为必填选项
DEFAULT 默认值
PRIMARY KEY 主键,所有记录中此字段的值不能重复,且不能为NULL
UNIQUE KEY 唯一键,所有记录中此字段的值不能重复,但可以为NULL
CHARACTER SET name 指定一个字符集
适用数值型的修饰符:
AUTO_INCREMENT 自动递增,适用于整数类型
UNSIGNED 无符号
范例:AUTO_INCREMENT
02:27:31(root@localhost) [(none)]> create database test;
Query OK, 1 row affected (0.01 sec)
02:27:46(root@localhost) [(none)]> use test
Database changed
02:27:54(root@localhost) [test]> create table t1(id int unsigned auto_increment primary key) auto_increment = 4294967294;
Query OK, 0 rows affected (0.02 sec)
02:31:43(root@localhost) [test]> show table status from test like "t1" \G
*************************** 1. row ***************************
Name: t1
Engine: InnoDB
Version: 10
Row_format: Dynamic
Rows: 0
Avg_row_length: 0
Data_length: 16384
Max_data_length: 0
Index_length: 0
Data_free: 0
Auto_increment: 4294967294
Create_time: 2021-01-31 14:29:48
Update_time: NULL
Check_time: NULL
Collation: utf8_general_ci
Checksum: NULL
Create_options:
Comment:
1 row in set (0.00 sec)
02:33:15(root@localhost) [test]> insert into t1 values(null);
Query OK, 1 row affected (0.00 sec)
02:33:19(root@localhost) [test]> select * from t1;
+------------+
| id |
+------------+
| 4294967294 |
| 4294967295 |
+------------+
2 rows in set (0.00 sec)
02:33:32(root@localhost) [test]> insert into t1 values(null);
ERROR 1062 (23000): Duplicate entry '4294967295' for key 't1.PRIMARY'
#上面表的数据类型无法存放所有数据,修改过数据类型实现自增长数据的增加
02:33:42(root@localhost) [test]> alter table t1 modify id bigint auto_increment;
Query OK, 2 rows affected (0.03 sec)
Records: 2 Duplicates: 0 Warnings: 0
02:35:02(root@localhost) [test]> desc t1;
+-------+--------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+--------+------+-----+---------+----------------+
| id | bigint | NO | PRI | NULL | auto_increment |
+-------+--------+------+-----+---------+----------------+
1 row in set (0.01 sec)
02:35:12(root@localhost) [test]> insert t1 values(null);
Query OK, 1 row affected (0.00 sec)
02:35:34(root@localhost) [test]> select * from t1;
+------------+
| id |
+------------+
| 4294967294 |
| 4294967295 |
| 4294967296 |
+------------+
3 rows in set (0.00 sec)
3.5 DDL 语句
表:二维关系
设计表:遵循规范
定义:字段,索引
- 字段:字段名,字段数据类型,修饰符
- 约束,索引:应该创建在经常用作查询条件的字段上
3.5.1 创建表
创建表:
CREATE TABLE
获取帮助:
HELP CREATE TABLE
创建表的方法
CREATE TABLE [IF NOT EXISTS] 'tbl_name' (col1 type1 修饰符, col2 type2 修饰符,
...)
#字段信息
col type1
PRIMARY KEY(col1,...)
INDEX(col1, ...)
UNIQUE KEY(col1, ...)
#表选项:
ENGINE [=] engine_name
ROW_FORMAT [=] {DEFAULT|DYNAMIC|FIXED|COMPRESSED|REDUNDANT|COMPACT}
注意:
- Storage Engine是指表类型,也即在表创建时指明其使用的存储引擎
- 同一库中不同表可以使用不同的存储引擎
- 同一个库中表建议要使用同一种存储引擎类型
范例:创建表
2:46:55(root@localhost) [db1]> create table student ( id int unsigned auto_increment primary key, name varchar(20) not null, age tinyint unsigned, gender enum('M','F') default 'M' )ENGINE=InnoDB auto_increment=10 default charset=utf8;
Query OK, 0 rows affected, 1 warning (0.02 sec)
#id字段以10初始值
02:46:57(root@localhost) [db1]> desc student;
+--------+------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------+------------------+------+-----+---------+----------------+
| id | int unsigned | NO | PRI | NULL | auto_increment |
| name | varchar(20) | NO | | NULL | |
| age | tinyint unsigned | YES | | NULL | |
| gender | enum('M','F') | YES | | M | |
+--------+------------------+------+-----+---------+----------------+
4 rows in set (0.00 sec)
02:48:08(root@localhost) [db1]> insert student (name,age) values('xiaoming',20);
Query OK, 1 row affected (0.00 sec)
02:48:20(root@localhost) [db1]> select * from student;
+----+----------+------+--------+
| id | name | age | gender |
+----+----------+------+--------+
| 10 | xiaoming | 20 | M |
+----+----------+------+--------+
1 row in set (0.01 sec)
02:48:35(root@localhost) [db1]> insert student (name,age,gender) values('xiaohong',18,'f');
Query OK, 1 row affected (0.00 sec)
02:49:35(root@localhost) [db1]> select *from student;
+----+----------+------+--------+
| id | name | age | gender |
+----+----------+------+--------+
| 10 | xiaoming | 20 | M |
| 11 | xiaohong | 18 | F |
+----+----------+------+--------+
2 rows in set (0.00 sec)
范例:auto_increment 属性
02:49:49(root@localhost) [db1]> show variables like 'auto_inc%';
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| auto_increment_increment | 1 |
| auto_increment_offset | 1 |
+--------------------------+-------+
2 rows in set (0.01 sec)
#修改默认起始数
02:50:47(root@localhost) [db1]> set @@auto_increment_increment=10;
Query OK, 0 rows affected (0.00 sec)
#修改默认步长
02:51:34(root@localhost) [db1]> set @@auto_increment_offset=3;
Query OK, 0 rows affected (0.00 sec)
02:51:46(root@localhost) [db1]> show variables like 'auto_inc%';
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| auto_increment_increment | 10 |
| auto_increment_offset | 3 |
+--------------------------+-------+
2 rows in set (0.00 sec)
范例:时间类型
02:53:11(root@localhost) [db1]> create table testdate (id int auto_increment primary key,date timestamp default current_timestamp not null);
Query OK, 0 rows affected (0.02 sec)
02:55:42(root@localhost) [db1]> insert testdate () values();
Query OK, 1 row affected (0.00 sec)
02:55:49(root@localhost) [db1]> insert testdate () values();
Query OK, 1 row affected (0.00 sec)
02:55:50(root@localhost) [db1]> insert testdate () values();
Query OK, 1 row affected (0.00 sec)
02:55:51(root@localhost) [db1]> select * from testdate;
+----+---------------------+
| id | date |
+----+---------------------+
| 1 | 2021-01-31 14:55:49 |
| 2 | 2021-01-31 14:55:50 |
| 3 | 2021-01-31 14:55:51 |
+----+---------------------+
3 rows in set (0.00 sec)
(2) 通过查询现存表创建;新表会被直接插入查询而来的数据
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name [(create_definition,...)]
[table_options]
[partition_options] select_statement
范例:依据别的表创建新表并且把数据也插入,用于备份
02:58:57(root@localhost) [db1]> create table user select user,host from mysql.user;
Query OK, 4 rows affected (0.02 sec)
Records: 4 Duplicates: 0 Warnings: 0
03:01:53(root@localhost) [db1]> show tables;
+---------------+
| Tables_in_db1 |
+---------------+
| student |
| testdate |
| user |
+---------------+
3 rows in set (0.00 sec)
03:02:04(root@localhost) [db1]> desc user;
+-------+-----------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-----------+------+-----+---------+-------+
| user | char(32) | NO | | | |
| host | char(255) | NO | | | |
+-------+-----------+------+-----+---------+-------+
2 rows in set (0.00 sec)
03:02:10(root@localhost) [db1]> select * from user;
+------------------+-----------+
| user | host |
+------------------+-----------+
| mysql.infoschema | localhost |
| mysql.session | localhost |
| mysql.sys | localhost |
| root | localhost |
+------------------+-----------+
4 rows in set (0.00 sec)
(3) 通过复制现存的表的表结构创建,但不复制数据
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name { LIKE old_tbl_name | (LIKE
old_tbl_name) }
范例:只复制表结构
03:02:22(root@localhost) [db1]> desc student;
+--------+------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------+------------------+------+-----+---------+----------------+
| id | int unsigned | NO | PRI | NULL | auto_increment |
| name | varchar(20) | NO | | NULL | |
| age | tinyint unsigned | YES | | NULL | |
| gender | enum('M','F') | YES | | M | |
+--------+------------------+------+-----+---------+----------------+
4 rows in set (0.00 sec)
03:04:00(root@localhost) [db1]> create table teacher like student;
Query OK, 0 rows affected (0.02 sec)
03:04:21(root@localhost) [db1]> desc teacher;
+--------+------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------+------------------+------+-----+---------+----------------+
| id | int unsigned | NO | PRI | NULL | auto_increment |
| name | varchar(20) | NO | | NULL | |
| age | tinyint unsigned | YES | | NULL | |
| gender | enum('M','F') | YES | | M | |
+--------+------------------+------+-----+---------+----------------+
4 rows in set (0.00 sec)
3.5.2 表查看
查看表:
SHOW TABLES [FROM db_name]
查看表创建命令:
SHOW CREATE TABLE tbl_name
查看表结构:
DESC [db_name.]tb_name
SHOW COLUMNS FROM [db_name.]tb_name
查看表状态:
SHOW TABLE STATUS LIKE 'tbl_name'
查看支持的engine类型
SHOW ENGINES;
范例:查看表当前数据库表列表
03:04:28(root@localhost) [db1]> show tables;
+---------------+
| Tables_in_db1 |
+---------------+
| student |
| teacher |
| testdate |
| user |
+---------------+
4 rows in set (0.00 sec)
范例:查看表结构
03:07:32(root@localhost) [db1]> desc user;
+-------+-----------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-----------+------+-----+---------+-------+
| user | char(32) | NO | | | |
| host | char(255) | NO | | | |
+-------+-----------+------+-----+---------+-------+
2 rows in set (0.00 sec)
03:07:43(root@localhost) [db1]> show columns from user;
+-------+-----------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-----------+------+-----+---------+-------+
| user | char(32) | NO | | | |
| host | char(255) | NO | | | |
+-------+-----------+------+-----+---------+-------+
2 rows in set (0.00 sec)
范例:查看创建表命令
03:09:02(root@localhost) [db1]> show create table student;
+---------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+---------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| student | CREATE TABLE `student` (
`id` int unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(20) NOT NULL,
`age` tinyint unsigned DEFAULT NULL,
`gender` enum('M','F') DEFAULT 'M',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=12 DEFAULT CHARSET=utf8 |
+---------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
范例:查看表状态
03:09:06(root@localhost) [db1]> show table status like 'student'\G
*************************** 1. row ***************************
Name: student
Engine: InnoDB
Version: 10
Row_format: Dynamic
Rows: 2
Avg_row_length: 8192
Data_length: 16384
Max_data_length: 0
Index_length: 0
Data_free: 0
Auto_increment: 12
Create_time: 2021-01-31 14:46:57
Update_time: 2021-01-31 14:49:35
Check_time: NULL
Collation: utf8_general_ci
Checksum: NULL
Create_options:
Comment:
1 row in set (0.01 sec)
查看库中所有表状态
SHOW TABLE STATUS FROM db_name
范例:
03:09:56(root@localhost) [db1]> show table status from db1\G
3.5.3 修改和删除表
修改表
ALTER TABLE 'tbl_name'
#字段:
#添加字段:add
ADD col1 data_type [FIRST|AFTER col_name]
#删除字段:drop
#修改字段:
alter(默认值), change(字段名), modify(字段属性)
查看修改表帮助
Help ALTER TABLE
删除表
DROP TABLE [IF EXISTS] 'tbl_name';
修改表范例
ALTER TABLE students RENAME s1;
ALTER TABLE s1 ADD phone varchar(11) AFTER name;
ALTER TABLE s1 MODIFY phone int;
ALTER TABLE s1 CHANGE COLUMN phone mobile char(11);
ALTER TABLE s1 DROP COLUMN mobile;
ALTER TABLE s1 character set utf8;
ALTER TABLE s1 change name name varchar(20) character set utf8;
ALTER TABLE students ADD gender ENUM('m','f');
ALETR TABLE students CHANGE id sid int UNSIGNED NOT NULL PRIMARY KEY;
ALTER TABLE students DROP age;
DESC students;
#新建表无主键,添加和删除主键
CREATE TABLE t1 SELECT * FROM students;
ALTER TABLE t1 add primary key (stuid);
ALTER TABLE t1 drop primary key ;
3.6 DML 语句
DML: INSERT, DELETE, UPDATE
3.6.1 INSERT 语句
功能:一次插入一行或多行数据
语法
INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name [(col_name,...)]
{VALUES | VALUE} ({expr | DEFAULT},...),(...),...
[ ON DUPLICATE KEY UPDATE #如果重复更新之
col_name=expr
[, col_name=expr] ... ]
INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name
SET col_name={expr | DEFAULT}, ...
[ ON DUPLICATE KEY UPDATE
col_name=expr
[, col_name=expr] ... ]
INSERT [LOW_PRIORITY | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name [(col_name,...)]
SELECT ...
[ ON DUPLICATE KEY UPDATE
col_name=expr
[, col_name=expr] ... ]
简化写法:
INSERT tbl_name [(col1,...)] VALUES (val1,...), (val21,...)
3.6.2 UPDATE 语句
语法:
UPDATE [LOW_PRIORITY] [IGNORE] table_reference
SET col_name1={expr1|DEFAULT} [, col_name2={expr2|DEFAULT}] ...
[WHERE where_condition]
[ORDER BY ...]
[LIMIT row_count]
注意:一定要有限制条件,否则将修改所有行的指定字段
可利用mysql 选项避免此错误:
mysql -U | --safe-updates| --i-am-a-dummy
[root@centos8 ~]#vim /etc/my.cnf
[mysql]
safe-updates
4.6.3 DELETE 语句
删除表中数据,但不会自动缩减数据文件的大小。
语法:
DELETE [LOW_PRIORITY] [QUICK] [IGNORE] FROM tbl_name
[WHERE where_condition]
[ORDER BY ...]
[LIMIT row_count]
#可先排序再指定删除的行数
注意:一定要有限制条件,否则将清空表中的所有数据
如果想清空表,保留表结构,也可以使用下面语句,此语句会自动缩减数据文件的大小。
TRUNCATE TABLE tbl_name;
缩减表大小
OPTIMIZE TABLE tb_name
3.7 DQL 语句
3.7.1 单表操作
语法:
SELECT
[ALL | DISTINCT | DISTINCTROW ]
[SQL_CACHE | SQL_NO_CACHE]
select_expr [, select_expr ...]
[FROM table_references
[WHERE where_condition]
[GROUP BY {col_name | expr | position}
[ASC | DESC], ... [WITH ROLLUP]]
[HAVING where_condition]
[ORDER BY {col_name | expr | position}
[ASC | DESC], ...]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
[FOR UPDATE | LOCK IN SHARE MODE]
说明:
-
字段显示可以使用别名:
- col1 AS alias1, col2 AS alias2, ...
-
WHERE子句:指明过滤条件以实现"选择"的功能:
- 过滤条件:布尔型表达式
-
算术操作符:+, -, *, /, %
-
比较操作符:=,<=>(相等或都为空), <>, !=(非标准SQL), >, >=, <, <=
-
BETWEEN min_num AND max_num,一般用于去范围条件
-
IN (element1, element2, ...),一般用于取几个条件也就是或者
-
IS NULL, IS NOT NULL,判断空值
-
DISTINCT 去除重复行,范例:SELECT DISTINCT gender FROM students;
-
LIKE: % 任意长度的任意字符 _ 任意单个字符
-
RLIKE:正则表达式,索引失效,不建议使用
-
REGEXP:匹配字符串可用正则表达式书写模式,同上
-
逻辑操作符:NOT,AND,OR,XOR
-
GROUP:根据指定的条件把查询结果进行"分组"以用于做"聚合"运算
- 常见聚合函数:avg(), max(), min(), count(), sum()
- HAVING: 对分组聚合运算后的结果指定过滤条件
- 一旦分组group by ,select语句后只跟分组的字段,聚合函数
-
ORDER BY: 根据指定的字段对查询结果进行排序
- 升序:ASC
- 降序:DESC
-
LIMIT [[offset,]row_count]:对查询的结果进行输出行数数量限制
-
对查询结果中的数据请求施加"锁
- FOR UPDATE: 写锁,独占或排它锁,只有一个读和写操作
- LOCK IN SHARE MODE: 读锁,共享锁,同时多个读操作
范例:密码生成
mariadb root@(none):(none)> select password("zhangzhuo");
+-------------------------------------------+
| password("zhangzhuo") |
+-------------------------------------------+
| *E537F5F82C1F36D566632B4C9061BD6715BABF7C |
+-------------------------------------------+
1 row in set
Time: 0.013s
范例:简单查询
#查看表结构
mysql root@(none):hellodb> desc students
#插入数据
mysql root@(none):hellodb> insert into students values(1,'tom','m'),(2,'alice','f');
mysql root@(none):hellodb> select * from students where `StuID` <3;
mysql root@(none):hellodb> select * from students where `Gender`='m';
#查询字段空值或非空值
mysql root@(none):hellodb> select * from students where `ClassID` is null;
mysql root@(none):hellodb> select * from students where `ClassID` is not null;
#分组后降序排序查询前2行
mysql root@(none):hellodb> select * from students order by name desc limit 2;
#分组后降序排序查询跳过第一行查询后2行
mysql root@(none):hellodb> select * from students order by name desc limit 1,2;
#范围查询俩种方式
mysql root@(none):hellodb> select * from students where `StuID` >=2 and `StuID` <=4;
mysql root@(none):hellodb> select * from students where `StuID` between 2 and 4;
#模糊查询
mysql root@(none):hellodb> select * from students where name like 't%';
#正则表达式查询
mysql root@(none):hellodb> select * from students where name rlike '.*[lo].*';
#查询结果命名别名
mysql root@(none):hellodb> select `StuID` id,name as stuname from students;
#包含查询
mysql root@(none):hellodb> select * from students where `ClassID` in (1,3,5);
mysql root@(none):hellodb> select * from students where `ClassID` not in (1,3,5);
范例:判断是否为NULL俩种方式或者不为NULL
mysql root@(none):hellodb> select * from students where `ClassID` is null;
+-------+-------------+-----+--------+---------+-----------+
| StuID | Name | Age | Gender | ClassID | TeacherID |
+-------+-------------+-----+--------+---------+-----------+
| 24 | Xu Xian | 27 | M | | |
| 25 | Sun Dasheng | 100 | M | | |
+-------+-------------+-----+--------+---------+-----------+
2 rows in set
Time: 0.007s
mysql root@(none):hellodb> select * from students where `ClassID` <=> null;
+-------+-------------+-----+--------+---------+-----------+
| StuID | Name | Age | Gender | ClassID | TeacherID |
+-------+-------------+-----+--------+---------+-----------+
| 24 | Xu Xian | 27 | M | | |
| 25 | Sun Dasheng | 100 | M | | |
+-------+-------------+-----+--------+---------+-----------+
2 rows in set
Time: 0.007s
#不为空的
mysql root@(none):hellodb> select * from students where `ClassID` is not null;
范例:去重
mysql root@(none):hellodb> select distinct gender from students;
+--------+
| gender |
+--------+
| M |
| F |
+--------+
2 rows in set
Time: 0.008s
范例:分组统计
#查看每个班级中人数
mysql root@(none):hellodb> select `ClassID`,count(*) from students group by classid;
+---------+----------+
| ClassID | count(*) |
+---------+----------+
| 2 | 3 |
| 1 | 4 |
| 4 | 4 |
| 3 | 4 |
| 5 | 1 |
| 7 | 3 |
| 6 | 4 |
| | 2 |
+---------+----------+
8 rows in set
Time: 1.634s
#查看每个班级中男生女生分别的人数
mysql root@(none):hellodb> select `ClassID`,`Gender`,count(*) as 数量 from students group by classid,ge
-> nder
+---------+--------+------+
| ClassID | Gender | 数量 |
+---------+--------+------+
| 2 | M | 3 |
| 1 | M | 2 |
| 4 | M | 4 |
| 3 | M | 1 |
| 5 | M | 1 |
| 3 | F | 3 |
| 7 | F | 2 |
| 6 | F | 3 |
| 6 | M | 1 |
| 1 | F | 2 |
| 7 | M | 1 |
| | M | 2 |
+---------+--------+------+
12 rows in set
Time: 0.007s
#统计班级编号大于3的且班级中平均年纪大于30的班级
mysql root@(none):hellodb> select classid,avg(age) as 平均年龄 from students where `ClassID` >3 group b
-> y classid having 平均年龄 >30;
+---------+----------+
| classid | 平均年龄 |
+---------+----------+
| 5 | 46.0000 |
+---------+----------+
1 row in set
Time: 0.008s
#统计学生表中男生的平均年龄
mysql root@(none):hellodb> select gender,avg(age) 平均年龄 from students group by gender having `Gender -> `='M';
#多个字段分组统计,分组在前在后不影响结果
mysql root@(none):hellodb> select classid,gender,count(*) 数量 from students group by classid,gender;
mysql root@(none):hellodb> select classid,gender,count(*) 数量 from students group by gender,classid;
#注意:一旦使用分组group by,在select 后面的只能采用分组的列和聚合函数,其它的列不能放在select后面,否则根据系统变量SQL_MODE的值不同而不同的结果
范例:排序
#年龄按降序排序取前三个
mysql root@(none):hellodb> select * from students order by `Age` desc limit 3;
#年龄按降序排序跳过前三个取后续的2个
mysql root@(none):hellodb> select * from students order by `Age` desc limit 3,2;
#按班级id字段非空分组后年龄求和后按班级id升序排序,分组前排除班级id字段是null的
mysql root@(none):hellodb> select classid,sum(age) from students where `ClassID` is not null group by c
-> lassid order by `ClassID`;
#按班级id字段非空分组后年龄求和后按班级id升序排序,分组后排除班级id字段是null的
mysql root@(none):hellodb> select classid,sum(age) from students group by classid having classid is not
-> null order by `ClassID`;
#按班级id字段非空分组后年龄求和后按班级id升序排序跳过前2个取后续的3个
mysql root@(none):hellodb> select classid,sum(age) from students where `ClassID` is not null group by c
-> lassid order by `ClassID` limit 2,3;
#过滤班级id是null的按性别降序排序后年龄按升序排序
mysql root@(none):hellodb> select * from students where `ClassID` is not null order by `Gender` desc,ag
-> e asc;
#多列排序,按性别降序排序后年龄按升序排序
mysql root@(none):hellodb> select * from students order by `Gender` desc,age asc;
范例:分组和排序
#按班级id分组,统计各个班级数量后,数量按升序排序
mysql root@(none):hellodb> select classid,count(*) 数量 from students group by classid order by 数量;
#以性别和班级分组排除班级id是空的,求他们的平均年龄后,按照性别先升序排序在按照班级id升序排序
mysql root@(none):hellodb> select gender,classid,avg(age) from students where `ClassID` is not null gro
-> up by gender,classid order by `Gender`,`ClassID`;
#按照年龄升序排序取前10个
mysql root@(none):hellodb> select * from students order by `Age` limit 10;
#按照年龄升序排序跳过前3个取后续的10个
mysql root@(none):hellodb> select * from students order by `Age` limit 3,10;
#先对年龄去重后年龄按照升序排序后取前3个
mysql root@(none):hellodb> select distinct age from students order by `Age` limit 3;
#先对年龄去重后年龄按照升序排序后跳过前3个取后续的5个
mysql root@(none):hellodb> select distinct age from students order by age limit 3,5;
#分组和排序的次序group by,having,order by
#以下顺序会出错,group by,order by,having
#以下顺序会出错,order by,group by,having
范例:时间字段进行过滤查询,并且timestamp可以随其它字段的更新自动更新
mysql root@(none):hellodb> create table testdata (id int auto_increment primary key,date timestamp defa
-> ult current_timestamp on update current_timestamp );
mysql root@(none):hellodb> insert into testdata () values(),(),();
mysql root@(none):hellodb> select * from testdata;
+----+---------------------+
| id | date |
+----+---------------------+
| 1 | 2021-02-04 14:47:34 |
| 2 | 2021-02-04 14:47:34 |
| 3 | 2021-02-04 14:47:34 |
+----+---------------------+
mysql root@(none):hellodb> select * from testdata where `date` between '2021-02-04 14:40:00' and '2021-
-> 02-04 14:50:00';
+----+---------------------+
| id | date |
+----+---------------------+
| 1 | 2021-02-04 14:47:34 |
| 2 | 2021-02-04 14:47:34 |
| 3 | 2021-02-04 14:47:34 |
+----+---------------------+
#修改其它字段,会自动更新timestamp字段
mysql root@(none):hellodb> update testdata set id=10 where id=1;
Query OK, 1 row affected
Time: 0.002s
mysql root@(none):hellodb> select * from testdata;
+----+---------------------+
| id | date |
+----+---------------------+
| 2 | 2021-02-04 14:52:34 |
| 3 | 2021-02-04 14:52:34 |
| 4 | 2021-02-04 14:52:38 |
| 5 | 2021-02-04 14:52:39 |
| 10 | 2021-02-04 14:53:07 |
+----+---------------------+
5 rows in set
Time: 0.006s
3.7.2 多表查询
多表查询,即查询结果来自于多张表
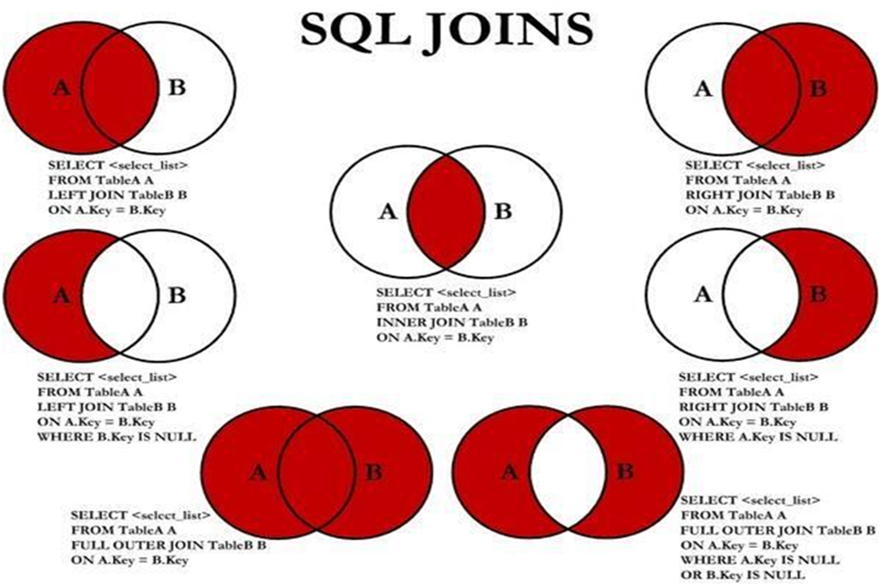
-
子查询:在SQL语句嵌套着查询语句,性能较差,基于某语句的查询结果再次进行的查询
-
联合查询:UNION
-
交叉连接:笛卡尔乘积 CROSS JOIN
-
内连接:
- 等值连接:让表之间的字段以"等值"建立连接关系
- 不等值连接
- 自然连接:去掉重复列的等值连接 , 语法: FROM table1 NATURAL JOIN table2;
-
外连接:
- 左外连接:FROM tb1 LEFT JOIN tb2 ON tb1.col=tb2.col
- 右外连接:FROM tb1 RIGHT JOIN tb2 ON tb1.col=tb2.col
- 完全外连接: FROM tb1 FULL OUTER JOIN tb2 ON tb1.col=tb2.col 注意:MySQL 不支持此SQL语法
-
自连接:本表和本表进行连接查询
3.7.2.1 子查询
子查询 subquery 即SQL语句调用另一个SELECT子句,可以是对同一张表,也可以是对不同表,主要有以下四种常见的用法:
- 用于比较表达式中的子查询;子查询仅能返回单个值
#查询学生表中年龄大于老师表中平均年龄
mysql root@(none):hellodb> select name,age from students where `Age`>(select avg(`Age`) from teachers);
- 用于IN中的子查询:子查询应该单独查询并返回一个或多个值重新构成列表
#查询学生表中年龄和老师表中年龄一致的
mysql root@(none):hellodb> select name,age from students where age in(select age from teachers);
- 用于EXISTS 和 Not EXISTS
参考链接:https://dev.mysql.com/doc/refman/8.0/en/exists-and-not-exists-subqueries.html
EXISTS(包括 NOT EXISTS )子句的返回值是一个BOOL值。 EXISTS 内部有一个子查询语句(SELECT... FROM...), 将其称为EXIST的内查询语句。其内查询语句返回一个结果集。 EXISTS子句根据其内查询语句的结果集空或者非空,返回一个布尔值。将外查询表的每一行,代入内查询作为检验,如果内查询返回的结果为非空值,则EXISTS子句返回TRUE,外查询的这一行数据便可作为外查询的结果行返回,否则不能作为结果
#查询学生表中有对应老师的学生
mysql root@(none):hellodb> select * from students s where exists (select * from teachers t where s.`Tea -> cherID`=t.`TID`);
+-------+-------------+-----+--------+---------+-----------+
| StuID | Name | Age | Gender | ClassID | TeacherID |
+-------+-------------+-----+--------+---------+-----------+
| 1 | Shi Zhongyu | 22 | M | 2 | 3 |
| 4 | Ding Dian | 32 | M | 4 | 4 |
| 5 | Yu Yutong | 26 | M | 3 | 1 |
+-------+-------------+-----+--------+---------+-----------+
#说明:
1. EXISTS (或 NOT EXISTS) 用在 where之后,且后面紧跟子查询语句(带括号)
2. EXISTS (或 NOT EXISTS) 只关心子查询有没有结果,并不关心子查询的结果具体是什么
3. 上述语句把students的记录逐条代入到Exists后面的子查询中,如果子查询结果集不为空,即说明存在,那么这条students的记录出现在最终结果集,否则被排除
#查询学生表中无对应老师的学生
mysql root@(none):hellodb> select * from students s where not exists(select * from teachers t where s.` -> TeacherID`=t.tid);
+-------+---------------+-----+--------+---------+-----------+
| StuID | Name | Age | Gender | ClassID | TeacherID |
+-------+---------------+-----+--------+---------+-----------+
| 2 | Shi Potian | 22 | M | 1 | 7 |
| 3 | Xie Yanke | 53 | M | 2 | 16 |
| 6 | Shi Qing | 46 | M | 5 | |
| 7 | Xi Ren | 19 | F | 3 | |
| 8 | Lin Daiyu | 17 | F | 7 | |
| 9 | Ren Yingying | 20 | F | 6 | |
| 10 | Yue Lingshan | 19 | F | 3 | |
| 11 | Yuan Chengzhi | 23 | M | 6 | |
| 12 | Wen Qingqing | 19 | F | 1 | |
| 13 | Tian Boguang | 33 | M | 2 | |
| 14 | Lu Wushuang | 17 | F | 3 | |
| 15 | Duan Yu | 19 | M | 4 | |
| 16 | Xu Zhu | 21 | M | 1 | |
| 17 | Lin Chong | 25 | M | 4 | |
| 18 | Hua Rong | 23 | M | 7 | |
| 19 | Xue Baochai | 18 | F | 6 | |
| 20 | Diao Chan | 19 | F | 7 | |
| 21 | Huang Yueying | 22 | F | 6 | |
| 22 | Xiao Qiao | 20 | F | 1 | |
| 23 | Ma Chao | 23 | M | 4 | |
| 24 | Xu Xian | 27 | M | | |
| 25 | Sun Dasheng | 100 | M | | |
+-------+---------------+-----+--------+---------+-----------+
- 用于FROM子句中的子查询
使用格式:
SELECT tb_alias.col1,... FROM (SELECT clause) AS tb_alias WHERE Clause;
范例:
mysql root@(none):hellodb> select s.classid,s.aage from (select classid,avg(age) as aage from students
-> where `ClassID` is not null group by classid) as s where s.aage>30;
范例:子查询
#子查询:select 的执行结果,被其它SQL调用#查询学生表中学生年龄大于老师平均年龄的学生mysql root@(none):hellodb> select `StuID`,`Name`,`Age` from students where age > (select avg(age) from-> teachers);
范例:子查询用于更新表
mysql root@(none):hellodb> update teachers set age=(select avg(age) from students) where `TID`=4;
mysql root@(none):hellodb> select * from teachers;
+-----+---------------+-----+--------+
| TID | Name | Age | Gender |
+-----+---------------+-----+--------+
| 1 | Song Jiang | 45 | M |
| 2 | Zhang Sanfeng | 94 | M |
| 3 | Miejue Shitai | 77 | F |
| 4 | Lin Chaoying | 27 | F |
+-----+---------------+-----+--------+
3.7.2.2 联合查询
联合查询 Union 实现的条件,多个表的字段数量相同,字段名和数据类型可以不同,但一般数据类型是相同的
SELECT Name,Age FROM students UNION SELECT Name,Age FROM teachers;
范例:联合查询
#多表联合查询,联合查询的表必须字段数相同
select tid as id,name,age,gender from teachers union select stuid,name,age,gender from students;
#如果是相同的表不会显示相同的信息
select * from teachers union select * from teachers;
#如果想显示相同的信息需要在union后面加all
select * from teachers union all select * from teachers;
范例:去重
#除去查询结果中的重复记录的distinct
select distinct * from teachers;
#联合查询默认是去重的union all不去重
3.7.2.3 交叉连接
cross join 即多表的记录之间做笛卡尔乘积组合,并且多个表的列横向合并相加, "雨露均沾"
比如: 第一个表3行4列,第二个表5行6列,cross join后的结果为3*5=15行,4+6=10列
交叉连接生成的记录可能会非常多,建议慎用
范例:交叉连接
#横向合并,交叉连接(横向笛卡尔)
#俩种写法
select * from students cross join teachers;
select * from students,teachers;
3.7.2.4 内连接
inner join 内连接取多个表的交集
范例:内连接
#内连接inner join
#查询学生表中代课老师id和老师表老师id相同的数据把他们连接起来,俩种写法
select * from students inner join teachers on students.teacherid=teachers.tid;
select * from students,teachers where students.teacherid=teachers.tid;
#如果表定义了别名,原表名将无法使用
select stuid,s.name as student_name,tid,t.name as teacher_name from students as s inner join teachers as t on s.teacherid=t.tid;
#查询学生性别和老师性别不相等的,由于老师有多个学生有多个每个学生都会与老师进行比较不相等的都会显示
select s.name 学生姓名,s.age 学生年龄,s.gender 学生性别,t.name 老师姓名,t.age 老师年龄,t.gender 老师性别 from students s,teachers t where s.`Gender` <> t.`Gender`;
#内连接后过滤数据
#查询学生表有代课老师的学生并且年龄大于30的人与想对应的老师数据进行内连接
select * from students s inner join teachers t on s.`TeacherID`=t.tid and s.age >30;
自然连接
- 当源表和目标表共享相同名称的列时,就可以在它们之间执行自然连接,而无需指定连接列。
- 在使用纯自然连接时,如没有相同的列时,会产生交叉连接(笛卡尔乘积)
- 语法:(SQL:1999)SELECT table1.column, table2.column FROM table1 NATURAL JOIN table2;
3.7.2.5 左和右外连接
范例:左,右外连接
#左外连接
select * from students as s left outer join teachers as t on s.`TeacherID`=t.tid;
#左外连接扩展
select * from students as s left outer join teachers as t on s.`TeacherID`=t.tid where t.tid is null;
#多个条件的左外连接
select * from students as s left outer join teachers as t on s.`TeacherID`=t.tid and s.`TeacherID` is null;
#先左外连接,再过滤
select * from students as s left outer join teachers as t on s.`TeacherID`=t.tid where s.`TeacherID` is null;
#右外连接
select * from students s right outer join teachers t on s.`TeacherID`=t.tid;
#右外连接的扩展用法
select * from students s right outer join teachers t on s.`TeacherID`=t.tid where s.`TeacherID` is null;
3.7.2.6 完全外连接
MySQL 不支持完全外连接full outer join语法
#MySQL不支持完全外连接 full outer join,利用以下方式法代替
select * from students left join teachers on students.`TeacherID`=teachers.tid union select * from students right join teachers on students.`TeacherID`=teachers.tid;
3.7.2.7 自连接
自连接, 即表自身连接自身
范例:自连接
#自连接
select * from teachers;
select e.name,l.name from teachers as e inner join teachers as l on e.`TID`=l.tid;
3.7.3 SELECT 语句处理的顺序
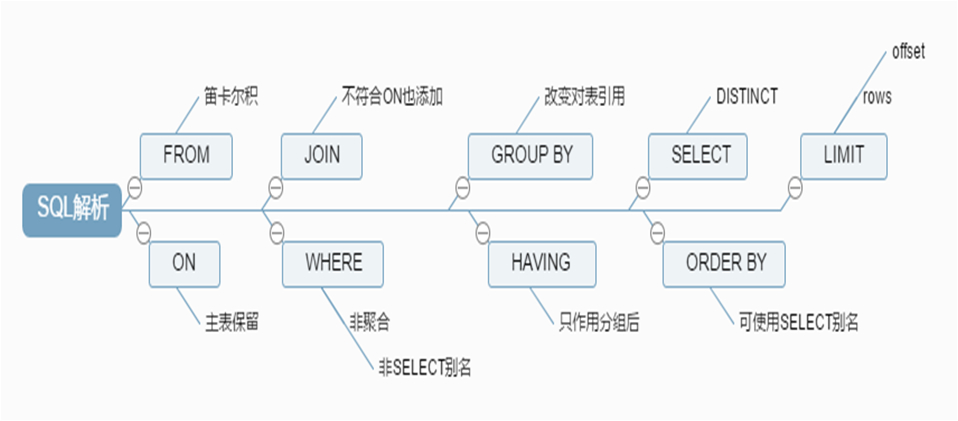
查询执行路径中的组件:查询缓存、解析器、预处理器、优化器、查询执行引擎、存储引擎
SELECT语句的执行流程:
FROM Clause --> WHERE Clause --> GROUP BY --> HAVING Clause -->SELECT -->ORDER BY --> LIMIT
3.8 VIEW视图
视图:虚拟表,保存有实表的查询结果,相当于别名
利用视图,可以隐藏表的真实结构,在程序中利用视图进行查询,可以避免表结构的变化,而修改程序,降低程序和数据库之间的耦合度
创建方法:
CREATE VIEW view_name [(column_list)]
AS select_statement
[WITH [CASCADED | LOCAL] CHECK OPTION]
查看视图定义:
SHOW CREATE VIEW view_name #只能看视图定义
SHOW CREATE TABLE view_name # 可以查看表和视图
删除视图:
DROP VIEW [IF EXISTS]
view_name [, view_name] ...
[RESTRICT | CASCADE]
注意:视图中的数据事实上存储于"基表"中,因此,其修改操作也会针对基表实现;其修改操作受基表限制
范例:
create view v_st_co_sc as select st.name,co.course,sc.score from students st inner join scores sc on st.`StuID`=sc.stuid inner join courses co on sc.courseid=co.courseid;
show table status like 'v_st_co_sc'\G
select * from v_st_co_sc;
3.9 FUNCTION 函数
函数:分为系统内置函数和自定义函数
- 系统内置函数参考:
https://dev.mysql.com/doc/refman/8.0/en/sql-function-reference.html
https://dev.mysql.com/doc/refman/5.7/en/sql-function-reference.html
- 自定义函数:user-defined function UDF,保存在mysql.proc (MySQL8.0 中已经取消此表)表中
创建UDF语法
CREATE [AGGREGATE] FUNCTION function_name(parameter_name type,[parameter_name
type,...])
RETURNS {STRING|INTEGER|REAL}
runtime_body
说明:
- 参数可以有多个,也可以没有参数
- 无论有无参数,小括号()是必须的
- 必须有且只有一个返回值
查看函数列表:
SHOW FUNCTION STATUS;
查看函数定义
SHOW CREATE FUNCTION function_name
删除UDF
DROP FUNCTION function_name
调用自定义函数语法
SELECT function_name(parameter_value,...)
范例:MySQL8.0 默认开启二进制不允许创建函数
#默认MySQL8.0开启二进制日志,而不允许创建函数
CREATE FUNCTION simpleFun() RETURNS VARCHAR(20) RETURN "Hello World";
(1418, 'This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA in its declaration and binary logging is enabled (you *might* want to use the less safe log_bin_trust_function_creators variable)')
mysql root@(none):hellodb> select @@log_bin;
+-----------+
| @@log_bin |
+-----------+
| 1 |
+-----------+
1 row in set
Time: 0.006s
mysql root@(none):hellodb> show variables like 'log_bin_trust_function_creators';
+---------------------------------+-------+
| Variable_name | Value |
+---------------------------------+-------+
| log_bin_trust_function_creators | OFF |
+---------------------------------+-------+
1 row in set
Time: 0.014s
#打开此变量允许二进制日志信息函数创建
set global log_bin_trust_function_creators=ON;
CREATE FUNCTION simpleFun() RETURNS VARCHAR(20) RETURN "Hello World";
show function status like 'simple%'\G
#Mariadb10.3 默认没有开启二进制日志,所以可以创建函数
MySQL中的变量
两种变量:系统内置变量和用户自定义变量
- 系统变量:MySQL数据库中内置的变量,可用@@var_name引用
#系统变量mysql8.0版本帮助查询地址
https://dev.mysql.com/doc/refman/8.0/en/server-option-variable-reference.html
- 用户自定义变量分为以下两种
- 普通变量:在当前会话中有效,可用@var_name引用
- 局部变量:在函数或存储过程内才有效,需要用DECLARE 声明,之后直接用 var_name引用
自定义函数中定义局部变量语法
DECLARE 变量1[,变量2,... ]变量类型 [DEFAULT 默认值]
说明:局部变量的作用范围是在BEGIN...END程序中,而且定义局部变量语句必须BEGIN...END的第一行定义
为变量赋值语法
SET parameter_name = value[,parameter_name = value...]
SELECT INTO parameter_name
范例:自定义的普通变量
select count(*) from `成绩表` into @num;
select count(*) into @num from `成绩表` ;
select @num;
+------+
| @num |
+------+
| 16 |
+------+
3.10 PROCEDURE 存储过程
存储过程:多表SQL的语句的集合,可以独立执行,存储过程保存在mysql.proc表中
存储过程优势
存储过程把经常使用的SQL语句或业务逻辑封装起来,预编译保存在数据库中,当需要时从数据库中直接调用,省去了编译的过程,提高了运行速度,同时降低网络数据传输量
存储过程与自定义函数的区别
存储过程实现的过程要复杂一些,而函数的针对性较强
存储过程可以有多个返回值,而自定义函数只有一个返回值
存储过程一般可独立执行,而函数往往是作为其他SQL语句的一部分来使用
无参数的存储过程执行过程中可以不加(),函数必须加 ( )
创建存储过程
CREATE PROCEDURE sp_name ([ proc_parameter [,proc_parameter ...]])
routime_body
proc_parameter : [IN|OUT|INOUT] parameter_name type
说明:其中IN表示输入参数,OUT表示输出参数,INOUT表示既可以输入也可以输出;param_name表示参数名称;type表示参数的类型
查看存储过程列表
SHOW PROCEDURE STATUS;
查看存储过程定义
SHOW CREATE PROCEDURE sp_name
调用存储过程
CALL sp_name ([ proc_parameter [,proc_parameter ...]])
说明:当无参时,可以省略"()",当有参数时,不可省略"()
存储过程修改
ALTER语句修改存储过程只能修改存储过程的注释等无关紧要的东西,不能修改存储过程体,所以要修改存储过程,方法就是删除重建
删除存储过程
DROP PROCEDURE [IF EXISTS] sp_name
范例:创建无参存储过程
mysql> delimiter //
mysql> create procedure showTime()
-> BEGIN
-> select now();
-> END//
Query OK, 0 rows affected (0.00 sec)
mysql> delimiter ;
mysql> call showTime;
+---------------------+
| now() |
+---------------------+
| 2021-03-01 21:02:06 |
+---------------------+
1 row in set (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
#delimiter作用修改SQL语句默认结束符
范例:创建含参存储过程:只有一个IN参数
mysql> delimiter //
mysql> create procedure selectById(IN id SMALLINT unsigned)
-> BEGIN
-> select * from students where stuid = id;
-> END//
Query OK, 0 rows affected (0.00 sec)
mysql> delimiter ;
mysql> call selectById(2);
+-------+------------+-----+--------+---------+-----------+
| StuID | Name | Age | Gender | ClassID | TeacherID |
+-------+------------+-----+--------+---------+-----------+
| 2 | Shi Potian | 22 | M | 1 | 7 |
+-------+------------+-----+--------+---------+-----------+
1 row in set (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
流程控制
存储过程和函数中可以使用流程控制来控制语句的执行
- IF:用来进行条件判断。根据是否满足条件,执行不同语句
- CASE:用来进行条件判断,可实现比IF语句更复杂的条件判断
- LOOP:重复执行特定的语句,实现一个简单的循环
- LEAVE:用于跳出循环控制,相当于SHELL中break
- ITERATE:跳出本次循环,然后直接进入下一次循环,相当于SHELL中continue
- REPEAT:有条件控制的循环语句。当满足特定条件时,就会跳出循环语句
- WHILE:有条件控制的循环语句
3.11 TRIGGER 触发器
触发器的执行不是由程序调用,也不是由手工启动,而是由事件来触发、激活从而实现执行
创建触发器
CREATE [DEFINER = { user | CURRENT_USER }]
TRIGGER trigger_name
trigger_time trigger_event
ON tbl_name FOR EACH ROW
trigger_body
说明:
trigger_name:触发器的名称
trigger_time:{ BEFORE | AFTER },表示在事件之前或之后触发
trigger_event::{ INSERT |UPDATE | DELETE },触发的具体事件
tbl_name:该触发器作用在表名
范例:
#创建触发器,在向学生表INSERT数据时,学生数增加,DELETE学生时,学生数减少
create table student_info( stu_id int(11) not null auto_increment, stu_name varchar(255) default null, primary key (stu_id) );
create table student_count( student_count int(11) default 0 );
insert into student_count values(0);
#增加一个学生信息,学生人数表+1
create trigger trigger_student_count_insert after insert on student_info for each row update student_count set student_count=student_count+1;
#减少一个学生信息,学生人数表-1
create trigger trigger_student_count_delete after delete on student_info for each row update student_count set student_count=student_count-1;
查看触发器
#在当前数据库对应的目录下,可以查看到新生成的相关文件:trigger_name.TRN,table_name.TRG
SHOW TRIGGERS;
#查询系统表information_schema.triggers的方式指定查询条件,查看指定的触发器信息。
USE information_schema;
SELECT * FROM triggers WHERE trigger_name='trigger_student_count_insert';
删除触发器
DROP TRIGGER trigger_name;
3.12 Event 事件
3.12.1 Event 事件介绍
事件(event)是MySQL在相应的时刻调用的过程式数据库对象。一个事件可调用一次,也可周期性的启动,它由一个特定的线程来管理的,也就是所谓的"事件调度器"。
事件和触发器类似,都是在某些事情发生的时候启动。当数据库上启动一条语句的时候,触发器就启动了,而事件是根据调度事件来启动的。由于它们彼此相似,所以事件也称为临时性触发器。
事件取代了原先只能由操作系统的计划任务来执行的工作,而且MySQL的事件调度器可以精确到每秒钟执行一个任务,而操作系统的计划任务(如:Linux下的CRON或Windows下的任务计划)只能精确到每分钟执行一次。
事件的优缺点
优点:一些对数据定时性操作不再依赖外部程序,而直接使用数据库本身提供的功能,可以实现每秒钟执行一个任务,这在一些对实时性要求较高的环境下就非常实用
缺点:定时触发,不可以直接调用
3.12.2 Event 管理
3.12.2.1 相关变量和服务器选项
MySQL事件调度器event_scheduler负责调用事件,它默认是关闭的。这个调度器不断地监视一个事件
是否要调用, 要创建事件,必须打开调度器
服务器系统变量和服务器选项:
event_scheduler:默认值为OFF,设置为ON才支持Event,并且系统自动打开专用的线程
范例:开启和关闭event_scheduler
#默认事件调度功能是关闭的
mysql> select @@event_scheduler;
+-------------------+
| @@event_scheduler |
+-------------------+
| OFF |
+-------------------+
1 row in set (0.00 sec)
#临时开启事件调度功能
set global event_schediler=1;
#开启事件调度功能后,自启动一个event_scheduler线程
mysql> mysql> show processlist;
+----+-----------------+-----------+------+---------+------+------------------------+------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+-----------------+-----------+------+---------+------+------------------------+------------------+
| 5 | event_scheduler | localhost | NULL | Daemon | 2717 | Waiting on empty queue | NULL |
| 13 | root | localhost | db1 | Query | 0 | starting | show processlist |
+----+-----------------+-----------+------+---------+------+------------------------+------------------+
2 rows in set (0.00 sec)
#临时关闭事件调度功能
set global event_scheduler=0;
#持久开启事件调度
[root@centos8 ~]#vim /etc/my.cnf.d/mariadb-server.cnf
[mysqld]
event_scheduler=ON
[root@centos8 ~]#systemctl restart mysqld
3.12.2.2 管理事件
create event 语句创建一个事件。每个事件由两个主要部分组成,第一部分是事件调度(eventschedule),表示事件何时启动以及按什么频率启动,第二部分是事件动作(event action ),这是事件启动时执行的代码,事件的动作包含一条SQL语句,它可能是一个简单地insert或者update语句,也可以使一个存储过程或者 benin...end语句块,这两种情况允许我们执行多条SQL
一个事件可以是活动(打开)的或停止(关闭)的,活动意味着事件调度器检查事件动作是否必须调用,停止意味着事件的声明存储在目录中,但调度器不会检查它是否应该调用。在一个事件创建之后,它立即变为活动的,一个活动的事件可以执行一次或者多次
创建Event
CREATE
[DEFINER = { user | CURRENT_USER }]
EVENT
[IF NOT EXISTS]
event_name
ON SCHEDULE schedule
[ON COMPLETION [NOT] PRESERVE]
[ENABLE | DISABLE | DISABLE ON SLAVE]
[COMMENT 'comment']
DO event_body;
schedule:
AT timestamp [+ INTERVAL interval] ...
| EVERY interval
[STARTS timestamp [+ INTERVAL interval] ...]
[ENDS timestamp [+ INTERVAL interval] ...]
interval:
quantity {YEAR | QUARTER | MONTH | DAY | HOUR | MINUTE |
WEEK | SECOND | YEAR_MONTH | DAY_HOUR | DAY_MINUTE |
DAY_SECOND | HOUR_MINUTE | HOUR_SECOND | MINUTE_SECOND}
说明:
event_name :创建的event名字,必须是唯一确定的
ON SCHEDULE:计划任务
schedule: 决定event的执行时间和频率(注意时间一定要是将来的时间,过去的时间会出错),有两种形式 AT和EVERY
[ON COMPLETION [NOT] PRESERVE]: 可选项,默认是ON COMPLETION NOT PRESERVE 即计划任务执行完毕后自动drop该事件;ON COMPLETION PRESERVE则不会drop掉
[COMMENT 'comment'] :可选项,comment 用来描述event;相当注释,最大长度64个字节
[ENABLE | DISABLE] :设定event的状态,默认ENABLE:表示系统尝试执行这个事件, DISABLE:关闭该事情,可以用alter修改
DO event_body: 需要执行的sql语句,可以是复合语句
提示:event事件是存放在mysql.event表中
查看Event
SHOW EVENTS [{FROM | IN} schema_name]
[LIKE 'pattern' | WHERE expr]
注意:事件执行完即释放,如立即执行事件,执行完后,事件便自动删除,多次调用事件或等待执行事件,才可以用上述命令查看到。
修改Event
ALTER
[DEFINER = { user | CURRENT_USER }]
EVENT event_name
[ON SCHEDULE schedule]
[ON COMPLETION [NOT] PRESERVE]
[RENAME TO new_event_name]
[ENABLE | DISABLE | DISABLE ON SLAVE]
[COMMENT 'comment']
[DO event_body]
注意:alter event语句可以修改事件的定义和属性。可以让一个事件成为停止的或者再次让它活动,也可以修改一个事件的名字或者整个调度。然而当一个使用 ON COMPLETION NOT PRESERVE 属性定义的事件最后一次执行后,事件直接就不存在了,不能修改
删除Event
DROP EVENT [IF EXISTS] event_name
3.12.2.3 范例
范例:创建立即启动事件
create database testdb;
use testdb;
#创建一个表记录每次事件调度的名字和事件戳
create table events_list(event_name varchar(20) not null,event_started timestamp not null);
#临时关闭事件调度功能
set global event_scheduler=0;
show variables like 'event_scheduler';
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| event_scheduler | OFF |
+-----------------+-------+
#创建一次性事件
create event event_now on schedule at now() do insert into events_list values('event_now',now());
#因为事件调度功能禁用,所有表中无记录
select * from events_list;
#查看事件
show events\G
#开启事件调度功能
set global event_scheduler=1;
#事件立即执行,每秒插入一条记录
select * from events_list;
#事件执行完成后自动删除
show events;
3.13 MySQL 用户管理
相关数据库和表
元数据数据库:mysql
系统授权表:db, host, user,columns_priv, tables_priv, procs_priv, proxies_priv
用户帐号:
'USERNAME'@'HOST'
@'HOST': 主机名: user1@'web1.magedu.org'
IP地址或Network
通配符: % _
示例:wang@172.16.%.%
user2@'192.168.1.%'
mage@'10.0.0.0/255.255.0.0'
创建用户:CREATE USER
CREATE USER 'USERNAME'@'HOST' [IDENTIFIED BY 'password'];
#示例:
create user 'cy'@'192.168.10.0/255.255.255.0' identified by '123456';
create user 'zhangzhuo'@'192.168.10.%' identified by '123456';
新建用户的默认权限:USAGE
用户重命名:RENAME USER
RENAME USER old_user_name TO new_user_name;
#示例
rename user 'cy'@'192.168.10.0/255.255.255.0' to 'chengyang'@'10.0.0.%';
删除用户:
DROP USER 'USERNAME'@'HOST'
#示例
drop user 'chengyang'@'10.0.0.%';
修改密码:
注意:
- 新版mysql中用户密码可以保存在mysql.user表的authentication_string字段中
- 如果mysql.user表的authentication_string和password字段都保存密码,authentication_string优先生效
#方法1,用户可以也可通过此方式修改自已的密码
SET PASSWORD FOR 'user'@'host' = PASSWORD('password'); #MySQL8.0 版本不支持此方法,因为password函数被取消
set password for root@'localhost'='123456' ; #MySQL8.0版本支持此方法,此方式直接将密码123456加密后存放在mysql.user表的authentication_string字段
#方法2
ALTER USER test@'%' IDENTIFIED BY 'centos'; #通用改密码方法, 用户可以也可通过此方式修改自已的密码,MySQL8 版本修改密码
#方法3 此方式MySQL8.0不支持,因为password函数被取消
UPDATE mysql.user SET password=PASSWORD('password') WHERE clause;
#mariadb 10.3
update mysql.user set authentication_string=password('ubuntu') where
user='mage';
#此方法需要执行下面指令才能生效:
FLUSH PRIVILEGES;
忘记管理员密码的解决办法:
- 启动mysqld进程时,为其使用如下选项:
--skip-grant-tables
--skip-networking
- 使用UPDATE命令修改管理员密码
- 关闭mysqld进程,移除上述两个选项,重启mysqld
范例:
[11:47:57 root@centos8 ~]#vim /etc/my.cnf.d/mysql-server.cnf
skip-grant-tables
skip-networking #mysql8.0不需要
[11:48:44 root@centos8 ~]#systemctl restart mysqld.service
#方法1
flush privileges;
set password for root@'localhost'='Zhangzhuo@1234';
[root@centos8 ~]#vim /etc/my.cnf
[mysqld]
#skip-grant-tables
#skip-networking
[11:56:32 root@centos8 ~]#systemctl restart mysqld.service
3.14 权限管理和DCL语句
3.14.1 权限类别
权限类别:
- 管理类
- 程序类
- 数据库级别
- 表级别
- 字段级别
管理类:
- CREATE USER
- FILE
- SUPER
- SHOW DATABASES
- RELOAD
- SHUTDOWN
- REPLICATION SLAVE
- REPLICATION CLIENT
- LOCK TABLES
- PROCESS
- CREATE TEMPORARY TABLES
程序类:针对 FUNCTION、PROCEDURE、TRIGGER
- CREATE
- ALTER
- DROP
- EXCUTE
库和表级别:针对 DATABASE、TABLE
- ALTER
- CREATE
- CREATE VIEW
- DROP INDEX
- SHOW VIEW
- WITH GRANT OPTION:能将自己获得的权限转赠给其他用户
数据操作
- SELECT
- INSERT
- DELETE
- UPDATE
字段级别
- SELECT(col1,col2,...)
- UPDATE(col1,col2,...)
- INSERT(col1,col2,...)
所有权限
- ALL PRIVILEGES 或 ALL
3.14.2 授权
授权:GRANT,授权之后如要立即生效需要使用flush privileges命令生效
GRANT priv_type [(column_list)],... ON [object_type] priv_level TO 'user'@'host'
[IDENTIFIED BY 'password'] [WITH GRANT OPTION];
priv_type: ALL [PRIVILEGES]
object_type:TABLE | FUNCTION | PROCEDURE
priv_level: *(所有库) |*.* | db_name.* | db_name.tbl_name | tbl_name(当前库
的表) | db_name.routine_name(指定库的函数,存储过程,触发器)
with_option: GRANT OPTION
| MAX_QUERIES_PER_HOUR count
| MAX_UPDATES_PER_HOUR count
| MAX_CONNECTIONS_PER_HOUR count
| MAX_USER_CONNECTIONS count
参考:https://dev.mysql.com/doc/refman/5.7/en/grant.html
范例:
GRANT SELECT (col1), INSERT (col1,col2) ON mydb.mytbl TO 'someuser'@'somehost';
grant all on *.* to 'zhangzhuo'@'%';
GRANT ALL PRIVILEGES ON *.* TO 'root'@'10.0.0.%' WITH GRANT OPTION;
#创建用户和授权同时执行的方式在MySQL8.0取消了
GRANT ALL ON wordpress.* TO wordpress@'192.168.8.%' IDENTIFIED BY 'magedu';
GRANT ALL PRIVILEGES ON *.* TO 'root'@'192.168.8.%' IDENTIFIED BY 'magedu' WITH GRANT OPTION;
3.14.3 取消权限
取消授权:REVOKE
REVOKE priv_type [(column_list)] [, priv_type [(column_list)]] ... ON
[object_type] priv_level FROM user [, user] ...
参考:https://dev.mysql.com/doc/refman/5.7/en/revoke.html
范例:
revoke all on *.* from 'zhangzhuo'@'%';
3.14.4 查看指定用户获得的授权
Help SHOW GRANTS
SHOW GRANTS FOR 'user'@'host';
SHOW GRANTS FOR CURRENT_USER[()];
注意:
MariaDB服务进程启动时会读取mysql库中所有授权表至内存
(1) GRANT或REVOKE等执行权限操作会保存于系统表中,MariaDB的服务进程通常会自动重读授权
表,使之生效
(2) 对于不能够或不能及时重读授权表的命令,可手动让MariaDB的服务进程重读授权表:
mysql> FLUSH PRIVILEGES;
3.15 MySQL的图形化的远程管理工具
在MySQL数据库中创建用户并授权后,可以使用相关图形化工具进行远程的管理。
常见的图形化管理工具:
- Navicat
- SQLyog
四、MySQL 架构和性能优化
4.1 MySQL架构
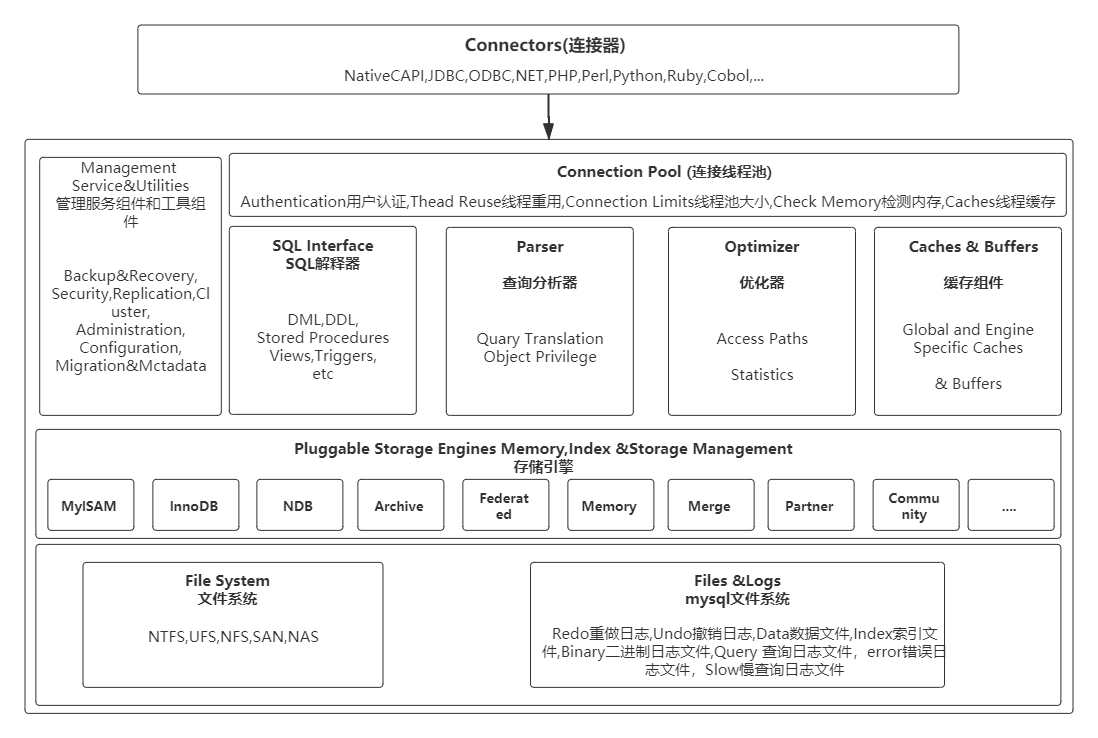
MySQL是C/S 架构的
4.1.1 connectors(连接器)
可供Native C API、JDBC、ODBC、NET、PHP、Perl、Python、Ruby、Cobol 等连接mysql;ODBC叫开放数据库(系统)互联,open database connection;JDBC是主要用于java语言利用较为底层的驱动连接数据库;以上这些,站在编程角度可以理解为连入数据库管理系统的驱动,站在mysql角度称作专用语言对应的链接器.任何链接器连入mysql以后,mysql是单进程多线程模型的,因此,每个用户连接,都会创建一个单独的连接线程;其实mysql连接也有长短连接两种方式,使用mysql客户端连入数据库后,直到使用quit命令才退出,可认为是长连接;使用mysql中的-e选项,在mysql客户端向服务器端申请运行一个命令后则立即退出,也就意味着连接会立即断开;所以,mysql也支持长短连接类似于两种类型;所以,用户连入mysql后,创建一个连接线程,完成之后,能够通过这个链接线程完成接收客户端发来的请求,为其处理请求,构建响应报文并发给客户端;由于是单进程模型,就意味着必须要维持一个线程池,跟之前介绍过的varnish很接近,需要一个线程池来管理这众多线程是如何对众多客户端的并发请求,完成并发响应的,组件connection pool就是实现这样功能;
4.1.2 connection pool(连接线程池)
connection pool对于mysql而言,它所实现的功能,包括authentication认证,用户发来的账号密码是否正确要完成认证功能;thread reuse线程重用功能,一般当一个用户连接进来以后要用一个线程来响应它,而后当用户退出这个线程有可能并非被销毁,而是把它清理完以后,重新收归到线程池当中的空闲线程中去,以完成所谓的线程重用;connection limit 线程池的大小决定了连接并发数量的上限,例如,最多容纳100线程,一旦到达此上限后续到达的连接请求则只能排队或拒绝连接;check memory用来检测内存,caches实现线程缓存;整个都属于线程池的功能.当用户请求之后,通过线程池建立一个用户连接,这个线程一直存在,然后用户就通过这个会话,发送对应的SQL语句到服务器端.
4.1.3 sql interface(SQL解释器,SQL接口)
服务器收到SQL语句后,要对语句完成执行,首先要能理解sql语句需要有sql解释器或叫sql接口sql interface就可理解为是整个mysql的外壳,就像shell是linux操作系统的外壳一样;用户无论通过哪种链接器发来的基本的SQL请求,当然,事实上通过native C API也有发过来的不是SQL 请求,而仅仅是对API中的传递参数后的调用;不是SQL语句不过都统统理解为sql语句罢了;对SQL而言分为DDL 和DML两种类型,但是无论哪种类型,提交以后必须交给内核,让内核来运行,在这之前必须要告诉内核哪个是命令,哪个是选项,哪些是参数,是否存在语法错误等等;因此,这个整个SQL 接口就是一个完完整整的sql命令的解释器,并且这个sql接口还有提供完整的sql接口应该具备的功能,比如支持所谓过程式编程,支持代码块的实现像存储过程、存储函数,触发器、必要时还要实现部署一个关系型数据库应该具备的基本组件例如视图等等,其实都在sql interface这个接口实现的;SQL接口做完词法分析、句法分析后,要分析语句如何执行让parser解析器或分析器实现
4.1.4 parser(查询分析器)
parser是专门的分析器,这个分析器并不是分析语法问题的,语法问题在sql接口时就能发现是否有错误了,一个语句没有问题,就要做执行分析,所谓叫查询翻译,把一个查询语句给它转换成对应的能够在本地执行的特定操作;比如说看上去是语句而背后可能是执行的一段二进制指令,这个时候就完成对应的指令,还要根据用户请求的对象,比如某一字段查询内容是否有对应数据的访问权限,或叫对象访问权限;在数据库中库、表、字段、字段中的数据有时都称为object,叫一个数据库的对象,用户认证的通过,并不意味着就能一定能访问数据库上的所有数据,所以说,mysql的认证大概分为两过程都要完成,第一是连入时需要认证账号密码是否正确这是authentication,然后,验证成功后用户发来sql语句还要验证用户是否有权限获取它期望请求获取的数据;这个称为object privilege,这一切都是由parser分析器进行的
4.1.5 Optimizer(优化器)
分析器分析完成之后,可能会生成多个执行树,这意味着为了能够达到访问期望访问到的目的,可能有多条路径都可实现,就像文件系统一样可以使用相对路径也可使用绝对路径;它有多种方式,在多种路径当中一定有一个是最优的,类似路由选择,因此,优化器就要去衡量多个访问路径中哪一个代价或开销是最小的,这个开销的计算要依赖于索引等各种内部组件来进行评估;而且这个评估的只是近似值,同时还要考虑到当前mysql内部在实现资源访问时统计数据,比如,根据判断认为是1号路径的开销最小的,但是众多统计数据表明发往1号路径的访问的资源开销并不小,并且比3号路径大的多,因此,可能会依据3号路径访问;这就是所谓的优化器它负责检查多条路径,每条路径的开销,然后评估开销,这个评估根据内部的静态数据,索引,根域根据动态生成的统计数据来判定每条路径的开销大小,因此这里还有statics;一旦优化完成之后,还要生成统计数据,这就是优化器的作用;如果没有优化器mysql执行语句是最慢的,其实优化还包括一种功能,一旦选择完一条路径后,例如用户给的这个命令执行起来,大概需要100个开销,如果通过改写语句能够达到同样目的可能只需要30个开销;于是,优化器还要试图改写sql语句;所以优化本身还包括查询语句的改写;一旦优化完成,接下来就交给存储引擎完成.
4.1.6 cache和buffer(缓存组件)
事实上,整个存取过程,尤其是访问比较热点的数据,也不可能每一次当用户访问时或当某SQL语句用到时再临时从磁盘加载到内存中,因此,为了能够加上整个性能,mysql的有些存储引擎可以实现,把频繁访问到的热点数据,统统装入内存,用户访问、修改时直接在内存中操作,只不过周期性的写入磁盘上而已,比如像InnoDB,所以caches和buffers组件就是实现此功能的;MySQL为了执行加速,因为它会不断访问数据,而随计算机来说io是最慢的一环,尤其是磁盘io,所以为了加速都载入内存中管理;这就需要MySQL 维护cache和buffer缓存或缓冲;这是由MySQL 服务器自己维护的;有很多存储引擎自己也有cache和buffer
4.1.7 Pluggable Storage Engines(插件式存储引擎)
mysql是插件式存储引擎,它就能够替换使用选择多种不同的引擎,MyISAM是MySQL 经典的存储引擎之一,InnoDB是由Innobase Oy公司所开发,2006年五月由甲骨文公司并购提供给MySQL的,NDB主要用于MySQL Cluster 分布式集群环境,archive做归档的等等,还有许多第三方开发的存储引擎;存储引擎负责把具体分析的结果完成对磁盘上文件路径访问的转换,数据库中的行数据都是存储在磁盘块上的,因此存储引擎要把数据库数据映射为磁盘块,并把磁盘块加载至内存中;进程实现数据处理时,是不可能直接访问磁盘上的数据的,因为它没有权限,只有让内核来把它所访问的数据加载至内存中以后,进程在内存中完成修改,由内核再负责把数据存回磁盘;对于文件系统而言,数据的存储都是以磁盘块方式存储的,但是,mysql在实现数据组织时,不完全依赖于磁盘,而是把磁盘块再次组织成更大一级的逻辑单位,类似于lvm中的PE或LE的形式;其实,MySQL的存储引擎在实现数据管理时,也是在文件系统之上布设文件格式,对于文件而言在逻辑层上还会再次组织成一个逻辑单位,这个逻辑单位称为mysql的数据块datablock 一般为16k ,对于关系型数据库,数据是按行存储的;一般一行数据都是存储在一起的,因此,MySQL 在内部有一个datablock,在datablock可能存储一行数据,也可能存放了n行数据;将来在查询加载一行数据时,内核会把整个一个数据数据块加载至内存中,而mysql存储引擎,就从中挑出来某一行返回给查询者,是这样实现的;所以整个存储是以datablock在底层为其最终级别的.
4.1.8 File System(物理文件)
一个数据库提供了3种视图,物理视图就是看到的对应的文件系统存储为一个个的文件,MySQL的数据文件类型,常见的有redo log重做日志,undo log撤销日志,data是真正的数据文件,index是索引文件,binary log是二进制日志文件,error log错误日志,query log查询日志,slow query log慢查询日志,在复制架构中还存在中继日志文件,跟二进制属于同种格式;这是mysql数据文件类型,也就是物理视图;逻辑视图这是在mysql接口上通过存储引擎把mysql文件尤其是data文件,给它映射为一个个关系型数据库应该具备组成部分,比如表,一张表在底层是一个数据文件而已,里面组织的就是datablock,最终映射为磁盘上文件系统的block,然后再次映射为本地扇区的存储,但是整个mysql需要把他们映射成一个二维关系表的形式,需要依赖sql接口以及存储引擎共同实现;所以,把底层数据文件映射成关系型数据库的组件就是逻辑视图;DBA 就是关注内部组件是如何运作的,并且定义、配置其运作模式,而链接器都是终端用户通过链接器的模式进入数据库来访问数据;数据集可能非大,每一类用户可能只有一部分数据的访问权限,这个时候,最终的终端用户所能访问到的数据集合称作用户视图;
4.1.9 Management Service & Utilities(管理服务组件和工具组件)
为了保证MySQL运作还提供了管理和服务工具,例如:备份恢复工具,安全工具,复制工具,集群服务,管理、配置、迁移、元数据等工具
4.2 存储引擎
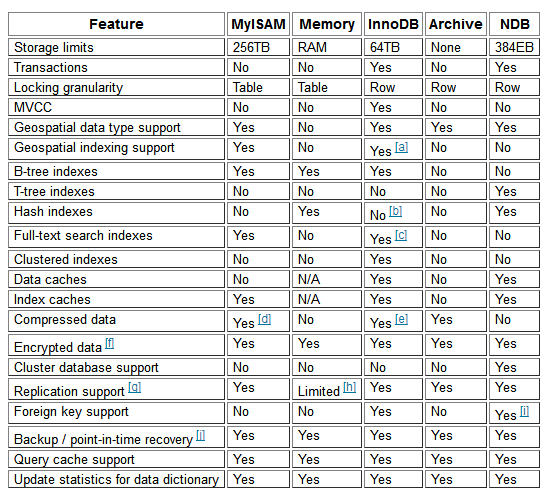
MySQL中的数据用各种不同的技术存储在文件(或者内存)中。这些技术中的每一种技术都使用不同的存储机制、索引技巧、锁定水平并且最终提供广泛的不同的功能和能力,此种技术称为存擎,MySQL 支持多种存储引擎其中目前应用最广泛的是InnoDB和MyISAM两种
官方参考资料:
https://docs.oracle.com/cd/E17952_01/mysql-8.0-en/storage-engines.html
https://docs.oracle.com/cd/E17952_01/mysql-5.7-en/storage-engines.html
4.2.1 MyISAM 存储引擎
MyISAM 引擎特点
- 不支持事务
- 表级锁定
- 读写相互阻塞,写入不能读,读时不能写
- 只缓存索引
- 不支持外键约束
- 不支持聚簇索引
- 读取数据较快,占用资源较少
- 不支持MVCC(多版本并发控制机制)高并发
- 崩溃恢复性较差
- MySQL5.5.5 前默认的数据库引擎
MyISAM 存储引擎适用场景
- 只读(或者写较少)
- 表较小(可以接受长时间进行修复操作)
MyISAM 引擎文件
- tbl_name.frm 表格式定义
- tbl_name.MYD 数据文件
- tbl_name.MYI 索引文件
4.2.2 InnoDB 引擎
InnoDB引擎特点
- 行级锁
- 支持事务,适合处理大量短期事务
- 读写阻塞与事务隔离级别相关
- 可缓存数据和索引
- 支持聚簇索引
- 崩溃恢复性更好
- 支持MVCC高并发
- 从MySQL5.5后支持全文索引
- 从MySQL5.5.5开始为默认的数据库引擎
InnoDB数据库文件
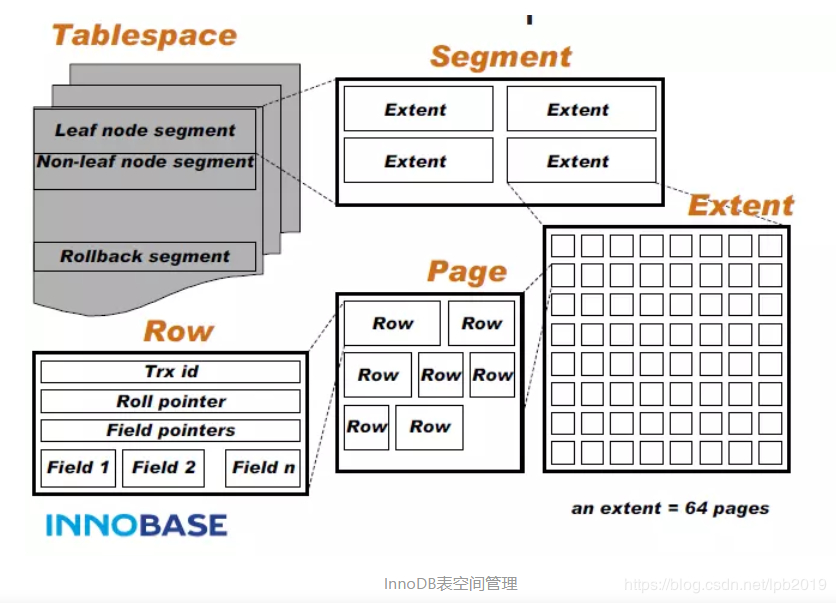
- 所有InnoDB表的数据和索引放置于同一个表空间中
数据文件:ibdata1, ibdata2,存放在datadir定义的目录下
表格式定义:tb_name.frm,存放在datadir定义的每个数据库对应的目录下
- 每个表单独使用一个表空间存储表的数据和索引
两类文件放在对应每个数据库独立目录中
数据文件(存储数据和索引):tb_name.ibd
表格式定义:tb_name.frm
启用:innodb_file_per_table=ON (MariaDB 5.5以后版是默认值)
4.2.3 其它存储引擎
- Performance_Schema:Performance_Schema数据库使用
- Memory :将所有数据存储在RAM中,以便在需要快速查找参考和其他类似数据的环境中进行快速访问。适用存放临时数据。引擎以前被称为HEAP引擎
- MRG_MyISAM:使MySQL DBA或开发人员能够对一系列相同的MyISAM表进行逻辑分组,并将它们作为一个对象引用。适用于VLDB(Very Large Data Base)环境,如数据仓库
- Archive :为存储和检索大量很少参考的存档或安全审核信息,只支持SELECT和INSERT操作;支持行级锁和专用缓存区
- Federated联合:用于访问其它远程MySQL服务器一个代理,它通过创建一个到远程MySQL服务器的客户端连接,并将查询传输到远程服务器执行,而后完成数据存取,提供链接单独MySQL服务器的能力,以便从多个物理服务器创建一个逻辑数据库。非常适合分布式或数据集市环境
- BDB:可替代InnoDB的事务引擎,支持COMMIT、ROLLBACK和其他事务特性Cluster/NDB:MySQL的簇式数据库引擎,尤其适合于具有高性能查找要求的应用程序,这类查找需求还要求具有最高的正常工作时间和可用性
- CSV:CSV存储引擎使用逗号分隔值格式将数据存储在文本文件中。可以使用CSV引擎以CSV格式导入和导出其他软件和应用程序之间的数据交换
- BLACKHOLE :黑洞存储引擎接受但不存储数据,检索总是返回一个空集。该功能可用于分布式数据库设计,数据自动复制,但不是本地存储
- example:"stub"引擎,它什么都不做。可以使用此引擎创建表,但不能将数据存储在其中或从中检索。目的是作为例子来说明如何开始编写新的存储引擎
4.2.4 管理存储引擎
查看mysql支持的存储引擎
show engines;
查看当前默认的存储引擎
show variables like '%storage_engine%';
设置默认的存储引擎
vim /etc/my.cnf
[mysqld]
default_storage_engine= InnoDB
查看库中所有表使用的存储引擎
show table status from testdb;
show table status from testdb\G;
查看库中指定表的存储引擎
show table status like 'events_list';
show table status like 'events_list'\G
show create table events_list;
设置表的存储引擎:
CREATE TABLE tb_name(... ) ENGINE=InnoDB;
#修改表存储引擎,切记如果表中有数据请勿修改
ALTER TABLE tb_name ENGINE=InnoDB;
4.3 MySQL 中的系统数据库
- mysql 数据库
是mysql的核心数据库,类似于Sql Server中的master库,主要负责存储数据库的用户、权限设置、关键字等mysql自己需要使用的控制和管理信息
- information_schema 数据库
MySQL 5.0之后产生的,一个虚拟数据库,物理上并不存在information_schema数据库类似与"数据字典",提供了访问数据库元数据的方式,即数据的数据。比如数据库名或表名,列类型,访问权限(更加细化的访问方式)
- performance_schema 数据库
MySQL 5.5开始新增的数据库,主要用于收集数据库服务器性能参数,库里表的存储引擎均为PERFORMANCE_SCHEMA,用户不能创建存储引擎为PERFORMANCE_SCHEMA的表
- sys 数据库
MySQL5.7之后新增加的数据库,库中所有数据源来自performance_schema。目标是把performance_schema的把复杂度降低,让DBA能更好的阅读这个库里的内容。让DBA更快的了解DataBase的运行情况
4.4 服务器配置和状态
可以通过mysqld选项,服务器系统变量和服务器状态变量进行MySQL的配置和查看状态
官方帮助:可以查询各种系统变量参数的详细信息
https://dev.mysql.com/doc/refman/8.0/en/server-option-variable-reference.html
https://dev.mysql.com/doc/refman/5.7/en/server-option-variable-reference.html
https://mariadb.com/kb/en/library/full-list-of-mariadb-options-system-and-status-variables/
注意:
- 其中有些参数支持运行时修改,会立即生效
- 有些参数不支持动态修改,且只能通过修改配置文件,并重启服务器程序生效
- 有些参数作用域是全局的,为所有会话设置
- 有些可以为每个用户提供单独(会话)的设置
4.4.1 服务器选项
注意: 服务器选项用横线,不用下划线
获取mysqld的可用选项列表:
#查看mysqld可用选项列表和及当前值
mysqld --verbose --help
#获取mysqld当前启动选项
mysqld --print-defaults
设置服务器选项方法:
- 在命令行中设置
shell> /usr/bin/mysqld_safe --skip-name-resolve=1
shell> /usr/libexec/mysqld --basedir=/usr
- 在配置文件my.cnf中设置
vim /etc/my.cnf
[mysqld]
skip_name_resolve=1
skip-grant-tables
范例: skip-grant-tables是服务器选项,但不是系统变量
mysql> show variables like 'skip_grant_tables';
Empty set (0.00 sec)
4.4.2 服务器系统变量
服务器系统变量:可以分全局和会话两种
注意: 系统变量用下划线,不用横线
获取系统变量
SHOW GLOBAL VARIABLES; #只查看global变量
SHOW [SESSION] VARIABLES; #查看所有变量(包括global和session)
#查看指定的系统变量
SHOW VARIABLES LIKE 'VAR_NAME';
SELECT @@VAR_NAME;
#查看选项和部分变量
[root@centos8 ~]#mysqladmin variables
修改服务器变量的值:
#修改全局变量:仅对修改后新创建的会话有效;对已经建立的会话无效
SET GLOBAL system_var_name=value;
SET @@global.system_var_name=value;
#修改会话变量:
SET [SESSION] system_var_name=value;
SET @@[session.]system_var_name=value;
范例:修改mysql的最大并发连接数
#默认值151
mysql> show variables like 'max_connections';
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| max_connections | 151 |
+-----------------+-------+
1 row in set (0.00 sec)
mysql> set global max_connections=2000;
Query OK, 0 rows affected (0.00 sec)
mysql> show variables like 'max_connections';
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| max_connections | 2000 |
+-----------------+-------+
1 row in set (0.00 sec)
[16:29:49 root@centos8 ~]#vim /etc/my.cnf.d/mysql-server.cnf
[mysqld]
max_connections = 8000
[16:46:02 root@centos8 ~]#systemctl restart mysqld.service
mysql> show variables like 'max_connections';
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| max_connections | 8000 |
+-----------------+-------+
1 row in set (0.00 sec)
4.4.3 服务器状态变量
服务器状态变量:分全局和会话两种
状态变量(只读):用于保存mysqld运行中的统计数据的变量,不可更改
SHOW GLOBAL STATUS;
SHOW [SESSION] STATUS;
范例:
mysql> show status like "innodb_page_size";
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| Innodb_page_size | 16384 |
+------------------+-------+
1 row in set (0.00 sec)
mysql> mysql> show status like "com_select";
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| Com_select | 1 |
+---------------+-------+
1 row in set (0.00 sec)
4.4.4 服务器变量 SQL_MODE
SQL_MODE:对其设置可以完成一些约束检查的工作,可分别进行全局的设置或当前会话的设置
参考:
https://mariadb.com/kb/en/library/sql-mode/
https://dev.mysql.com/doc/refman/5.7/en/server-options.html#option_mysqld_sql-mode
常见MODE:
- NO_AUTO_CREATE_USER: 禁止GRANT创建密码为空的用户
- NO_ZERO_DATE:在严格模式,不允许使用'0000-00-00'的时间
- ONLY_FULL_GROUP_BY: 对于GROUP BY聚合操作,如果在SELECT中的列,没有在GROUP BY中出现,那么将认为这个SQL是不合法的
- NO_BACKSLASH_ESCAPES: 反斜杠""作为普通字符而非转义字符
- PIPES_AS_CONCAT: 将"||"视为连接操作符而非"或"运算符
范例:
set sql_mode='ONLY_FULL_GROUP_BY';
4.5 Query Cache 查询缓存
4.5.1 查询缓存原理
查询执行路径
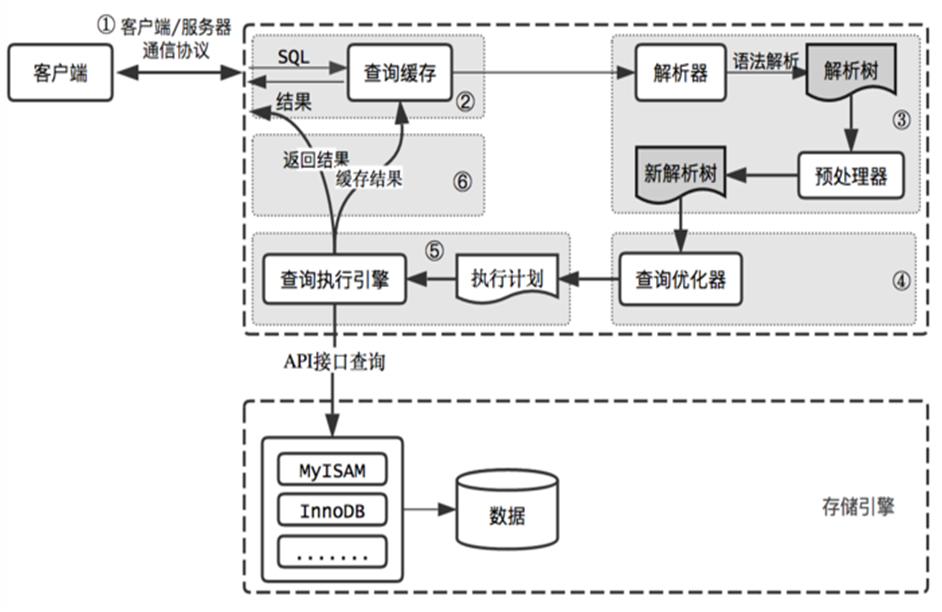
查询缓存原理
缓存SELECT操作或预处理查询的结果集和SQL语句,当有新的SELECT语句或预处理查询语句请求,先去查询缓存,判断是否存在可用的记录集,判断标准:与缓存的SQL语句,是否完全一样,区分大小写
优缺点
不需要对SQL语句做任何解析和执行,当然语法解析必须通过在先,直接从Query Cache中获得查询结果,提高查询性能查询缓存的判断规则,不够智能,也即提高了查询缓存的使用门槛,降低效率查询缓存的使用,会增加检查和清理Query Cache中记录集的开销
哪些查询可能不会被缓存
- 查询语句中加了SQL_NO_CACHE参数
- 查询语句中含有获得值的函数,包含:自定义函数,如:NOW() ,CURDATE()、GET_LOCK()、RAND()、CONVERT_TZ()等
- 对系统数据库的查询:mysql、information_schema 查询语句中使用SESSION级别变量或存储过程中的局部变量
- 查询语句中使用了LOCK IN SHARE MODE、FOR UPDATE的语句,查询语句中类似SELECT …INTO 导出数据的语句
- 对临时表的查询操作
- 存在警告信息的查询语句
- 不涉及任何表或视图的查询语句
- 某用户只有列级别权限的查询语句
- 事务隔离级别为Serializable时,所有查询语句都不能缓存
4.5.2 查询缓存相关的服务器变量
- query_cache_min_res_unit:查询缓存中内存块的最小分配单位,默认4k,较小值会减少浪费,但会导致更频繁的内存分配操作,较大值会带来浪费,会导致碎片过多,内存不足
- query_cache_limit:单个查询结果能缓存的最大值,单位字节,默认为1M,对于查询结果过大而无法缓存的语句,建议使用SQL_NO_CACHE
- query_cache_size:查询缓存总共可用的内存空间;单位字节,必须是1024的整数倍,最小值40KB,低于此值有警报
- query_cache_wlock_invalidate:如果某表被其它的会话锁定,是否仍然可以从查询缓存中返回结果,默认值为OFF,表示可以在表被其它会话锁定的场景中继续从缓存返回数据;ON则表示不允许
- query_cache_type:是否开启缓存功能,取值为ON, OFF, DEMAND
4.5.3 SELECT 语句的缓存控制
SQL_CACHE:显式指定存储查询结果于缓存之中
SQL_NO_CACHE:显式查询结果不予缓存
query_cache_type 参数变量
- query_cache_type的值为OFF或0时,查询缓存功能关闭
- query_cache_type的值为ON或1时,查询缓存功能打开,SELECT的结果符合缓存条件即会缓存,否则,不予缓存,显式指定SQL_NO_CACHE,不予缓存,此为默认值
- query_cache_type的值为DEMAND或2时,查询缓存功能按需进行,显式指定SQL_CACHE的SELECT语句才会缓存;其它均不予缓存
官方帮助:
https://mariadb.com/kb/en/library/server-system-variables/#query_cache_type
https://dev.mysql.com/doc/refman/5.7/en/query-cache-configuration.html
4.5.4 查询缓存相关的状态变量
SHOW GLOBAL STATUS LIKE 'Qcache%';
- Qcache_free_blocks:处于空闲状态 Query Cache中内存 Block 数
- Qcache_total_blocks:Query Cache 中总Block ,当Qcache_free_blocks相对此值较大时,可能用内存碎片,执行FLUSH QUERY CACHE清理碎片
- Qcache_free_memory:处于空闲状态的 Query Cache 内存总量
- Qcache_hits:Query Cache 命中次数
- Qcache_inserts:向 Query Cache 中插入新的 Query Cache 的次数,即没有命中的次数
- Qcache_lowmem_prunes:记录因为内存不足而被移除出查询缓存的查询数
- Qcache_not_cached:没有被 Cache 的 SQL 数,包括无法被 Cache 的 SQL 以及由于query_cache_type 设置的不会被 Cache 的 SQL语句
- Qcache_queries_in_cache:在 Query Cache 中的 SQL 数量
4.5.5 查询的优化
4.5.6 命中率和内存使用率估算
- 查询缓存中内存块的最小分配单位query_cache_min_res_unit :
(query_cache_size - Qcache_free_memory) / Qcache_queries_in_cache
- 查询缓存命中率 :
Qcache_hits / ( Qcache_hits + Qcache_inserts ) * 100%
- 查询缓存内存使用率:
(query_cache_size - qcache_free_memory) / query_cache_size * 100%
范例:
[root@centos7 ~]#vim /etc/my.cnf
[mysqld]
query_cache_type=ON
query_cache_size=10M
[root@centos8 ~]#systemctl restart mariadb
[root@centos8 ~]#mysql -uroot -p
MariaDB [(none)]> show variables like 'query_cache%';
+------------------------------+---------+
| Variable_name | Value |
+------------------------------+---------+
| query_cache_limit | 1048576 |
| query_cache_min_res_unit | 4096 |
| query_cache_size | 1048576 |
| query_cache_strip_comments | OFF |
| query_cache_type | ON |
| query_cache_wlock_invalidate | OFF |
+------------------------------+---------+
6 rows in set (0.001 sec)
MariaDB [(none)]> SHOW GLOBAL STATUS LIKE 'Qcache%';
+-------------------------+---------+
| Variable_name | Value |
+-------------------------+---------+
| Qcache_free_blocks | 1 |
| Qcache_free_memory | 1027736 |
| Qcache_hits | 3 |
| Qcache_inserts | 3 |
| Qcache_lowmem_prunes | 0 |
| Qcache_not_cached | 0 |
| Qcache_queries_in_cache | 3 |
| Qcache_total_blocks | 8 |
+-------------------------+---------+
8 rows in set (0.003 sec)
4.5.7 MySQL 8.0 变化
MySQL8.0 取消查询缓存的功能
尽管MySQL Query Cache旨在提高性能,但它存在严重的可伸缩性问题,并且很容易成为严重的瓶颈。
自MySQL 5.6(2013)以来,默认情况下已禁用查询缓存,其不能与多核计算机上在高吞吐量工作负载情况下进行扩展。
另外有时因为查询缓存往往弊大于利。比如:查询缓存的失效非常频繁,只要有对一个表的更新,这个表上的所有的查询缓存都会被清空。因此很可能你费劲地把结果存起来,还没使用呢,就被一个更新全清空了。对于更新压力大的数据库来说,查询缓存的命中率会非常低。除非你的业务有一张静态表,很长时间更新一次,比如系统配置表,那么这张表的查询才适合做查询缓存。
目前大多数应用都把缓存做到了应用逻辑层,比如:使用redis或者memcached
4.6 INDEX 索引
4.6.1 索引介绍
索引:是排序的快速查找的特殊数据结构,定义作为查找条件的字段上,又称为键key,索引通过存储引擎实现
优点:
- 索引可以降低服务需要扫描的数据量,减少了IO次数
- 索引可以帮助服务器避免排序和使用临时表
- 索引可以帮助将随机I/O转为顺序I/O
缺点:
- 占用额外空间,影响插入速度
索引类型:
- B+ TREE、HASH、R TREE、FULL TEXT
- 聚簇(集)索引、非聚簇索引:数据和索引是否存储在一起
- 主键索引、二级(辅助)索引
- 稠密索引、稀疏索引:是否索引了每一个数据项
- 简单索引、组合索引: 是否是多个字段的索引
- 左前缀索引:取前面的字符做索引
- 覆盖索引:从索引中即可取出要查询的数据,性能高
4.6.2 索引结构
参考链接 : https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
二叉树
参考链接: https://www.cs.usfca.edu/~galles/visualization/BST.html
红黑树
参考链接:https://www.cs.usfca.edu/~galles/visualization/RedBlack.html
B-Tree 索引
参考链接: https://www.cs.usfca.edu/~galles/visualization/BTree.html
B+Tree索引
参考链接: https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
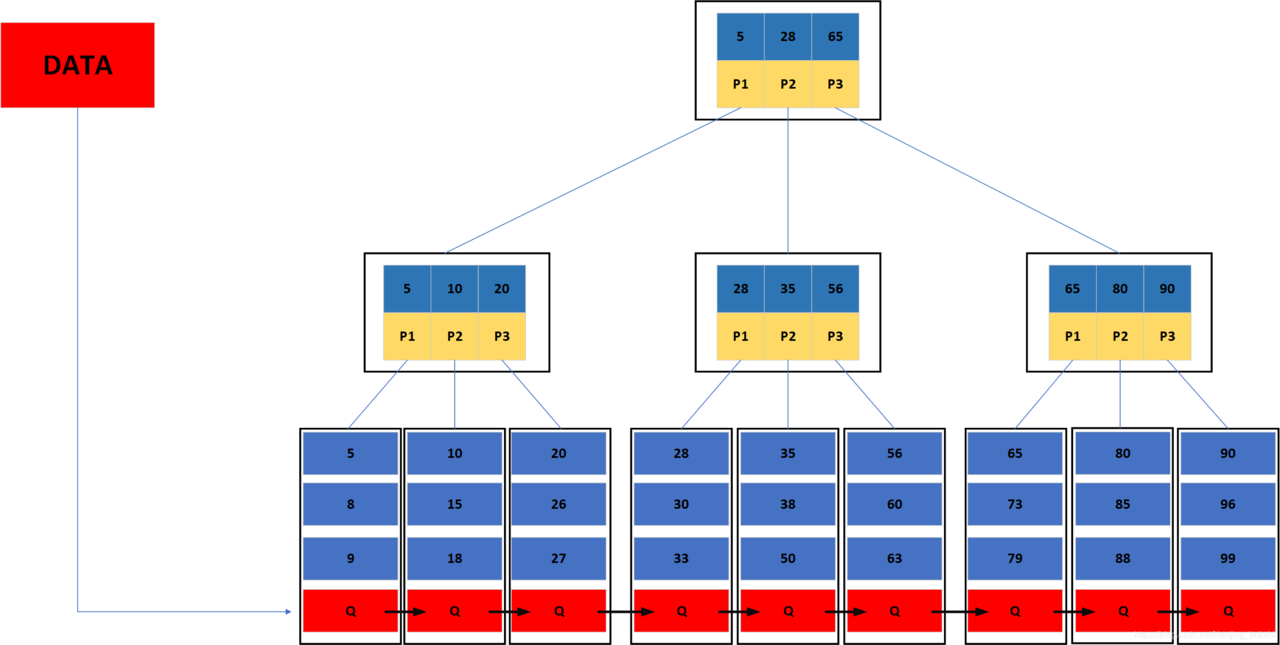
B+Tree索引:按顺序存储,每一个叶子节点到根结点的距离是相同的;左前缀索引,适合查询范围类的数据
面试题: InnoDB中一颗的B+树可以存放多少行数据?
假设定义一颗B+树高度为2,即一个根节点和若干叶子节点。那么这棵B+树的存放总行记录数=根节点指针数*单个叶子记录的行数。这里先计算叶子节点,B+树中的单个叶子节点的大小为16K,假设每一条目为1K,那么记录数即为16(16k/1K=16),然后计算非叶子节点能够存放多少个指针,假设主键ID为bigint类型,那么长度为8字节,而指针大小在InnoDB中是设置为6个字节,这样加起来一共是14个字节。那么通过页大小/(主键ID大小+指针大小),即16384/14=1170个指针,所以一颗高度为2的B+树能存放16*1170=18720条这样的记录。根据这个原理就可以算出一颗高度为3的B+树可以存放16*1170*1170=21902400条记录。所以在InnoDB中B+树高度一般为2-3层,它就能满足千万级的数据存储
可以使用B+Tree索引的查询类型:(假设前提: 姓,名,年龄三个字段建立了一个复合索引)
- 全值匹配:精确所有索引列,如:姓wang,名xiaochun,年龄30
- 匹配最左前缀:即只使用索引的第一列,如:姓wang
- 匹配列前缀:只匹配一列值开头部分,如:姓以w开头的记录
- 匹配范围值:如:姓ma和姓wang之间
- 精确匹配某一列并范围匹配另一列:如:姓wang,名以x开头的记录
- 只访问索引的查询
B+Tree索引的限制:
- 如不从最左列开始,则无法使用索引,如:查找名为xiaochun,或姓为g结尾
- 不能跳过索引中的列:如:查找姓wang,年龄30的,只能使用索引第一列
特别提示:
索引列的顺序和查询语句的写法应相匹配,才能更好的利用索引
为优化性能,可能需要针对相同的列但顺序不同创建不同的索引来满足不同类型的查询需求
Hash索引
Hash索引:基于哈希表实现,只有精确匹配索引中的所有列的查询才有效,索引自身只存储索引列对应的哈希值和数据指针,索引结构紧凑,查询性能好
Memory存储引擎支持显式hash索引,InnoDB和MyISAM存储引擎不支持
适用场景:只支持等值比较查询,包括=, <=>, IN()
不适合使用hash索引的场景
- 不适用于顺序查询:索引存储顺序的不是值的顺序
- 不支持模糊匹配
- 不支持范围查询
- 不支持部分索引列匹配查找:如A,B列索引,只查询A列索引无效
地理空间数据索引R-Tree( Geospatial indexing )
MyISAM支持地理空间索引,可使用任意维度组合查询,使用特有的函数访问,常用于做地理数据存
储,使用不多
InnoDB从MySQL5.7之后也开始支持
全文索引(FULLTEXT)
在文本中查找关键词,而不是直接比较索引中的值,类似搜索引擎
InnoDB从MySQL 5.6之后也开始支持
聚簇和非聚簇索引,主键和二级索引
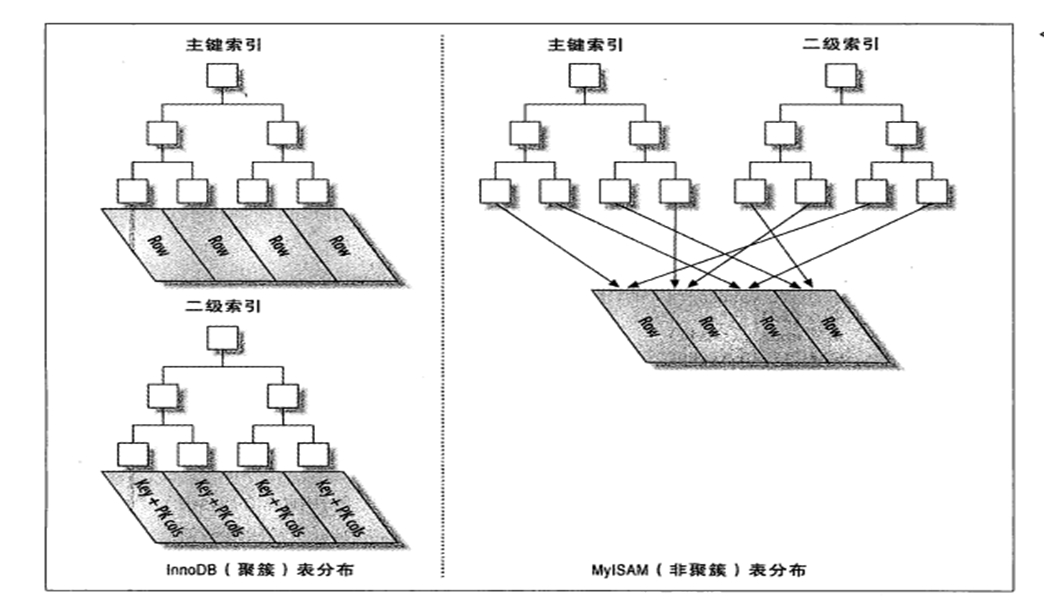
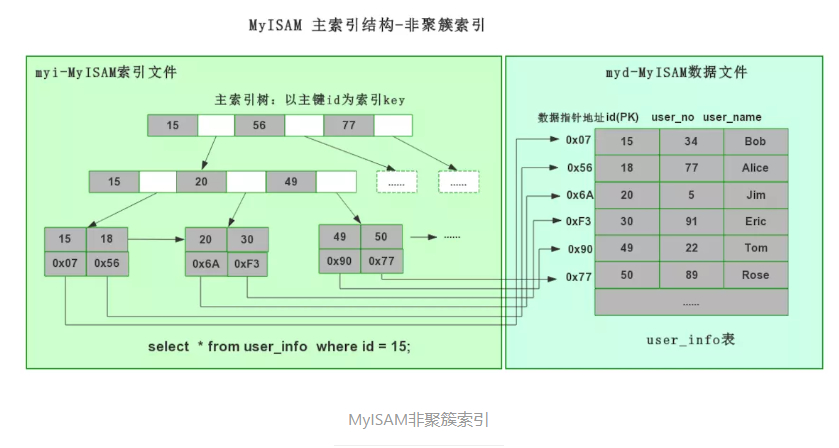
冗余和重复索引:
- 冗余索引:(A),(A,B),注意如果同时存在,仍可能会使用(A)索引
- 重复索引:已经有索引,再次建立索引
4.6.3 索引优化
参考资料: 阿里的《Java开发手册》
https://developer.aliyun.com/topic/java2020
- 独立地使用列:尽量避免其参与运算,独立的列指索引列不能是表达式的一部分,也不能是函数的参数,在where条件中,始终将索引列单独放在比较符号的一侧,尽量不要在列上进行运算(函数操作和表达式操作)
- 左前缀索引:构建指定索引字段的左侧的字符数,要通过索引选择性(不重复的索引值和数据表的记录总数的比值)来评估,尽量使用短索引,如果可以,应该制定一个前缀长度
- 多列索引:AND操作时更适合使用多列索引,而非为每个列创建单独的索引
- 选择合适的索引列顺序:无排序和分组时,将选择性最高放左侧
- 只要列中含有NULL值,就最好不要在此列设置索引,复合索引如果有NULL值,此列在使用时也不会使用索引
- 对于经常在where子句使用的列,最好设置索引
- 对于有多个列where或者order by子句,应该建立复合索引
- 对于like语句,以 % 或者 _ 开头的不会使用索引,以 % 结尾会使用索引
- 尽量不要使用not in和<>操作,虽然可能使用索引,但性能不高
- 不要使用RLIKE正则表达式会导致索引失效
- 查询时,能不要就不用,尽量写全字段名,比如:select id,name,age from students;
- 大部分情况连接效率远大于子查询
- 在有大量记录的表分页时使用limit
- 对于经常使用的查询,可以开启查询缓存
- 多使用explain和profile分析查询语句
- 查看慢查询日志,找出执行时间长的sql语句优化
4.6.4 管理索引
创建索引:
CREATE [UNIQUE] INDEX index_name ON tbl_name (index_col_name[(length)],...);
ALTER TABLE tbl_name ADD INDEX index_name(index_col_name[(length)]);
help CREATE INDEX;
删除索引:
DROP INDEX index_name ON tbl_name;
ALTER TABLE tbl_name DROP INDEX index_name(index_col_name);
查看索引:
SHOW INDEXES FROM [db_name.]tbl_name;
优化表空间:
OPTIMIZE TABLE tb_name;
查看索引的使用
SET GLOBAL userstat=1; #MySQL无此变量
SHOW INDEX_STATISTICS;
范例:
mysql> desc students;
+-----------+------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-----------+------------------+------+-----+---------+----------------+
| StuID | int unsigned | NO | PRI | NULL | auto_increment |
| Name | varchar(50) | NO | | NULL | |
| Age | tinyint unsigned | NO | | NULL | |
| Gender | enum('F','M') | NO | | NULL | |
| ClassID | tinyint unsigned | YES | | NULL | |
| TeacherID | int unsigned | YES | | NULL | |
+-----------+------------------+------+-----+---------+----------------+
6 rows in set (0.01 sec)
mysql> SHOW INDEXES FROM students\G
*************************** 1. row ***************************
Table: students
Non_unique: 0
Key_name: PRIMARY
Seq_in_index: 1
Column_name: StuID
Collation: A
Cardinality: 25
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
Visible: YES
Expression: NULL
1 row in set (0.00 sec)
mysql> select * from students where stuid=12;
+-------+--------------+-----+--------+---------+-----------+
| StuID | Name | Age | Gender | ClassID | TeacherID |
+-------+--------------+-----+--------+---------+-----------+
| 12 | Wen Qingqing | 19 | F | 1 | NULL |
+-------+--------------+-----+--------+---------+-----------+
1 row in set (0.00 sec)
4.6.5 EXPLAIN 工具
可以通过EXPLAIN来分析索引的有效性,获取查询执行计划信息,用来查看查询优化器如何执行查询
参考资料: https://dev.mysql.com/doc/refman/5.7/en/explain-output.html
语法:
EXPLAIN SELECT clause
EXPLAIN输出信息说明:
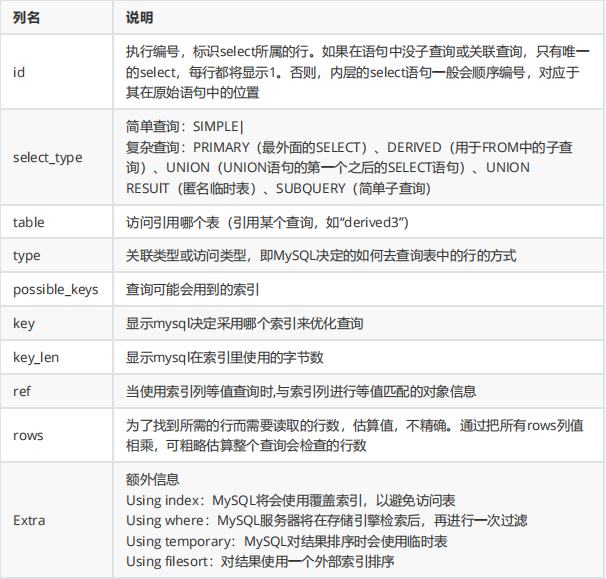
说明: type显示的是访问类型,是较为重要的一个指标,结果值从好到坏依次是:NULL> system >const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery >range > index > ALL ,一般来说,得保证查询至少达到range级别,最好能达到ref
NULL>system>const>eq_ref>ref>fulltext>ref_or_null>index_merge>unique_subquery>
index_subquery>range>index>ALL //最好到最差
备注:掌握以下10种常见的即可
NULL>system>const>eq_ref>ref>ref_or_null>index_merge>range>index>ALL

范例:
explain select * from students where stuid=1;
范例:创建索引和使用索引
mysql> create index stu_name on students(name(10));
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> show index from students\G
*************************** 1. row ***************************
Table: students
Non_unique: 0
Key_name: PRIMARY
Seq_in_index: 1
Column_name: StuID
Collation: A
Cardinality: 25
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
Visible: YES
Expression: NULL
*************************** 2. row ***************************
Table: students
Non_unique: 1
Key_name: stu_name
Seq_in_index: 1
Column_name: Name
Collation: A
Cardinality: 25
Sub_part: 10
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
Visible: YES
Expression: NULL
2 rows in set (0.00 sec)
mysql> mysql> explain select * from students where name like 'w%';
+----+-------------+----------+------------+-------+---------------+----------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+-------+---------------+----------+---------+------+------+----------+-------------+
| 1 | SIMPLE | students | NULL | range | stu_name | stu_name | 32 | NULL | 1 | 100.00 | Using where |
+----+-------------+----------+------------+-------+---------------+----------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
mysql> explain select * from students where name like '%x';
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | students | NULL | ALL | NULL | NULL | NULL | NULL | 25 | 11.11 | Using where |
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
范例: 复合索引
mysql> desc students;
+-----------+------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-----------+------------------+------+-----+---------+----------------+
| StuID | int unsigned | NO | PRI | NULL | auto_increment |
| Name | varchar(50) | NO | MUL | NULL | |
| Age | tinyint unsigned | NO | | NULL | |
| Gender | enum('F','M') | NO | | NULL | |
| ClassID | tinyint unsigned | YES | | NULL | |
| TeacherID | int unsigned | YES | | NULL | |
+-----------+------------------+------+-----+---------+----------------+
#创建复合索引
mysql> create index stu_name_age on students(name,age);
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> show index from students\G
*************************** 1. row ***************************
Table: students
Non_unique: 0
Key_name: PRIMARY
Seq_in_index: 1
Column_name: StuID
Collation: A
Cardinality: 25
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
Visible: YES
Expression: NULL
*************************** 2. row ***************************
Table: students
Non_unique: 1
Key_name: stu_name_age
Seq_in_index: 1
Column_name: Name
Collation: A
Cardinality: 25
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
Visible: YES
Expression: NULL
*************************** 3. row ***************************
Table: students
Non_unique: 1
Key_name: stu_name_age
Seq_in_index: 2
Column_name: Age
Collation: A
Cardinality: 25
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
Visible: YES
Expression: NULL
3 rows in set (0.00 sec)
#跳过查询复合索引的前面字段,后续字段的条件查询无法利用复合索引
mysql> mysql> explain select * from students where age=20;
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | students | NULL | ALL | NULL | NULL | NULL | NULL | 25 | 10.00 | Using where |
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+-------------+
#不跳过
mysql> explain select * from students where name='Duan Yu' and age=20;
+----+-------------+----------+------------+------+---------------+--------------+---------+-------------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+--------------+---------+-------------+------+----------+-------+
| 1 | SIMPLE | students | NULL | ref | stu_name_age | stu_name_age | 153 | const,const | 1 | 100.00 | NULL |
+----+-------------+----------+------------+------+---------------+--------------+---------+-------------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
4.7 并发控制
4.7.1 锁机制
锁类型:
- 读锁:共享锁,也称为 S 锁,只读不可写(包括当前事务) ,多个读互不阻塞
- 写锁:独占锁,排它锁,也称为 X 锁,写锁会阻塞其它事务(不包括当前事务)的读和写S 锁和 S 锁是兼容的,X 锁和其它锁都不兼容,举个例子,事务 T1 获取了一个行 r1 的 S 锁,另外事务 T2 可以立即获得行 r1 的 S 锁,此时 T1 和 T2 共同获得行 r1 的 S 锁,此种情况称为锁兼容,但是另外一个事务 T2 此时如果想获得行 r1 的 X 锁,则必须等待 T1 对行 r1 锁的释放,此种情况也称为锁冲突
锁粒度:
- 表级锁:MyISAM
- 行级锁:InnoDB
实现
- 存储引擎:自行实现其锁策略和锁粒度
- 服务器级:实现了锁,表级锁,用户可显式请求
分类:
- 隐式锁:由存储引擎自动施加锁
- 显式锁:用户手动请求
锁策略:在锁粒度及数据安全性寻求的平衡机制
4.7.2 显式使用锁
帮助:https://mariadb.com/kb/en/lock-tables/
加锁
LOCK TABLES tbl_name [[AS] alias] lock_type [, tbl_name [[AS] alias]
lock_type] ...
lock_type:
READ #读锁
WRITE #写锁
解锁
UNLOCK TABLES
关闭正在打开的表(清除查询缓存),通常在备份前加全局读锁
FLUSH TABLES [tb_name[,...]] [WITH READ LOCK]
查询时加写或读锁
SELECT clause [FOR UPDATE | LOCK IN SHARE MODE]
范例: 加读锁
mysql> lock tables students read;
Query OK, 0 rows affected (0.00 sec)
mysql> update students set classid=2 where stuid=24;
ERROR 1099 (HY000): Table 'students' was locked with a READ lock and can't be updated
mysql> unlock tables;
Query OK, 0 rows affected (0.01 sec)
mysql> update students set classid=2 where stuid=24;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
4.7.3 事务
事务 Transactions:一组原子性的 SQL语句,或一个独立工作单元
事务日志:记录事务信息,实现undo,redo等故障恢复功能
4.7.3.1 事务特性
ACID特性:
- A:atomicity 原子性;整个事务中的所有操作要么全部成功执行,要么全部失败后回滚
- C:consistency一致性;数据库总是从一个一致性状态转换为另一个一致性状态,类似于能量守恒定律(N50周启皓语录)
- I:Isolation隔离性;一个事务所做出的操作在提交之前,是不能为其它事务所见;隔离有多种隔离级别,实现并发
- D:durability持久性;一旦事务提交,其所做的修改会永久保存于数据库中
Transaction 生命周期
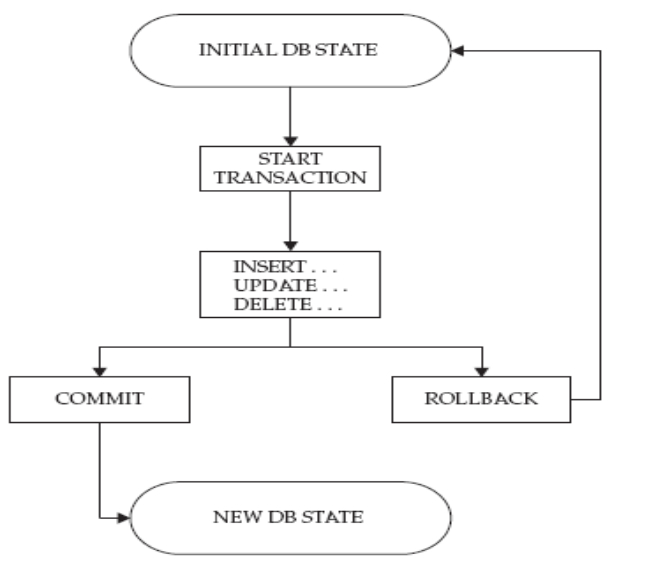
4.7.3.2 管理事务
显式启动事务:
BEGIN
BEGIN WORK
START TRANSACTION
结束事务
#提交,相当于vi中的wq保存退出
COMMIT
#回滚,相当于vi中的q!不保存退出
ROLLBACK
注意:只有事务型存储引擎中的DML语句方能支持此类操作
自动提交:
set autocommit={1|0} mysql与mariadb中默认为1
默认为1,为0时设为非自动提交
建议:显式请求和提交事务,而不要使用"自动提交"功能
事务支持保存点:
SAVEPOINT identifier
ROLLBACK [WORK] TO [SAVEPOINT] identifier
RELEASE SAVEPOINT identifier
查看事务:
#查看当前正在进行的事务
SELECT * FROM INFORMATION_SCHEMA.INNODB_TRX;
#以下两张表在MySQL8.0中已取消
#查看当前锁定的事务
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCKS;
#查看当前等锁的事务
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCK_WAITS;
死锁:
两个或多个事务在同一资源相互占用,并请求锁定对方占用的资源的状态
范例:找到未完成的导致阻塞的事务
#在第一个会话中执行
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> update students set classid=10;
Query OK, 25 rows affected (0.00 sec)
Rows matched: 25 Changed: 25 Warnings: 0
#在第二个会话中执行
mysql> update students set classid=20;
#在第三个会话中执行
show engine innodb status;
#查看正在进行的事务
mysql> SELECT * FROM INFORMATION_SCHEMA.INNODB_TRX\G
#杀掉未完成的事务
mysql> kill 10;
#查看事务锁的超时时长,默认50s
show global variables like 'innodb_lock_wait_timeout';
4.7.3.3 事务隔离级别
MySQL 支持四种隔离级别,事务隔离级别从上至下更加严格
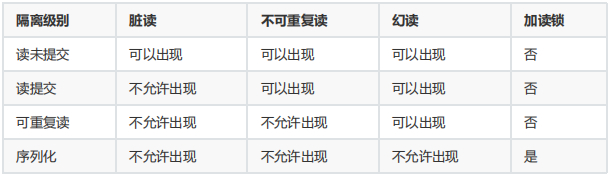
- READ UNCOMMITTED
可读取到未提交数据,产生脏读
- READ COMMITTED
可读取到提交数据,但未提交数据不可读,产生不可重复读,即可读取到多个提交数据,导致每次读取数据不一致
- REPEATABLE READ
可重复读,多次读取数据都一致,产生幻读,即读取过程中,即使有其它提交的事务修改数据,仍只能读取到未修改前的旧数据。此为MySQL默认设置
- SERIALIZABLE
可串行化,未提交的读事务阻塞修改事务(加读锁,但不阻塞读事务),或者未提交的修改事务阻塞其它事务的读写(加写锁,其它事务的读,写都不可以执行)。会导致并发性能差
MVCC和事务的隔离级别:
MVCC(多版本并发控制机制)只在READ COMMITTED和REPEATABLE READ两个隔离级别下工作。其他两个隔离级别都和MVCC不兼容,因为READ UNCOMMITTED总是读取最新的数据行,而不是符合当前事务版本的数据行。而SERIALIZABLE则会对所有读取的行都加锁
指定事务隔离级别:
- 服务器变量tx_isolation(MySQL8.0改名为transaction_isolation)指定,默认为REPEATABLE-READ,可在GLOBAL和SESSION级进行设置
#MySQL8.0之前版本
SET tx_isolation='READ-UNCOMMITTED|READ-COMMITTED|REPEATABLE
READ|SERIALIZABLE'
#MySQL8.0
SET transaction_isolation='READ-UNCOMMITTED|READ-COMMITTED|REPEATABLE
READ|SERIALIZABLE'
- 服务器选项中指定
vim /etc/my.cnf
[mysqld]
transaction-isolation=SERIALIZABLE
4.8 日志管理
MySQL 支持丰富的日志类型,如下:
- 事务日志:transaction log
- 事务日志的写入类型为"追加",因此其操作为"顺序IO";通常也被称为:预写式日志 write ahead logging 事务日志文件: ib_logfile0, ib_logfile1
- 错误日志 error log
- 通用日志 general log
- 慢查询日志 slow query log
- 二进制日志 binary log
- 中继日志 reley log,在主从复制架构中,从服务器用于保存从主服务器的二进制日志中读取的事件
4.8.1 事务日志
事务日志:transaction log
- redo log:实现 WAL(Write Ahead Log) ,数据更新前先记录redo log
- undo log:保存与执行的操作相反的操作,用于实现rollback
事务型存储引擎自行管理和使用,建议和数据文件分开存放
Innodb事务日志相关配置:
show variables like '%innodb_log%';
innodb_log_file_size 50331648 #每个日志文件大小
innodb_log_files_in_group 2 #日志组成员个数
innodb_log_group_home_dir ./ #事务文件路径
事务日志性能优化
innodb_flush_log_at_trx_commit=0|1|2
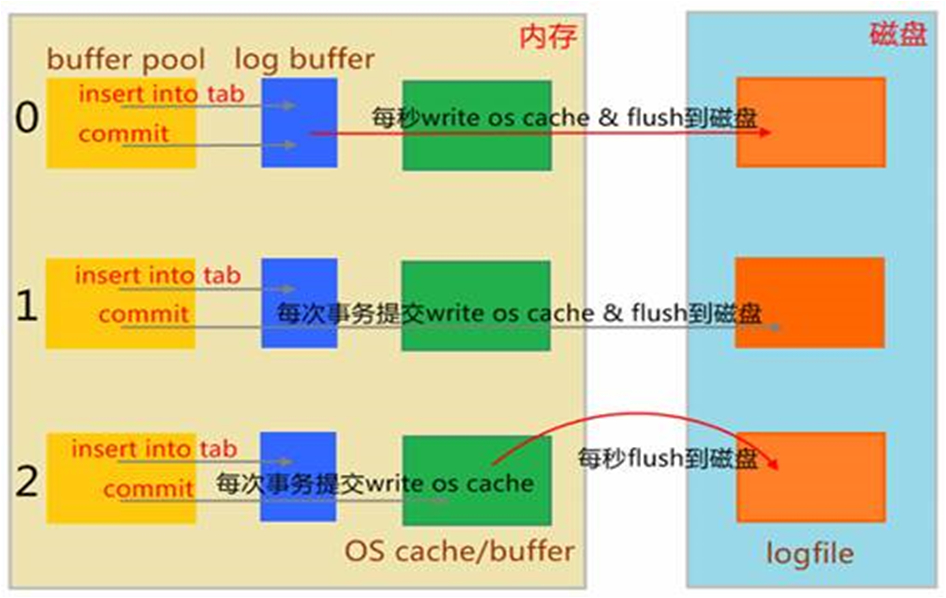
1 此为默认值,日志缓冲区将写入日志文件,并在每次事务后执行刷新到磁盘。 这是完全遵守ACID特性
0 提交时没有写磁盘的操作; 而是每秒执行一次将日志缓冲区的提交的事务写入刷新到磁盘。 这样可提供更好的性能,但服务器崩溃可能丢失最后一秒的事务
2 每次提交后都会写入OS的缓冲区,但每秒才会进行一次刷新到磁盘文件中。 性能比0略差一些,但操作系统或停电可能导致最后一秒的交易丢失
高并发业务行业最佳实践,是使用第三种折衷配置(=2):
1.配置为2和配置为0,性能差异并不大,因为将数据从Log Buffer拷贝到OS cache,虽然跨越用户态与内核态,但毕竟只是内存的数据拷贝,速度很快
2.配置为2和配置为0,安全性差异巨大,操作系统崩溃的概率相比MySQL应用程序崩溃的概率,小很多,设置为2,只要操作系统不奔溃,也绝对不会丢数据
说明:
- 设置为1,同时sync_binlog = 1表示最高级别的容错
- innodb_use_global_flush_log_at_trx_commit=0 时,将不能用SET语句重置此变量( MariaDB10.2.6 后废弃)
4.8.2 错误日志
错误日志
- mysqld启动和关闭过程中输出的事件信息
- mysqld运行中产生的错误信息
- event scheduler运行一个event时产生的日志信息
- 在主从复制架构中的从服务器上启动从服务器线程时产生的信息
错误文件路径
show global variables like 'log_error';
记录哪些警告信息至错误日志文件
#CentOS7 mariadb 5.5 默认值为1
#CentOS8 mariadb 10.3 默认值为2
log_warnings=0|1|2|3... #MySQL5.7之前
log_error_verbosity=0|1|2|3... #MySQL8.0
4.8.3 通用日志
通用日志:记录对数据库的通用操作,包括:错误的SQL语句
通用日志可以保存在:file(默认值)或 table(mysql.general_log表)
通用日志相关设置
general_log=ON|OFF #开启或关闭通用日志
general_log_file=HOSTNAME.log #通用日志记录位置
log_output=TABLE|FILE|NONE #日志输出方式,同时修改通用日志和慢查询日志
范例: 启用通用日志并记录至文件中
mysql> select @@general_log;
+---------------+
| @@general_log |
+---------------+
| 0 |
+---------------+
1 row in set (0.00 sec)
mysql> set global general_log=1;
Query OK, 0 rows affected (0.00 sec)
#默认通用日志存放在文件中
mysql> show variables like 'log_output';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| log_output | FILE |
+---------------+-------+
1 row in set (0.00 sec)
#通用文件存放路径
mysql> select @@general_log_file;
+----------------------------+
| @@general_log_file |
+----------------------------+
| /var/lib/mysql/centos8.log |
+----------------------------+
1 row in set (0.00 sec)
范例:通用日志记录到表中
#修改通用日志,记录通用日志至mysql.general_log表中
mysql> set global log_output='table';
Query OK, 0 rows affected (0.00 sec)
mysql> show variables like 'log_output';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| log_output | TABLE |
+---------------+-------+
1 row in set (0.00 sec)
#general_log表是CSV格式的存储引擎
mysql> show table status like 'general_log'\G;
*************************** 1. row ***************************
Name: general_log
Engine: CSV
Version: 10
Row_format: Dynamic
Rows: 1
Avg_row_length: 0
Data_length: 0
Max_data_length: 0
Index_length: 0
Data_free: 0
Auto_increment: NULL
Create_time: 2021-03-01 18:50:35
Update_time: NULL
Check_time: NULL
Collation: utf8_general_ci
Checksum: NULL
Create_options:
Comment: General log
1 row in set (0.01 sec)
[19:58:19 root@centos8 ~]#file /var/lib/mysql/mysql/general_log.CSV
/var/lib/mysql/mysql/general_log.CSV: ASCII text
范例: 查找执行次数最多的前三条语句
mysql> select argument,count(argument) num from mysql.general_log group by argument order by num desc limit 3;
范例:对访问的语句进行排序
[20:20:35 root@centos8 ~]#mysql -e 'select argument from mysql.general_log' | awk '{sql[$0]++}END{for(i in sql){print sql[i],i}}'|sort -nr
[20:22:41 root@centos8 ~]#mysql -e 'select argument from mysql.general_log' |sort |uniq -c |sort -nr
4.8.4 慢查询日志
慢查询日志:记录执行查询时长超出指定时长的操作
慢查询相关变量
slow_query_log=ON|OFF #开启或关闭慢查询,支持全局和会话,只有全局设置才会生成慢查询文件
long_query_time=N #慢查询的阀值,单位秒,默认为10s
slow_query_log_file=HOSTNAME-slow.log #慢查询日志文件
log_slow_filter = admin,filesort,filesort_on_disk,full_join,full_scan,
query_cache,query_cache_miss,tmp_table,tmp_table_on_disk
#上述查询类型且查询时长超过long_query_time,则记录日志
log_queries_not_using_indexes=ON #不使用索引或使用全索引扫描,不论是否达到慢查询阀值的语句是否记录日志,默认OFF,即不记录
log_slow_rate_limit = 1 #多少次查询才记录,mariadb特有
log_slow_verbosity= Query_plan,explain #记录内容
log_slow_queries = OFF #同slow_query_log,MariaDB 10.0/MySQL 5.6.1 版后已删除
范例: 慢查询分析工具mysqldumpslow
[20:25:49 root@centos8 ~]#mysqldumpslow --help
[20:40:34 root@centos8 ~]#mysqldumpslow -s c -t 2 /var/lib/mysql/centos8-slow.log
Reading mysql slow query log from /var/lib/mysql/centos8-slow.log
Count: 9 Time=0.00s (0s) Lock=0.00s (0s) Rows=4.0 (36), root[root]@localhost
select * from mysql.slow_log
Count: 8 Time=0.00s (0s) Lock=0.00s (0s) Rows=1.0 (8), root[root]@localhost
select * from students where name='S'
4.8.5 使用 profile 工具
#打开后,会显示语句执行详细的过程
#mysql8.0已经弃用
set profiling = ON;
#查看语句,注意结果中的query_id值
show pshow profiles ;
#显示语句的详细执行步骤和时长
Show profile for query #
#显示cpu使用情况
Show profile cpu for query #
4.8.6 二进制日志(备份)
- 记录导致数据改变或潜在导致数据改变的SQL语句
- 记录已提交的日志
- 不依赖于存储引擎类型
功能:通过"重放"日志文件中的事件来生成数据副本
注意:建议二进制日志和数据文件分开存放
二进制日志记录三种格式
- 基于"语句"记录:statement,记录语句,默认模式( MariaDB 10.2.3 版本以下 ),日志量较少
- 基于"行"记录:row,记录数据,日志量较大,更加安全,建议使用的格式,MySQL8.0默认格式
- 混合模式:mixed, 让系统自行判定该基于哪种方式进行,默认模式( MariaDB 10.2.4及版本以上)
格式配置
MariaDB [hellodb]> show variables like 'binlog_format';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| binlog_format | MIXED |
+---------------+-------+
1 row in set (0.001 sec)
#mysql8.0默认ROW
mysql> show variables like 'binlog_format';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| binlog_format | ROW |
+---------------+-------+
1 row in set (0.01 sec)
二进制日志文件的构成
有两类文件
1.日志文件:mysql|mariadb-bin.文件名后缀,二进制格式,如: on.000001,mariadb-bin.000002
2.索引文件:mysql|mariadb-bin.index,文本格式,记录当前已有的二进制日志文件列表
二进制日志相关的服务器变量:
sql_log_bin=ON|OFF:#是否记录二进制日志,默认ON,支持动态修改,系统变量,而非服务器选项
log_bin=/PATH/BIN_LOG_FILE:#指定文件位置;默认OFF,表示不启用二进制日志功能,上述两项都开启才可以
binlog_format=STATEMENT|ROW|MIXED:#二进制日志记录的格式,默认STATEMENT
max_binlog_size=1073741824:#单个二进制日志文件的最大体积,到达最大值会自动滚动,默认为1G
#说明:文件达到上限时的大小未必为指定的精确值
binlog_cache_size=4m #此变量确定在每次事务中保存二进制日志更改记录的缓存的大小(每次连接)
max_binlog_cache_size=512m #限制用于缓存多事务查询的字节大小。
sync_binlog=1|0:#设定是否启动二进制日志即时同步磁盘功能,默认0,由操作系统负责同步日志到磁盘
expire_logs_days=N:#二进制日志可以自动删除的天数。 默认为0,即不自动删除
二进制日志相关配置
查看mariadb自行管理使用中的二进制日志文件列表,及大小
SHOW {BINARY | MASTER} LOGS
查看使用中的二进制日志文件
SHOW MASTER STATUS
在线查看二进制文件中的指定内容
SHOW BINLOG EVENTS [IN 'log_name'] [FROM pos] [LIMIT [offset,] row_count]
范例:
mysql> show binlog events;
mysql> show binlog events in 'binlog.000001' from 12627\G;
mysqlbinlog:二进制日志的客户端命令工具,支持离线查看二进制日志
命令格式:
mysqlbinlog [OPTIONS] log_file…
--start-position=# 指定开始位置
--stop-position=#
--start-datetime= #时间格式:YYYY-MM-DD hh:mm:ss
--stop-datetime=
--base64-output[=name]
-v -vvv
范例:
mysqlbinlog --start-position=678 --stop-position=752 /var/lib/mysql/mariadb
bin.000003 -v
mysqlbinlog --start-datetime="2018-01-30 20:30:10" --stop-datetime="2018-01-
30 20:35:22" mariadb-bin.000003 -vvv
二进制日志事件的格式:
# at 328
#151105 16:31:40 server id 1 end_log_pos 431 Query thread_id=1
exec_time=0 error_code=0
use `mydb`/*!*/;
SET TIMESTAMP=1446712300/*!*/;
CREATE TABLE tb1 (id int, name char(30))
/*!*/;
事件发生的日期和时间:151105 16:31:40
事件发生的服务器标识:server id 1
事件的结束位置:end_log_pos 431
事件的类型:Query
事件发生时所在服务器执行此事件的线程的ID:thread_id=1
语句的时间戳与将其写入二进制文件中的时间差:exec_time=0
错误代码:error_code=0
事件内容:
GTID:Global Transaction ID,mysql5.6以mariadb10以上版本专属属性:GTID
清除指定二进制日志
PURGE { BINARY | MASTER } LOGS { TO 'log_name' | BEFORE datetime_expr }
范例:
PURGE BINARY LOGS TO 'mariadb-bin.000003'; #删除mariadb-bin.000003之前的日志
PURGE BINARY LOGS BEFORE '2017-01-23';
PURGE BINARY LOGS BEFORE '2017-03-22 09:25:30';
删除所有二进制日志,index文件重新记数
RESET MASTER [TO #];
#删除所有二进制日志文件,并重新生成日志文件,文件名从#开始记数,默认从
1开始,一般是master主机第一次启动时执行,MariaDB 10.1.6开始支持TO #
切换日志文件:
FLUSH LOGS;
五、备份和恢复
5.1 备份恢复概述
5.1.1 为什么要备份
灾难恢复:硬件故障、软件故障、自然灾害、黑客攻击、误操作测试等数据丢失场景
5.1.2 备份类型
- 完全备份,部分备份
- 完全备份:整个数据集
- 部分备份:只备份数据子集,如部分库或表
- 完全备份、增量备份、差异备份
- 增量备份:仅备份最近一次完全备份或增量备份(如果存在增量)以来变化的数据,备份较快,还原复杂

- 增量备份:仅备份最近一次完全备份或增量备份(如果存在增量)以来变化的数据,备份较快,还原复杂
差异备份:仅备份最近一次完全备份以来变化的数据,备份较慢,还原简单
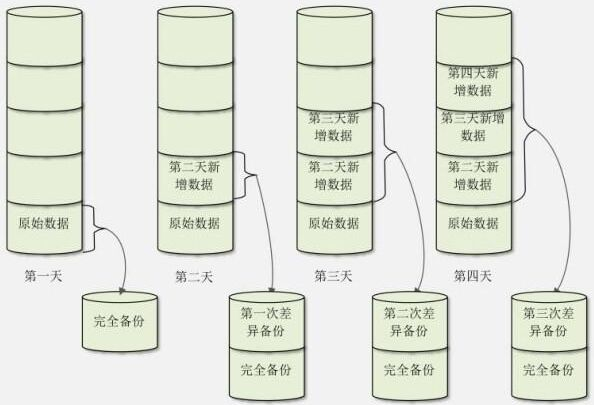
注意:二进制日志文件不应该与数据文件放在同一磁盘
- 冷、温、热备份
- 冷备:读、写操作均不可进行,数据库停止服务
- 温备:读操作可执行;但写操作不可执行
- 热备:读、写操作均可执行
- MyISAM:温备,不支持热备
- InnoDB:都支持
- 物理和逻辑备份
- 物理备份:直接复制数据文件进行备份,与存储引擎有关,占用较多的空间,速度快
- 逻辑备份:从数据库中"导出"数据另存而进行的备份,与存储引擎无关,占用空间少,速度慢,可能丢失精度
5.1.3 备份什么
- 数据
- 二进制日志、InnoDB的事务日志
- 用户帐号,权限设置,程序代码(存储过程、函数、触发器、事件调度器)
- 服务器的配置文件
5.1.4 备份注意要点
- 能容忍最多丢失多少数据
- 备份产生的负载
- 备份过程的时长
- 温备的持锁多久
- 恢复数据需要在多长时间内完成
- 需要备份和恢复哪些数据
5.1.5 还原要点
- 做还原测试,用于测试备份的可用性
- 还原演练,写成规范的技术文档
5.1.6 备份工具
- cp, tar等复制归档工具:物理备份工具,适用所有存储引擎;只支持冷备;完全和部分备份
- LVM的快照:先加读锁,做快照后解锁,几乎热备;借助文件系统工具进行备份
- mysqldump:逻辑备份工具,适用所有存储引擎,对MyISAM存储引擎进行温备;支持完全或部分备份;对InnoDB存储引擎支持热备,结合binlog的增量备份
- xtrabackup:由Percona提供支持对InnoDB做热备(物理备份)的工具,支持完全备份、增量备份
- MariaDB Backup: 从MariaDB 10.1.26开始集成,基于Percona XtraBackup 2.3.8实现
- mysqlbackup:热备份, MySQL Enterprise Edition 组件
- mysqlhotcopy:PERL 语言实现,几乎冷备,仅适用于MyISAM存储引擎,使用LOCK TABLES、FLUSH TABLES和cp或scp来快速备份数据库
5.1.7 基于 LVM 的快照备份
(1) 请求锁定所有表
mysql> FLUSH TABLES WITH READ LOCK;
(2) 记录二进制日志文件及事件位置
mysql> FLUSH LOGS;
mysql> SHOW MASTER STATUS;
mysql -e 'SHOW MASTER STATUS' > /PATH/TO/SOMEFILE
(3) 创建快照
lvcreate -L # -s -p r -n NAME /DEV/VG_NAME/LV_NAME
(4) 释放锁
mysql> UNLOCK TABLES;
(5) 挂载快照卷,执行数据备份
(6) 备份完成后,删除快照卷
(7) 制定好策略,通过原卷备份二进制日志
5.1.8 实战案例:数据库冷备份和还原
#在目标服务器(192.168.10.82)安装mariadb-server,不启动服务
#在源主机(192.168.10.81)执行
[10:21:40 root@centos8 ~]#systemctl stop mariadb.service
#复制相关文件,如有二进制日志也需要复制
[10:29:58 root@centos8 ~]#scp -r /var/lib/mysql/* 192.168.10.82:/var/lib/mysql
[10:29:58 root@centos8 ~]#scp /etc/my.cnf.d/mariadb-server.cnf 192.168.10.82:/etc/my.cnf.d/
#在目标主机(10.0.0.18)执行
[10:32:02 root@centos8 ~]#chown -R mysql.mysql /var/lib/mysql/
[10:32:11 root@centos8 ~]#systemctl start mariadb.service
5.2 mysqldump 备份工具
5.2.1 mysqldump 说明
逻辑备份工具:
mysqldump, mydumper, phpMyAdmin
Schema和数据存储在一起、巨大的SQL语句、单个巨大的备份文件
mysqldump是MySQL的客户端命令,通过mysql协议连接至mysql服务器进行备份
命令格式:
mysqldump [OPTIONS] database [tables] #支持指定数据库和指定多表的备份,但数据库本身定
义不备份
mysqldump [OPTIONS] -B DB1 [DB2 DB3...] #支持指定数据库备份,包含数据库本身定义也会备份
mysqldump [OPTIONS] -A [OPTIONS] #备份所有数据库,包含数据库本身定义也会备份
mysqldump参考:
https://dev.mysql.com/doc/refman/5.7/en/mysqldump.html
mysqldump 常见通用选项:
-A, --all-databases #备份所有数据库,含create database
-B, --databases db_name… #指定备份的数据库,包括create database语句
-E, --events: #备份相关的所有event scheduler
-R, --routines: #备份所有存储过程和自定义函数
--triggers: #备份表相关触发器,默认启用,用--skip-triggers,不备份触发器
--default-character-set= #指定字符集
--master-data[=#]: #此选项须启用二进制日志
#1:所备份的数据之前加一条记录为CHANGE MASTER TO语句,非注释,不指定#,默认为1,适合于主从复
制多机使用
#2:记录为被注释的#CHANGE MASTER TO语句,适合于单机使用,适用于备份还原
#此选项会自动关闭--lock-tables功能,自动打开-x | --lock-all-tables功能(除非开启--
single-transaction)
-F, --flush-logs #备份前滚动日志,锁定表完成后,执行flush logs命令,生成新的二进制日志文
件,配合-A 或 -B 选项时,会导致刷新多次数据库。建议在同一时刻执行转储和日志刷新,可通过和--
single-transaction或-x,--master-data 一起使用实现,此时只刷新一次二进制日志
--compact #去掉注释,适合调试,节约备份占用的空间,生产不使用
-d, --no-data #只备份表结构,不备份数据,即只备份create table
-t, --no-create-info #只备份数据,不备份表结构,即不备份create table
-n,--no-create-db #不备份create database,可被-A或-B覆盖
--flush-privileges #备份mysql或相关时需要使用
-f, --force #忽略SQL错误,继续执行
--hex-blob #使用十六进制符号转储二进制列,当有包括BINARY, VARBINARY,
BLOB,BIT的数据类型的列时使用,避免乱码
-q, --quick #不缓存查询,直接输出,加快备份速度
mysqldump的MyISAM存储引擎相关的备份选项:
MyISAM不支持事务,只能支持温备;不支持热备,所以必须先锁定要备份的库,而后启动备份操作
-x,--lock-all-tables #加全局读锁,锁定所有库的所有表,同时加--single-transaction或--
lock-tables选项会关闭此选项功能,注意:数据量大时,可能会导致长时间无法并发访问数据库
-l,--lock-tables #对于需要备份的每个数据库,在启动备份之前分别锁定其所有表,默认为on,--
skip-lock-tables选项可禁用,对备份MyISAM的多个库,可能会造成数据不一致
#注:以上选项对InnoDB表一样生效,实现温备,但不推荐使用
mysqldump的InnoDB存储引擎相关的备份选项:
InnoDB 存储引擎支持事务,可以利用事务的相应的隔离级别,实现热备,也可以实现温备但不建议用
--single-transaction
#此选项Innodb中推荐使用,不适用MyISAM,此选项会开始备份前,先执行START TRANSACTION指令开启事务
#此选项通过在单个事务中转储所有表来创建一致的快照。 仅适用于存储在支持多版本控制的存储引擎中的表(目前只有InnoDB可以); 转储不保证与其他存储引擎保持一致。 在进行单事务转储时,要确保有效的转储文件(正确的表内容和二进制日志位置),没有其他连接应该使用以下语句:ALTER TABLE,DROP TABLE,RENAME TABLE,TRUNCATE TABLE,此选项和--lock-tables(此选项隐含提交挂起的事务)选项是相互排斥,备份大型表时,建议将--single-transaction选项和--quick结合一起使用
5.2.2 生产环境实战备份策略
InnoDB建议备份策略
mysqldump -uroot -p -A -F -E -R --triggers --single-transaction --master-data=1
--flush-privileges --default-character-set=utf8 --hex-blob > ${BACKUP}/fullbak_${BACKUP_TIME}.sql
MyISAM建议备份策略
mysqldump -uroot -p -A -F -E -R -x --master-data=1 --flush-privileges --
triggers --default-character-set=utf8 --hex-blob
> ${BACKUP}/fullbak_${BACKUP_TIME}.sql
5.2.3 mysqldump 备份还原实战案例
5.2.3.1 实战案例:特定数据库的备份脚本
TIME=`date +%F_%H-%M-%S`
DIR=/mysql/backup
DB=hellodb
PASS=123456
mysqldump -uroot -p${PASS} -F -E -R --triggers --single-transaction --master-data=2 --default-character-set=utf8 -q -B ${DB} | gzip > ${DIR}/${DB}_${TIME}.sql.gz
5.2.3.2 实战案例:分库备份并压缩,演示思路切勿对真实环境使用
#for循环写法
[11:28:05 root@centos8 ~]#for db in `mysql -uroot -p123456 -e 'show databases;' | grep -Ev '^(information_schema|performance_schema|Database)$'`;do mysqldump -uroot -p123456 -B $db | gzip >/root/mysql/$db.sql.gz;done
#while循环写法
[11:30:04 root@centos8 ~]#mysql -uroot -p123456 -e 'show databases;' | grep -Ev '^(information_schema|performance_schema|Database)$' | while read db;do mysqldump -uroot -p123456 -B $db | gzip >/root/mysql/while_$db.sql.gz;done
#sed写法1
[11:36:17 root@centos8 ~]#mysql -uroot -p123456 -e 'show databases;' | grep -Ev '^(information_schema|performance_schema|Database)$' | sed -nr 's#(.*)#mysqldump -uroot -p123456 -B \1 | gzip >/root/mysql/sed_\1.sql.gz#p' | bash
#sed写法2
[11:40:54 root@centos8 ~]#mysql -uroot -p123456 -e 'show databases' | sed -nr '/^(Database|information_schema|performance_schema)$/!s#(.*)#mysqldump -uroot -p123456 -B \1 | gzip >/root/mysql/sed2_\1.sql.gz#p' | bash
5.2.3.3 实战案例:分库备份的实战脚本
TIME=`date +%F_%H-%M-%S`
DIR=/backup
PASS=123456
[ -d "$DIR" ] || mkdir $DIR
for DB in `mysql -uroot -p"$PASS" -e "show databases" | grep -Ev "^(Database|.*schema|sys)$"`;do
mysqldump -uroot -p"$PASS" -F --single-transaction --master-data=2 --default-character-set=utf8 -q -B $DB | gzip > ${DIR}/${DB}_${TIME}.sql.gz
done
5.2.3.4 实战案例:完全备份和还原
#开启二进制日志
[root@centos8 ~]#vim /etc/my.cnf.d/mariadb-server.cnf
[mysqld]
log-bin
#备份
[19:26:31 root@centos8 backup]#mysqldump -uroot -p123456 -A -F --single-transaction --master-data=2 | gzip >/backup/all-`date +%F`.sql.gz
#还原
[root@centos8 backup]#dnf install mysql-server
[root@centos8 backup]#gzip -d all-2019-11-27.sql.gz
mysql> set sql_log_bin=off;
mysql> source /root/all-2021-03-05.sql
mysql> set sql_log_bin=on;
注意:恢复数据时推荐先关闭二进制日志,恢复完成后再次打开
5.2.3.5 实战案例:利用二进制日志,还原数据库最新状态
#二进制日志独立存放
[mysqld]
log-bin=/data/mysql/mysql-bin
#完全备份,并记录备份的二进制位置
[19:35:11 root@centos8 ~]#mysqldump -uroot -p123456 -A -F --default-character-set=utf8 --single-transaction --master-data=2 | gzip >/backup/all-`date +%F`.sql.gz
#修改数据库
mysql> insert into students (name,age,gender)values('zhang',20,'M');
mysql> insert into students (name,age,gender)values('zhang',30,'M');
#损坏数据库
[19:39:06 root@centos8 ~]#rm -rvf /var/lib/mysql/*
#还原
[19:39:06 root@centos8 ~]#cd /backup/
[19:39:31 root@centos8 backup]#gzip -d all-2021-03-05.sql.gz
#CentOS 7需要事先生成数据库相关文件,CentOS8 不需要执行此步
mysql_install_db --user=mysql
systemctl restart mariadb
#如果启动不了,再次清理/var/lib/mysql/目录中的文件
mysql> show master logs;
+------------------+-----------+-----------+
| Log_name | File_size | Encrypted |
+------------------+-----------+-----------+
| mysql-bin.000001 | 203 | No |
| mysql-bin.000002 | 203 | No |
| mysql-bin.000003 | 203 | No |
| mysql-bin.000004 | 203 | No |
| mysql-bin.000005 | 789 | No |
| mysql-bin.000006 | 179 | No |
| mysql-bin.000007 | 156 | No |
+------------------+-----------+-----------+
7 rows in set (0.00 sec)
mysql> set sql_log_bin=off;
mysql> source /backup/all-2021-03-05.sql
[19:49:44 root@centos8 ~]#grep '^-- CHANGE MASTER TO' /backup/all-2021-03-05.sql
-- CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000005', MASTER_LOG_POS=156;
#二进制日志的备份
[19:50:37 root@centos8 mysql_log_bin]#mysqlbinlog mysql-bin.000005 --start-position=156 >/backup/inc.sql
mysql> source /backup/inc.sql;
mysql> set sql_log_bin=on;
六、MySQL 集群 Cluster
服务性能扩展方式
- Scale Up,向上扩展,垂直扩展
- Scale Out,向外扩展,横向扩展
6.1 MySQL 主从复制
6.1.1 主从复制架构和原理
6.1.1.1 MySQL的主从复制
- 读写分离
- 复制:每个节点都有相同的数据集,向外扩展,基于二进制日志的单向复制
6.1.1.2 复制的功用
- 负载均衡读操作
- 备份
- 高可用和故障切换
- 数据分布
- MySQL升级
6.1.1.3 复制架构
一主一从复制架构
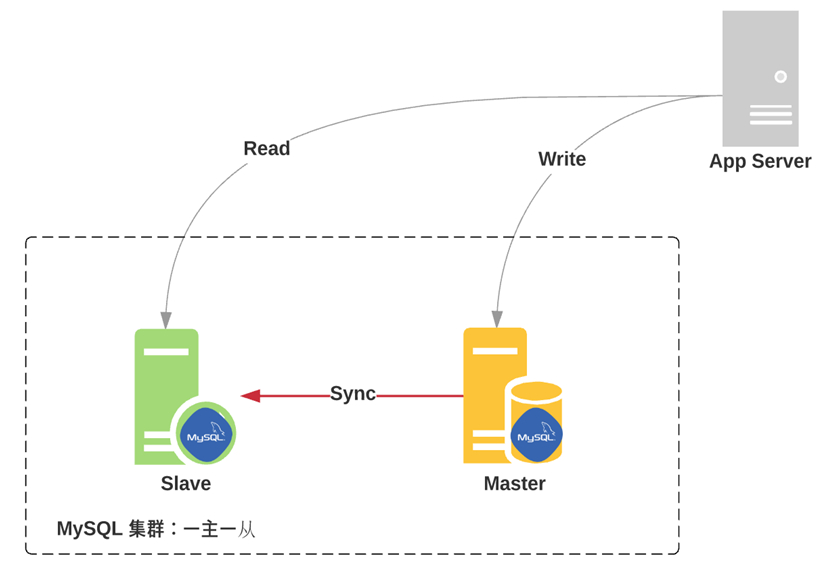
一主多从复制架构
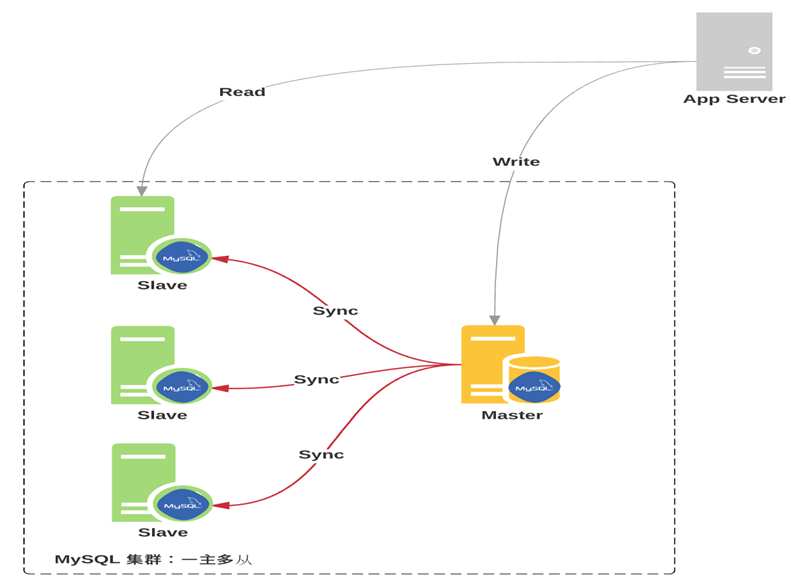
6.1.1.4 主从复制原理
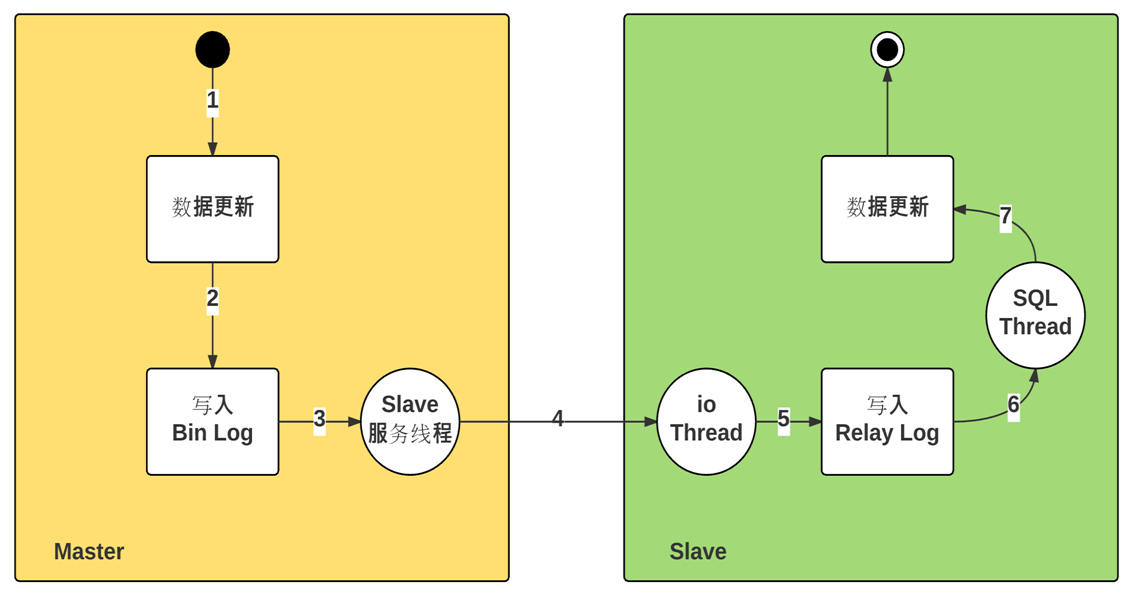
主从复制相关线程
- 主节点
- dump Thread:为每个Slave的I/O Thread启动一个dump线程,用于向其发送binary log events
- 从节点
- I/O Thread:向Master请求二进制日志事件,并保存于中继日志中
- SQL Thread:从中继日志中读取日志事件,在本地完成重放
跟复制功能相关的文件:
- master.info:用于保存slave连接至master时的相关信息,例如账号、密码、服务器地址等
- relay-log.info:保存在当前slave节点上已经复制的当前二进制日志和本地relay log日志的对应关系
- mysql-relay-bin.00000#: 中继日志,保存从主节点复制过来的二进制日志,本质就是二进制日志
说明:
MySQL8.0 取消master.info和relay-log.info文件
6.1.1.5 主从复制特点
- 异步复制: 客户端性能良好
- 主从数据不一致比较常见
6.1.1.6 各种复制架构
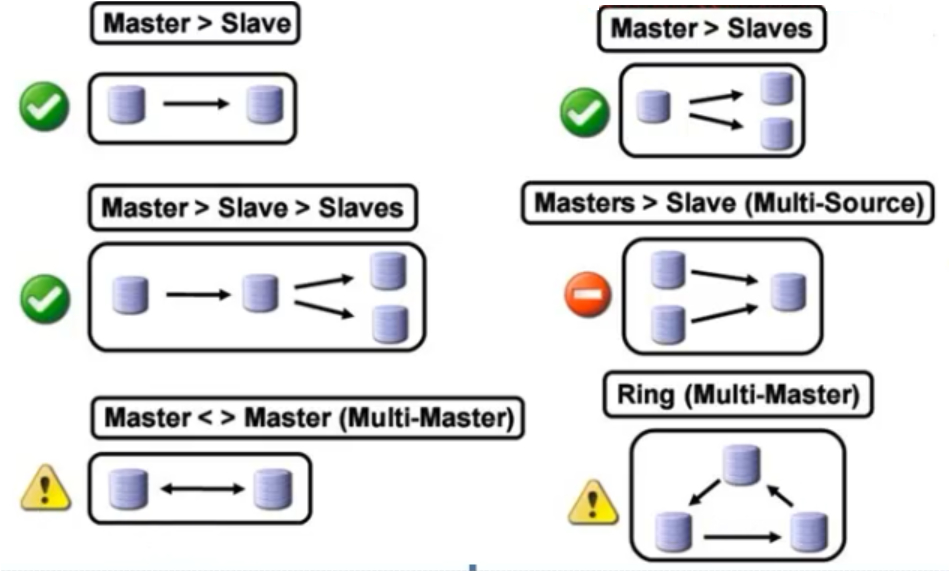
- 一Master/一Slave
- 一主多从
- 从服务器还可以再有从服务器
- Master/Master
- 一从多主:适用于多个不同数据库
- 环状复制
复制需要考虑二进制日志事件记录格式
- STATEMENT(5.0之前), Mariadb5.5 默认使用此格式
- ROW(5.1之后,推荐),MySQL 8.0 默认使用此格式
- MIXED: Mariadb10.3 默认使用此格式
6.1.2 实现主从复制配置
官网参考
https://dev.mysql.com/doc/refman/8.0/en/replication-configuration.html
https://dev.mysql.com/doc/refman/5.7/en/replication-configuration.html
https://dev.mysql.com/doc/refman/5.5/en/replication-configuration.html
https://mariadb.com/kb/en/library/setting-up-replication/
主节点配置:
(1) 启用二进制日志
[mysqld]
log_bin
(2) 为当前节点设置一个全局惟一的ID号
[mysqld]
server-id=#
log-basename=master #可选项,设置datadir中日志名称,确保不依赖主机名
说明:
server-id的取值范围
1 to 4294967295 (>= MariaDB 10.2.2),默认值为1
0 to 4294967295 (<= MariaDB 10.2.1),默认值为0,如果从节点为0,所有master都将拒绝此slave的连接
(3) 查看从二进制日志的文件和位置开始进行复制
SHOW MASTER STATUS;
(4) 创建有复制权限的用户账号
GRANT REPLICATION SLAVE ON *.* TO 'repluser'@'HOST' IDENTIFIED BY 'replpass';
从节点配置:
(1) 启动中继日志
[mysqld]
server_id=# #为当前节点设置一个全局惟的ID号
log-bin
read_only=ON #设置数据库只读,针对supper user无效
relay_log=relay-log #relay log的文件路径,默认值hostname-relay-bin
relay_log_index=relay-log.index #默认值hostname-relay-bin.index
(2) 使用有复制权限的用户账号连接至主服务器,并启动复制线程
CHANGE MASTER TO MASTER_HOST='masterhost',
MASTER_USER='repluser',
MASTER_PASSWORD='replpass',
MASTER_LOG_FILE='mariadb-bin.xxxxxx',
MASTER_LOG_POS=#;
START SLAVE [IO_THREAD|SQL_THREAD];
SHOW SLAVE STATUS;
范例:新建主从复制
#主节点
[10:33:48 root@master ~]#dnf install -y mysql-server
[10:34:41 root@master ~]#vim /etc/my.cnf.d/mysql-server.cnf
[mysqld]
server-id=81
log-bin
[10:35:17 root@master ~]#systemctl enable --now mysqld.service
#查看二进制文件和位置
mysql> show master logs;
+-------------------+-----------+-----------+
| Log_name | File_size | Encrypted |
+-------------------+-----------+-----------+
| master-bin.000001 | 179 | No |
| master-bin.000002 | 156 | No |
+-------------------+-----------+-----------+
#创建复制用户
MariaDB [(none)]> grant replication slave on *.* to slave@'192.168.10.%'
identified by '123456';
#mysql8.0需要分为俩步
mysql> create user 'slave'@'192.168.10.%' identified by '123456';
mysql> grant replication slave on *.* to 'slave'@'192.168.10.%';
#从节点
[10:40:46 root@slave ~]#vim /etc/my.cnf.d/mysql-server.cnf
[mysqld]
server-id=82
mysql> change master to master_host='192.168.10.81',master_user='slave',master_password='123456',master_port=3306,master_log_file='master-bin.000001',master_log_pos=179;
mysql> start slave;
Query OK, 0 rows affected (0.01 sec)
mysql> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.10.81
Master_User: slave
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: master-bin.000002
Read_Master_Log_Pos: 1341
Relay_Log_File: slave-relay-bin.000003
Relay_Log_Pos: 1558
Relay_Master_Log_File: master-bin.000002
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 1341
Relay_Log_Space: 1936
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0 #复制的延迟时间
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 81
Master_UUID: a478643e-7e24-11eb-b07c-000c297ba8b9
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set:
Auto_Position: 0
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
Master_public_key_path:
Get_master_public_key: 0
Network_Namespace:
#查看线程
mysql> mysql> show processlist;
范例:主服务器非新建时,主服务器运行一段时间后,新增从节点服务器
如果主节点已经运行了一段时间,且有大量数据时,如何配置并启动slave节点
- 通过备份恢复数据至从服务器
- 复制起始位置为备份时,二进制日志文件及其POS
#在服务器完全备份
[11:20:13 root@master ~]#mysqldump -A -F --single-transaction --master-data=1 >all.sql
[11:20:59 root@master ~]#ll all.sql
-rw-r--r-- 1 root root 3646553 Mar 6 11:20 all.sql
[11:21:20 root@master ~]#scp all.sql 192.168.10.83:/root
#将完全备份还原到新的从节点
[11:20:00 root@centos8 ~]#yum install -y mysql-server
[mysqld]
server-id=83
read-only #只读数据库,对root没有效果
[11:23:58 root@centos8 ~]#systemctl enable --now mysqld
#配置从节点,从完全备份的位置之后开始复制
[11:25:07 root@centos8 ~]#vim all.sql
CHANGE MASTER TO
master_host='192.168.10.81',
master_user='slave',
master_password='123456',
master_port=3306,
MASTER_LOG_FILE='master-bin.000003', MASTER_LOG_POS=156;
[11:29:03 root@centos8 ~]#mysql < all.sql
mysql> show slave status\G
*************************** 1. row ***************************
Slave_IO_State:
Master_Host: 192.168.10.81
Master_User: slave
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: master-bin.000003
Read_Master_Log_Pos: 156
Relay_Log_File: centos8-relay-bin.000001
Relay_Log_Pos: 4
Relay_Master_Log_File: master-bin.000003
Slave_IO_Running: No
Slave_SQL_Running: No
mysql> start slave;
6.1.3 主从复制相关
6.1.3.1 限制从服务器为只读
read_only=ON
#注意:此限制对拥有SUPER权限的用户均无效
注意:以下命令会阻止所有用户, 包括主服务器复制的更新
FLUSH TABLES WITH READ LOCK;
6.1.3.2 在从节点清除信息
注意:以下都需要先 STOP SLAVE
RESET SLAVE #从服务器清除master.info ,relay-log.info, relay log ,开始新的relay log
RESET SLAVE ALL #清除所有从服务器上设置的主服务器同步信息,如HOST,PORT, USER和PASSWORD 等
6.1.3.3 复制错误解决方法
可以在从服务器忽略几个主服务器的复制事件,此为global变量,或指定跳过事件的ID
注意: Centos 8.1以上版本上的MariaDB10.3主从节点同时建同名的库和表不会冲突,建主键记录会产生冲突
#系统变量,指定跳过复制事件的个数
SET GLOBAL sql_slave_skip_counter = N
#服务器选项,只读系统变量,指定跳过事件的ID
[mysqld]
slave_skip_errors=1007|ALL
范例:复制冲突的解决
#CentOS7上Mariadb5.5 在slave创建库和表,再在master上创建同名的库和表,会出现复制冲突,而在
CentOS8上的Mariadb10.3上不会冲突
#如果添加相同的主键记录都会冲突
MariaDB [(none)]> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.39.8
Master_User: repluser
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mariadb-bin.000002
Read_Master_Log_Pos: 26988271
Relay_Log_File: mariadb-relay-bin.000003
Relay_Log_Pos: 557
Relay_Master_Log_File: mariadb-bin.000002
Slave_IO_Running: Yes
Slave_SQL_Running: No
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 1007
Last_Error: Error 'Can't create database 'db4'; database
exists' on query. Default database: 'db4'. Query: 'create database db4'
Skip_Counter: 0
Exec_Master_Log_Pos: 26988144
Relay_Log_Space: 26988895
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: NULL
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 1007 #错误编码
Last_SQL_Error: Error 'Can't create database 'db4'; database
exists' on query. Default database: 'db4'. Query: 'create database db4'
Replicate_Ignore_Server_Ids:
Master_Server_Id: 8
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: No
Gtid_IO_Pos:
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: conservative
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State:
Slave_DDL_Groups: 37
Slave_Non_Transactional_Groups: 0
Slave_Transactional_Groups: 100006
1 row in set (0.000 sec)
#方法1
MariaDB [(none)]> stop slave;
MariaDB [(none)]> set global sql_slave_skip_counter=1;
MariaDB [(none)]> start slave;
#方法2
[root@slave1 ~]#vim /etc/my.cnf.d/mariadb-server.cnf
[mysqld]
slave_skip_errors=1007|ALL
[root@slave1 ~]#systemctl restart mariadb
6.1.3.4 START SLAVE 语句,指定执到特定的点
START SLAVE [thread_types]
START SLAVE [SQL_THREAD] UNTIL MASTER_LOG_FILE = 'log_name', MASTER_LOG_POS =log_pos
START SLAVE [SQL_THREAD] UNTIL RELAY_LOG_FILE = 'log_name', RELAY_LOG_POS =log_pos
thread_types:
[thread_type [, thread_type] ... ]
thread_type: IO_THREAD | SQL_THREAD
6.1.3.5 保证主从复制的事务安全
参看https://mariadb.com/kb/en/library/server-system-variables/
在master节点启用参数:
sync_binlog=1 #每次写后立即同步二进制日志到磁盘,性能差
#如果用到的为InnoDB存储引擎:
innodb_flush_log_at_trx_commit=1 #每次事务提交立即同步日志写磁盘
sync_master_info=# #次事件后master.info同步到磁盘
innodb_support_xa=ON #分布式事务MariaDB10.3.0废除
在slave节点启用服务器选项:
skip-slave-start=ON #不自动启动slave
在slave节点启用参数:
sync_relay_log=# #次写后同步relay log到磁盘
sync_relay_log_info=# #次事务后同步relay-log.info到磁盘
6.1.4 实现级联复制
需要在中间的从服务器启用以下配置 ,实现中间slave节点能将master的二进制日志在本机进行数据库更新,并且也同时更新本机的二进制,从而实现级联复制
[mysqld]
server-id=18
log_bin
log_slave_updates #级联复制中间节点的必选项,MySQL8.0此为默认值,可以不要人为添加
read-only
案例:三台主机实现级联复制
#在192.168.10.81充当master
#在192.168.10.82充当级联slave
#在192.168.10.83充当slave
#在master实现
[mysqld]
server-id=81
log-bin
[12:10:31 root@master ~]#systemctl enable --now mysqld.service
创建复制用户
mysql> create user slave@'192.168.10.%' identified by '123456';
mysql> grant replication slave on *.* to slave@'192.168.10.%';
[12:12:37 root@master ~]#mysqldump -A -F --single-transaction --master-data=1 >all.sql
[12:13:05 root@master ~]#scp all.sql 192.168.10.82:/root
[12:13:05 root@master ~]#scp all.sql 192.168.10.83:/root
#在中间级联slave实现
[mysqld]
server-id=82
log-bin
read-only
log_slave_updates #级联复制中间节点的必选项,MySQL8.0此为默认值,可以不要人为添加
[12:16:08 root@slave1 ~]#systemctl start mysqld
[12:16:35 root@slave1 ~]#vim all.sql
CHANGE MASTER TO
master_host='192.168.10.81',
master_user='slave',
master_password='123456',
master_port=3306,
MASTER_LOG_FILE='master-bin.000003', MASTER_LOG_POS=156;
[12:24:44 root@slave1 ~]#mysql
mysql> set sql_log_bin=0; #先关闭二进制日志
mysql> source /root/all.sql
mysql> flush PRIVILEGES; #备份恢复完成后权限得手动生效
mysql> show master logs; #记录二进制日志,给第三个节点用
mysql> set sql_log_bin=1; #开启二进制日志
mysql> start slave;
#在第三个节点slave上实现
[12:18:55 root@slave2 ~]#vim /etc/my.cnf.d/mysql-server.cnf
[mysqld]
server-id=83
read-only
[12:19:37 root@slave2 ~]#systemctl enable --now mysqld
[12:20:04 root@slave2 ~]#vim all.sql
CHANGE MASTER TO
master_host='192.168.10.82',
master_user='slave',
master_password='123456',
master_port=3306,
MASTER_LOG_FILE='slave1-bin.000002', MASTER_LOG_POS=156;
[12:26:12 root@slave2 ~]#mysql -e 'start slave'
[12:26:27 root@slave2 ~]#mysql -e 'show slave status\G'
6.1.5 主主复制
主主复制:两个节点,都可以更新数据,并且互为主从
容易产生的问题:数据不一致;因此慎用
考虑要点:自动增长id
配置一个节点使用奇数id
auto_increment_offset=1 #开始点
auto_increment_increment=2 #增长幅度
另一个节点使用偶数id
auto_increment_offset=2
auto_increment_increment=2
主主复制的配置步骤:
(1) 各节点使用一个惟一server_id
(2) 都启动binary log和relay log
(3) 创建拥有复制权限的用户账号
(4) 定义自动增长id字段的数值范围各为奇偶
(5) 均把对方指定为主节点,并启动复制线程
6.1.6 半同步复制
默认情况下,MySQL的复制功能是异步的,异步复制可以提供最佳的性能,主库把binlog日志发送给从库即结束,并不验证从库是否接收完毕。这意味着当主服务器或从服务器端发生故障时,有可能从服务器没有接收到主服务器发送过来的binlog日志,这就会造成主服务器和从服务器的数据不一致,甚至在恢复时造成数据的丢失
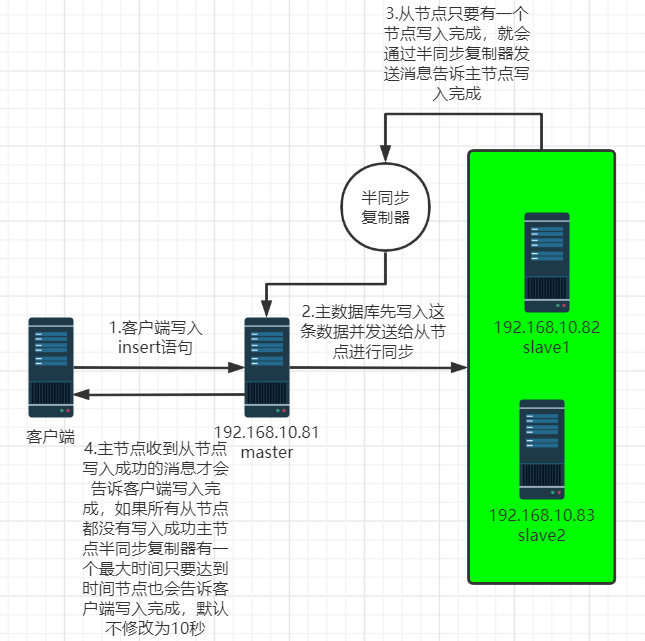
半同步复制实现:
官方文档:
https://dev.mysql.com/doc/refman/8.0/en/replication-semisync.html
https://dev.mysql.com/doc/refman/5.7/en/replication-semisync.html
https://mariadb.com/kb/en/library/semisynchronous-replication/
范例: CentOS8 在MySQL8.0 实现半同步复制
#查看插件文件
[12:31:41 root@master ~]#rpm -ql mysql-server | grep semisync
/usr/lib64/mysql/plugin/semisync_master.so
/usr/lib64/mysql/plugin/semisync_slave.so
#master服务器配置
[14:03:27 root@master ~]#vim /etc/my.cnf.d/mysql-server.cnf
rpl_semi_sync_master_enabled=ON #修改此行,需要先安装semisync_master.so插件后,再重启,否则无法启动
rpl_semi_sync_master_timeout=3000 #设置3s内无法同步,也将返回成功信息给客户端
#slave1服务器配置
[12:31:51 root@slave1 ~]#vim /etc/my.cnf.d/mysql-server.cnf
rpl_semi_sync_slave_enable=ON #修改此行,需要先安装semisync_slave.so插件后,再重启,否则无法启动
#slave2服务器配置
[14:10:57 root@slave2 ~]#vim /etc/my.cnf.d/mysql-server.cnf
rpl_semi_sync_slave_enabled=ON
#主服务器配置:
mysql> install plugin rpl_semi_sync_master soname 'semisync_master.so';
mysql>UNINSTALL PLUGIN rpl_semi_sync_master ; #卸载
mysql> show plugins; #查看插件
mysql> set global rpl_semi_sync_master_enabled=1; #临时修改变量
mysql> set global rpl_semi_sync_master_timeout = 3000; #超时长1s,默认值为10s
mysql> show global variables like '%semi%';
+-------------------------------------------+------------+
| Variable_name | Value |
+-------------------------------------------+------------+
| rpl_semi_sync_master_enabled | ON |
| rpl_semi_sync_master_timeout | 3000 |
| rpl_semi_sync_master_trace_level | 32 |
| rpl_semi_sync_master_wait_for_slave_count | 1 |
| rpl_semi_sync_master_wait_no_slave | ON |
| rpl_semi_sync_master_wait_point | AFTER_SYNC |
+-------------------------------------------+------------+
mysql> show global status like '%semi%';
+--------------------------------------------+-------+
| Variable_name | Value |
+--------------------------------------------+-------+
| Rpl_semi_sync_master_clients | 2 | #这个客户端个数需要配置从服务器后查看
| Rpl_semi_sync_master_net_avg_wait_time | 0 |
| Rpl_semi_sync_master_net_wait_time | 0 |
| Rpl_semi_sync_master_net_waits | 0 |
| Rpl_semi_sync_master_no_times | 0 |
| Rpl_semi_sync_master_no_tx | 0 |
| Rpl_semi_sync_master_status | ON |
| Rpl_semi_sync_master_timefunc_failures | 0 |
| Rpl_semi_sync_master_tx_avg_wait_time | 0 |
| Rpl_semi_sync_master_tx_wait_time | 0 |
| Rpl_semi_sync_master_tx_waits | 0 |
| Rpl_semi_sync_master_wait_pos_backtraverse | 0 |
| Rpl_semi_sync_master_wait_sessions | 0 |
| Rpl_semi_sync_master_yes_tx | 0 |
+--------------------------------------------+-------+
#从服务器配置:
mysql> install plugin rpl_semi_sync_slave soname 'semisync_slave.so';
mysql> set global rpl_semi_sync_slave_enabled=1;
mysql> show global variables like '%semi%';
+---------------------------------+-------+
| Variable_name | Value |
+---------------------------------+-------+
| rpl_semi_sync_slave_enabled | ON |
| rpl_semi_sync_slave_trace_level | 32 |
+---------------------------------+-------+
#注意:如果已经实现主从复制,需要stop slave;start slave;
mysql> stop slave;
mysql> start slave;
mysql> show global status like '%semi%';
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| Rpl_semi_sync_slave_status | ON |
+----------------------------+-------+
范例:CentOS 8 在Mariadb-10.3.11上实现 实现半同步复制
在MariaDB 10.3.3和更高版本中,半同步复制不由插件提供直接集成到mariadb系统中无需安装直接使用。其他版本还需要手动加载。
#先自行实现主从同步
#在master实现,启用半同步功能
[mysqld]
server-id=81
log-bin
plugin-load-add = semisync_master #加载插件,
rpl_semi_sync_master_enabled=ON
rpl_semi_sync_master_timeout=3000
[14:45:09 root@master ~]#systemctl enable --now mariadb.service
MariaDB [(none)]> show global variables like '%semi%';
+---------------------------------------+--------------+
| Variable_name | Value |
+---------------------------------------+--------------+
| rpl_semi_sync_master_enabled | ON |
| rpl_semi_sync_master_timeout | 3000 |
| rpl_semi_sync_master_trace_level | 32 |
| rpl_semi_sync_master_wait_no_slave | ON |
| rpl_semi_sync_master_wait_point | AFTER_COMMIT |
| rpl_semi_sync_slave_delay_master | OFF |
| rpl_semi_sync_slave_enabled | OFF |
| rpl_semi_sync_slave_kill_conn_timeout | 5 |
| rpl_semi_sync_slave_trace_level | 32 |
+---------------------------------------+--------------+
9 rows in set (0.001 sec)
MariaDB [(none)]> show global status like '%semi%';
+--------------------------------------------+-------+
| Variable_name | Value |
+--------------------------------------------+-------+
| Rpl_semi_sync_master_clients | 0 |
| Rpl_semi_sync_master_get_ack | 0 |
| Rpl_semi_sync_master_net_avg_wait_time | 0 |
| Rpl_semi_sync_master_net_wait_time | 0 |
| Rpl_semi_sync_master_net_waits | 0 |
| Rpl_semi_sync_master_no_times | 0 |
| Rpl_semi_sync_master_no_tx | 0 |
| Rpl_semi_sync_master_request_ack | 0 |
| Rpl_semi_sync_master_status | ON |
| Rpl_semi_sync_master_timefunc_failures | 0 |
| Rpl_semi_sync_master_tx_avg_wait_time | 0 |
| Rpl_semi_sync_master_tx_wait_time | 0 |
| Rpl_semi_sync_master_tx_waits | 0 |
| Rpl_semi_sync_master_wait_pos_backtraverse | 0 |
| Rpl_semi_sync_master_wait_sessions | 0 |
| Rpl_semi_sync_master_yes_tx | 0 |
| Rpl_semi_sync_slave_send_ack | 0 |
| Rpl_semi_sync_slave_status | OFF |
+--------------------------------------------+-------+
#在其它所有slave节点上都实现,启用半同步功能
[mysqld]
server-id=82
log-bin
read-only
plugin_load_add = semisync_slave
rpl_semi_sync_slave_enabled=ON
[14:58:06 root@slave2 ~]#systemctl enable --now mariadb.service
MariaDB [(none)]> show global variables like '%semi%';
+---------------------------------------+--------------+
| Variable_name | Value |
+---------------------------------------+--------------+
| rpl_semi_sync_master_enabled | OFF |
| rpl_semi_sync_master_timeout | 10000 |
| rpl_semi_sync_master_trace_level | 32 |
| rpl_semi_sync_master_wait_no_slave | ON |
| rpl_semi_sync_master_wait_point | AFTER_COMMIT |
| rpl_semi_sync_slave_delay_master | OFF |
| rpl_semi_sync_slave_enabled | ON |
| rpl_semi_sync_slave_kill_conn_timeout | 5 |
| rpl_semi_sync_slave_trace_level | 32 |
+---------------------------------------+--------------+
MariaDB [(none)]> show global status like '%semi%';
+--------------------------------------------+-------+
| Variable_name | Value |
+--------------------------------------------+-------+
| Rpl_semi_sync_master_clients | 0 |
| Rpl_semi_sync_master_get_ack | 0 |
| Rpl_semi_sync_master_net_avg_wait_time | 0 |
| Rpl_semi_sync_master_net_wait_time | 0 |
| Rpl_semi_sync_master_net_waits | 0 |
| Rpl_semi_sync_master_no_times | 0 |
| Rpl_semi_sync_master_no_tx | 0 |
| Rpl_semi_sync_master_request_ack | 0 |
| Rpl_semi_sync_master_status | OFF |
| Rpl_semi_sync_master_timefunc_failures | 0 |
| Rpl_semi_sync_master_tx_avg_wait_time | 0 |
| Rpl_semi_sync_master_tx_wait_time | 0 |
| Rpl_semi_sync_master_tx_waits | 0 |
| Rpl_semi_sync_master_wait_pos_backtraverse | 0 |
| Rpl_semi_sync_master_wait_sessions | 0 |
| Rpl_semi_sync_master_yes_tx | 0 |
| Rpl_semi_sync_slave_send_ack | 1 |
| Rpl_semi_sync_slave_status | ON |
+--------------------------------------------+-------+
6.1.7 复制过滤器
让从节点仅复制指定的数据库,或指定数据库的指定表
复制过滤器两种实现方式:
(1) 服务器选项:主服务器仅向二进制日志中记录与特定数据库相关的事件
缺点:基于二进制还原将无法实现;不建议使用
优点: 只需要在主节点配置一次即可
注意:此项和 binlog_format相关
参看:https://mariadb.com/kb/en/library/mysqld-options/#-binlog-ignore-db
vim /etc/my.cnf
binlog-do-db=db1 #数据库白名单列表,不支持同时指定多个值,如果想实现多个数据库需多行实现
binlog-do-db=db2
binlog-ignore-db= #数据库黑名单列表
(2) 从服务器SQL_THREAD在relay log中的事件时,仅读取与特定数据库(特定表)相关的事件并应用于本地
缺点:会造成网络及磁盘IO浪费,在所有从节点都要配置
优点: 不影响二进制备份还原
从服务器上的复制过滤器相关变量
replicate_do_db="db1,db2,db3" #指定复制库的白名单,变量可以指定逗号分隔的多个值,选项不支持多值,只能分别写多行实现
replicate_ignore_db= #指定复制库黑名单
replicate_do_table= #指定复制表的白名单
replicate_ignore_table= #指定复制表的黑名单
replicate_wild_do_table= foo%.bar% #支持通配符
replicate_wild_ignore_table=
注意:跨库的更新将无法同步
范例:
[mysqld]
replicate_do_db=db1
replicate_do_db=db2
replicate_do_db=db3
范例: 通过二进制日志服务器选项实现过滤器
[mysqld]
server-id=8
log-bin
binlog-do-db=db1
binlog-do-db=db2
binlog-do-db=hellodb
范例: 通过系统变量实现过滤器
MariaDB [(none)]> set global replicate_do_db='db1,hellodb';
Query OK, 0 rows affected (0.000 sec)
MariaDB [(none)]> select @@replicate_do_db;
+-------------------+
| @@replicate_do_db |
+-------------------+
| db1,hellodb |
+-------------------+
1 row in set (0.000 sec)
MariaDB [(none)]> start slave;
6.1.8 主从复制加密
在默认的主从复制过程或远程连接到MySQL/MariaDB所有的链接通信中的数据都是明文的,外网里访问数据或则复制,存在安全隐患。
通过SSL/TLS加密的方式进行复制的方法,来进一步提高数据的安全性
官网文档:https://mariadb.com/kb/en/library/replication-with-secure-connections/
实现MySQL复制加密
- 生成 CA 及 master 和 slave 的证书
[15:28:33 root@master ~]#mkdir /etc/my.cnf.d/ssl/
[15:29:16 root@master ~]#cd /etc/my.cnf.d/ssl/
[15:29:26 root@master ssl]#openssl genrsa 2048 > cakey.pem
[15:29:45 root@master ssl]#openssl req -new -x509 -key cakey.pem --out cacert.pem
-days 3650
[15:33:23 root@master ssl]#openssl req -newkey rsa:2048 -nodes -keyout master.key >master.csr
[15:34:25 root@master ssl]#ls
cacert.pem cakey.pem master.csr master.key
[15:35:48 root@master ssl]#openssl x509 -req -in master.csr -CA cacert.pem -CAkey cakey.pem --set_serial 01 >master.crt
[15:36:41 root@master ssl]#ls
cacert.pem cakey.pem master.crt master.csr master.key
[15:36:46 root@master ssl]#openssl req -newkey rsa:2048 -nodes -keyout slave.key >slave.csr
[15:38:16 root@master ssl]#openssl x509 -req -in slave.csr -CA cacert.pem -CAkey cakey.pem --set_serial 02 >slave.crt
[15:38:46 root@master ssl]#ls
cacert.pem master.crt master.key slave.csr
cakey.pem master.csr slave.crt slave.key
[15:39:06 root@master ssl]#chown -R mysql: /etc/my.cnf.d/ssl
#如果上面没修改权限,会出现ssl无法启动和下面日志错误
MariaDB [(none)]> show variables like '%ssl%';
+---------------------+----------------------------------+
| Variable_name | Value |
+---------------------+----------------------------------+
| have_openssl | YES |
| have_ssl | DISABLED #无法启用,正常启用为YES |
| ssl_ca | /etc/my.cnf.d/ssl/cacert.pem |
| ssl_capath | |
| ssl_cert | /etc/my.cnf.d/ssl/master.crt |
| ssl_cipher | |
| ssl_crl | |
| ssl_crlpath | |
| ssl_key | /etc/my.cnf.d/ssl/master.key |
| version_ssl_library | OpenSSL 1.1.1c FIPS 28 May 2019 |
+---------------------+----------------------------------+
10 rows in set (0.001 sec)
[root@centos8 ~]#cat /var/log/mariadb/mariadb.log
2020-10-12 17:55:35 0 [Warning] Failed to setup SSL
2020-10-12 17:55:35 0 [Warning] SSL error: Unable to get private key
2020-10-12 17:55:35 0 [Warning] SSL error: error:0200100D:system
library:fopen:Permission denied
2020-10-12 17:55:35 0 [Warning] SSL error: error:20074002:BIO
routines:file_ctrl:system lib
2020-10-12 17:55:35 0 [Warning] SSL error: error:140B0002:SSL
routines:SSL_CTX_use_PrivateKey_file:system lib
- 主服务器开启 SSL,配置证书和私钥路径
[mysqld]
ssl
ssl-ca=/etc/my.cnf.d/ssl/cacert.pem
ssl-cert=/etc/my.cnf.d/ssl/master.crt
ssl-key=/etc/my.cnf.d/ssl/master.key
[15:41:16 root@master ~]#systemctl restart mariadb.service
MariaDB [(none)]> show variables like '%ssl%';
+---------------------+----------------------------------+
| Variable_name | Value |
+---------------------+----------------------------------+
| have_openssl | YES |
| have_ssl | YES |
| ssl_ca | /etc/my.cnf.d/ssl/cacert.pem |
| ssl_capath | |
| ssl_cert | /etc/my.cnf.d/ssl/master.crt |
| ssl_cipher | |
| ssl_crl | |
| ssl_crlpath | |
| ssl_key | /etc/my.cnf.d/ssl/master.key |
| version_ssl_library | OpenSSL 1.1.1g FIPS 21 Apr 2020 |
+---------------------+----------------------------------+
10 rows in set (0.001 sec)
#如需要客户端工具连接此用户也必须指定密钥
[mysql]
ssl-ca=/etc/my.cnf.d/ssl/cacert.pem
ssl-cert=/etc/my.cnf.d/ssl/master.crt
ssl-key=/etc/my.cnf.d/ssl/master.key
- 创建一个要求必须使用 SSL 连接的复制账号
#ssl账户
MariaDB [(none)]> create user 'slave'@'192.168.10.%' identified by '123456' require ssl;
MariaDB [(none)]> grant replication slave on *.* to slave@'192.168.10.%';
[15:55:28 root@master ~]#scp -r /etc/my.cnf.d/ssl 192.168.10.82:/etc/my.cnf.d/
[15:55:28 root@master ~]#scp -r /etc/my.cnf.d/ssl 192.168.10.83:/etc/my.cnf.d/
- 从服务器slave上使用CHANGER MASTER TO 命令时指明ssl相关选项
[15:52:26 root@slave1 ~]#mysql -uslave -p123456 -h192.168.10.81
ERROR 1045 (28000): Access denied for user 'slave'@'192.168.10.82' (using password: YES)
[15:57:15 root@slave1 ~]#chown -R mysql: /etc/my.cnf.d/ssl
#可选方式1
[mysqld]
ssl
ssl-ca=/etc/my.cnf.d/ssl/cacert.pem
ssl-cert=/etc/my.cnf.d/ssl/slave.crt
ssl-key=/etc/my.cnf.d/ssl/slave.key
MariaDB [(none)]>CHANGE MASTER TO
MASTER_HOST='192.168.10.81',
MASTER_USER='slave',
MASTER_PASSWORD='123456',
MASTER_LOG_FILE='mariadb-bin.000005',
MASTER_LOG_POS=389,
MASTER_SSL=1;
Query OK, 0 rows affected (0.002 sec)
MariaDB [(none)]> start slave;
#可选方式2
#需修改配置文件,执行下面命令即可
MariaDB [(none)]>CHANGE MASTER TO
MASTER_HOST='192.168.10.81',
MASTER_USER='slave',
MASTER_PASSWORD='123456',
MASTER_LOG_FILE='mariadb-bin.000005',
MASTER_LOG_POS=389,
MASTER_SSL=1,
MASTER_SSL_CA = '/etc/my.cnf.d/ssl/cacert.pem',
MASTER_SSL_CERT = '/etc/my.cnf.d/ssl/slave.crt',
MASTER_SSL_KEY = '/etc/my.cnf.d/ssl/slave.key';
#启动后查看三个参数是否为yes
MariaDB [(none)]> show slave status\G
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Master_SSL_Allowed: Yes
6.1.9 GTID复制
GTID复制:(Global Transaction ID 全局事务标识符) MySQL 5.6 版本开始支持,GTID复制不像传统的复制方式(异步复制、半同步复制)需要找到binlog文件名和POS点,只需知道master的IP、端口、账号、密码即可。开启GTID后,执行change master to master_auto_postion=1即可,它会自动寻找到相应的位置开始同步
GTID 架构
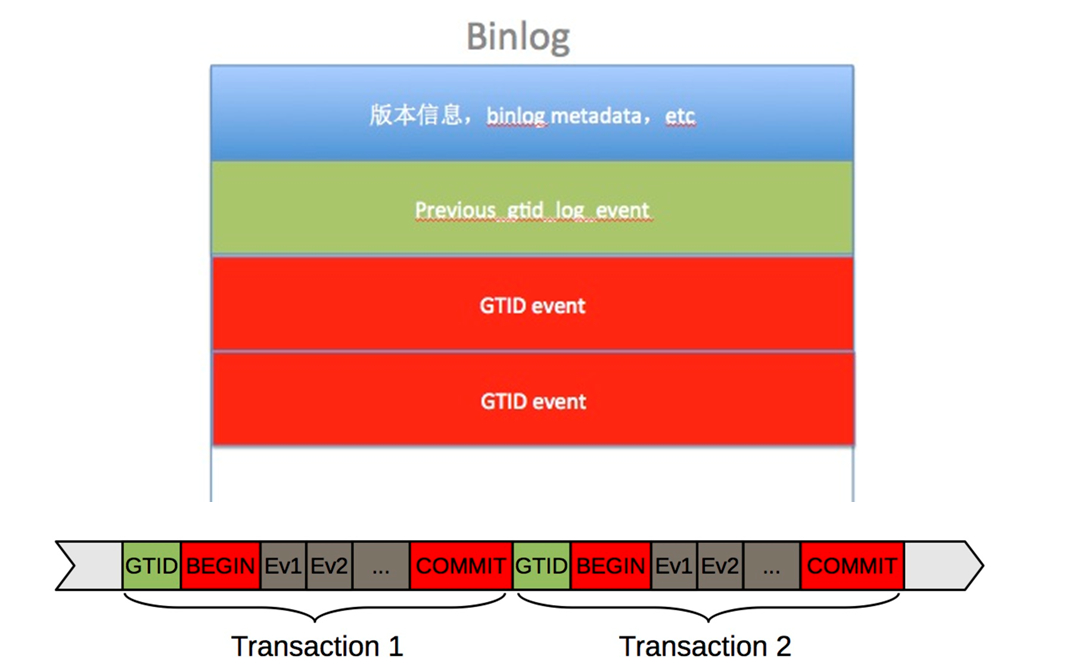
GTID = server_uuid:transaction_id,在一组复制中,全局唯一
server_uuid 来源于 /var/lib/mysql/auto.cnf
GTID服务器相关选项
gtid_mode #gtid模式
enforce_gtid_consistency #保证GTID安全的参数
GTID配置范例
- 主服务器
vim /etc/my.cnf
server-id=1
log-bin=mysql-bin #可选
gtid_mode=ON
enforce_gtid_consistency
mysql> grant replication slave on *.* to 'repluser'@'10.0.0.%' identified by
'magedu';
- 从服务器
vim /etc/my.cnf
server-id=2
gtid_mode=ON
enforce_gtid_consistency
mysql>CHANGE MASTER TO MASTER_HOST='10.0.0.100',
MASTER_USER='repluser',
MASTER_PASSWORD='magedu',
MASTER_PORT=3306,
MASTER_AUTO_POSITION=1;
mysql>start slave;
6.1.10 复制的监控和维护
6.1.10.1 清理日志
PURGE { BINARY | MASTER } LOGS { TO 'log_name' | BEFORE datetime_expr }
RESET MASTER TO # #mysql 不支持
RESET SLAVE [ALL]
6.1.10.2 复制监控
SHOW MASTER STATUS #当前正在使用的二进制日志
SHOW BINARY LOGS #当前主机中所有的二进制日志
SHOW BINLOG EVENTS #显示二进制所有日志中每个事务
SHOW SLAVE STATUS #从节点信息查看
SHOW PROCESSLIST #查看当前主机中已经连接的线程
6.1.10.3 从服务器是否落后于主服务
MariaDB [(none)]> show slave status\G
Seconds_Behind_Master:0
6.1.10.4 如何确定主从节点数据是否一致
percona-toolkit工具
1.检查数据库是否一致
pt-table-checksum --no-check-binlog-format h=127.0.0.1,u=pt,P=3306
参数说明:
--nocheck-replication-filters:不检查复制的过滤规则,比如replicate-ignore-db、replicate-wild-do-table。
--no-check-binlog-format:不检查复制的binlog模式,如果binlog模式是row模式,需要启用该参数。
--create-replicate-table:第一次进行checksum需要启用该参数,会进行checksum表的创建,用于存放结果。
--replicate=test.checksums:存放checksum结果的表。
--databases:表示要检查的库。
--tables(-t):表示要检查的表。
--replicate-check-only:表示只显示不同步的表。
--recursion-method:正常情况下工具会自动识别从库,如果识别失败,可以用该参数 指定查找slave的方法,参数有四种,分别是processlist、hosts、dsn=DSN、no四种,用来决定查找slave的方式是通过show processlist、show slave hosts还是通过dsn=DSN的方式。
结果说明:
TS ERRORS DIFFS ROWS DIFF_ROWS CHUNKS SKIPPED TIME TABLE09-04T22:29:52 0 0 1 0 1 0 0.029 test.dsns
TS:完成检查的时间
ERRORS:错误和告警的数量。
DIFFS:是否一致,0代表一致,1代表不一致。
ROWS:表的行数
DIFF_ROWS:CHUNKS:划分的块的数目
SKIPPED:跳过的块的数目
TIME:执行时长
TABLE:表名
2.修复或查看那个语句有问题
#当有多个DSN时,如果指定了--sync-to-master,那么所有的主机均为从库。否则报错:
Can't determine master of D=test,h=…..,p=...,t=t1,u=syncuser at /usr/bin/pt-table-sync line 10020.
#在主节点执行,指定了--sync-to-master本机就是主,所有地址当中都是从写从的信息--print只是打印什么语句可以修复
[17:44:02 root@master ~]# pt-table-sync --sync-to-master --databases=hellodb h=192.168.10.82,u=pt,P=3306 h=192.168.10.83,u=pt,P=3306 --print
参数说明:
--execute: 指定工具执行变更操作,使表数据达成一致。
--print: 打印出工具需要执行哪些语句来变更表。
6.1.10.5 数据不一致如何修复
删除从数据库,重新复制
6.1.11 复制的问题和解决方案
6.1.11.1 数据损坏或丢失
- Master:MHA + semisync replication
- Slave: 重新复制
6.1.11.2 不惟一的 server id
- 重新复制
6.1.11.3 复制延迟
- 需要额外的监控工具的辅助
- 一从多主:mariadb10 版后支持
- 多线程复制:对多个数据库复制
6.1.11.4 MySQL 主从数据不一致
造成主从不一致的原因
- 主库binlog格式为Statement,同步到从库执行后可能造成主从不一致。
- 主库执行更改前有执行set sql_log_bin=0,会使主库不记录binlog,从库也无法变更这部分数据。
- 从节点未设置只读,误操作写入数据
- 主库或从库意外宕机,宕机可能会造成binlog或者relaylog文件出现损坏,导致主从不一致
- 主从实例版本不一致,特别是高版本是主,低版本为从的情况下,主数据库上面支持的功能,从数据库上面可能不支持该功能
- MySQL自身bug导致
主从不一致修复方法
-
将从库重新实现
- 虽然这也是一种解决方法,但是这个方案恢复时间比较慢,而且有时候从库也是承担一部分的查询操作的,不能贸然重建。
-
使用percona-toolkit工具辅助
-
PT工具包中包含pt-table-checksum和pt-table-sync两个工具,主要用于检测主从是否一致以及修复数据不一致情况。这种方案优点是修复速度快,不需要停止主从辅助,缺点是需要知识积累,需要时间去学习,去测试,特别是在生产环境,还是要小心使用
-
关于使用方法,可以参考下面链接:https://www.cnblogs.com/feiren/p/7777218.html
-
手动重建不一致的表
-
在从库发现某几张表与主库数据不一致,而这几张表数据量也比较大,手工比对数据不现实,并且重做整个库也比较慢,这个时候可以只重做这几张表来修复主从不一致这种方案缺点是在执行导入期间需要暂时停止从库复制,不过也是可以接受的
范例:A,B,C这三张表主从数据不一致
1. 从库停止Slave复制
mysql>stop slave;
2. 在主库上dump这三张表,并记录下同步的binlog和POS点
mysqldump -uroot -pmagedu -q --single-transaction --master-data=2 testdb A B
C >/backup/A_B_C.sql
3. 查看A_B_C.sql文件,找出记录的binlog和POS点
head A_B_C.sql
例如:MASTERLOGFILE='mysql-bin.888888', MASTERLOGPOS=666666;
#以下指令是为了保障其他表的数据不丢失,一直同步直到那个点结束,A,B,C表的数据在之前的备份已
经生成了一份快照,只需要导入进入,然后开启同步即可
4. 把A_B_C.sql拷贝到Slave机器上,并做指向新位置
mysql>start slave until MASTERLOGFILE='mysql-bin.888888',
MASTERLOGPOS=666666;
5. 在Slave机器上导入A_B_C.sql
mysql -uroot -pmagedu testdb
mysql>set sql_log_bin=0;
mysql>source /backup/A_B_C.sql
mysql>set sql_log_bin=1;
6. 导入完毕后,从库开启同步即可。
mysql>start slave;
如何避免主从不一致
- 主库binlog采用ROW格式
- 主从实例数据库版本保持一致
- 主库做好账号权限把控,不可以执行set sql_log_bin=0
- 从库开启只读,不允许人为写入
- 定期进行主从一致性检验
6.2 MySQL 中间件代理服务器
6.2.1 关系型数据库和 NoSQL 数据库
数据库主要分为两大类:关系型数据库与 NoSQL 数据库。
关系型数据库,是建立在关系模型基础上的数据库,其借助于集合代数等数学概念和方法来处理数据库中的数据。主流的 MySQL、Oracle、MS SQL Server 和 DB2 都属于这类传统数据库。
NoSQL 数据库,全称为 Not Only SQL,意思就是适用关系型数据库的时候就使用关系型数据库,不适用的时候也没有必要非使用关系型数据库不可,可以考虑使用更加合适的数据存储。主要分为临时性键值存储(memcached、Redis)、永久性键值存储(ROMA、Redis)、面向文档的数据库(MongoDB、CouchDB)、面向列的数据库(Cassandra、HBase),每种 NoSQL 都有其特有的使用场景及优点。
Oracle,mysql 等传统的关系数据库非常成熟并且已大规模商用,为什么还要用 NoSQL 数据库呢?主要是由于随着互联网发展,数据量越来越大,对性能要求越来越高,传统数据库存在着先天性的缺陷,即单机(单库)性能瓶颈,并且扩展困难。这样既有单机单库瓶颈,却又扩展困难,自然无法满足日益增长的海量数据存储及其性能要求,所以才会出现了各种不同的 NoSQL 产品,NoSQL 根本性的优势在于在云计算时代,简单、易于大规模分布式扩展,并且读写性能非常高
RDBMS和NOSQL的特点及优缺点:
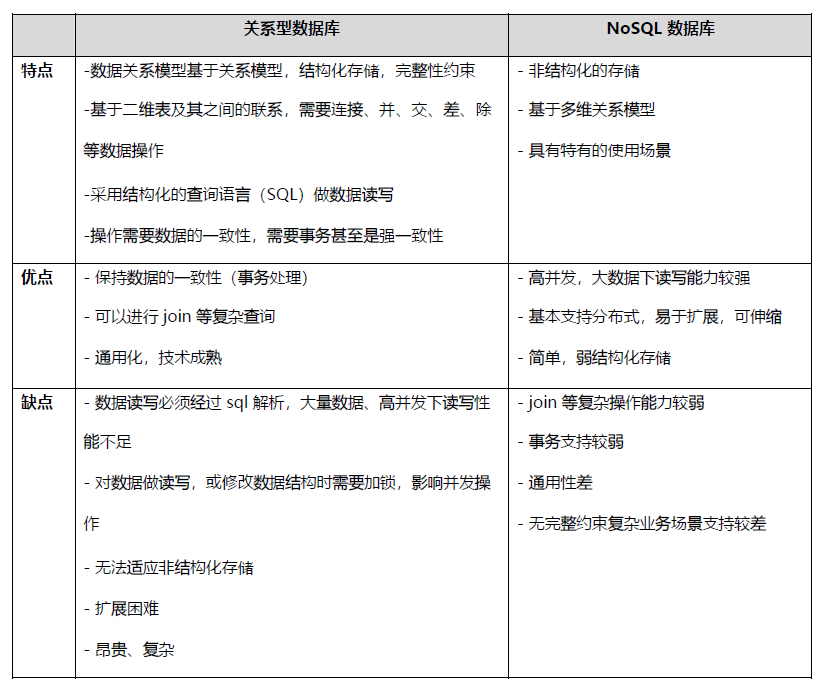
6.2.2 数据切分
简单来说,就是指通过某种特定的条件,将我们存放在同一个数据库中的数据分散存放到多个数据库(主机) 上面,以达到分散单台设备负载的效果。
数据的切分(Sharding)根据其切分规则的类型,可以分为两种切分模式。
一种是按照不同的表(或者 Schema)来切分到不同的数据库(主机)之上,这种切可以称之为数据的垂直(纵向)切分;另外一种则是根据 表中的数据的逻辑关系,将同一个表中的数据按照某种条件拆分到多台数据库(主机)上面,这种切分称之为数据的水平(横向)切分。
垂直切分的最大特点就是规则简单,实施也更为方便,尤其适合各业务之间的耦合度非常低,相互影响很小, 业务逻辑非常清晰的系统。在这种系统中,可以很容易做到将不同业务模块所使用的表分拆到不同的数据库中。 根据不同的表来进行拆分,对应用程序的影响也更小,拆分规则也会比较简单清晰。
水平切分于垂直切分相比,相对来说稍微复杂一些。因为要将同一个表中的不同数据拆分到不同的数据库中, 对于应用程序来说,拆分规则本身就较根据表名来拆分更为复杂,后期的数据维护也会更为复杂一些。
6.2.2.1 垂直切分
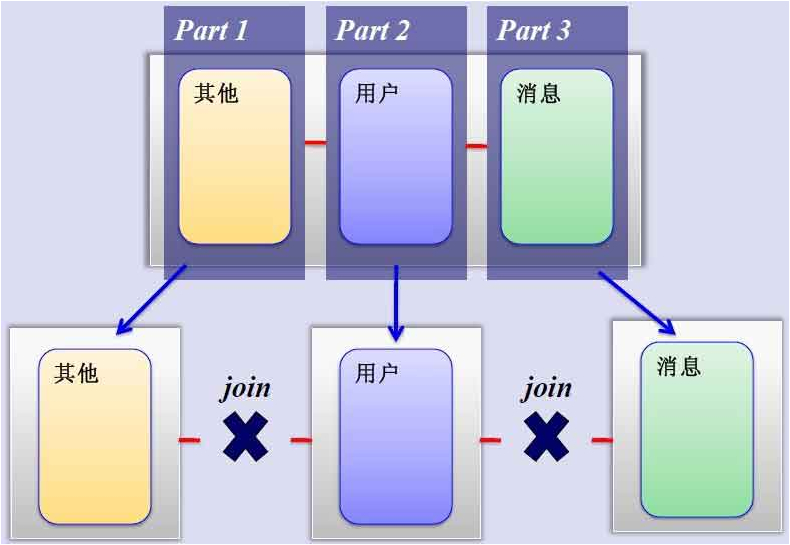
一个数据库由很多表的构成,每个表对应着不同的业务,垂直切分是指按照业务将表进行分类,分布到不同的数据库上面,这样也就将数据或者说压力分担到不同的库上面,如下图:
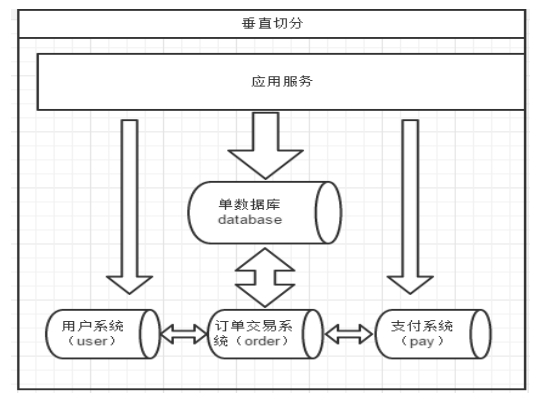
系统被切分成了,用户,订单交易,支付几个模块。 一个架构设计较好的应用系统,其总体功能肯定是由很多个功能模块所组成的,而每一个功能模块所需要的数据对应到数据库中就是一个或者多个表。而在架构设计中,各个功能模块相互之间的交互点越统一越少,系统的耦合度就越低,系统各个模块的维护性以及扩展性也就越好。这样的系统,实现数据的垂直切分也就越容易。
但是往往系统之有些表难以做到完全独立,存在着跨库 join 的情况,对于这类表,就需要去做平衡,是数据库让步业务,共用一个数据源,还是分成多个库,业务之间通过接口来做调用。在系统初期,数据量比较 少,或者资源有限的情况下,会选择共用数据源,但是当数据发展到了一定的规模,负载很大的情况,就需要必须去做分割。
一般来讲业务存在着复杂 join 的场景是难以切分的,往往业务独立的易于切分。如何切分,切分到何种程度是考验技术架构的一个难题。
垂直切分的优缺点:
优点:
- 拆分后业务清晰,拆分规则明确
- 系统之间整合或扩展容易
- 数据维护简单
缺点:
- 部分业务表无法 join,只能通过接口方式解决,提高了系统复杂度
- 受每种业务不同的限制存在单库性能瓶颈,不易数据扩展跟性能提高
- 事务处理复杂
由于垂直切分是按照业务的分类将表分散到不同的库,所以有些业务表会过于庞大,存在单库读写与存储瓶颈,所以就需要水平拆分来做解决。
6.2.2.2 水平切分
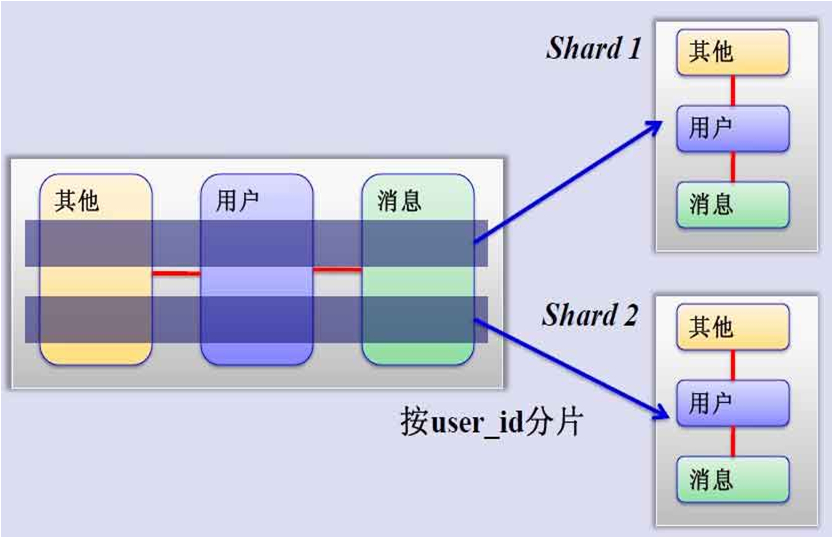
对应shard中查询相关数据
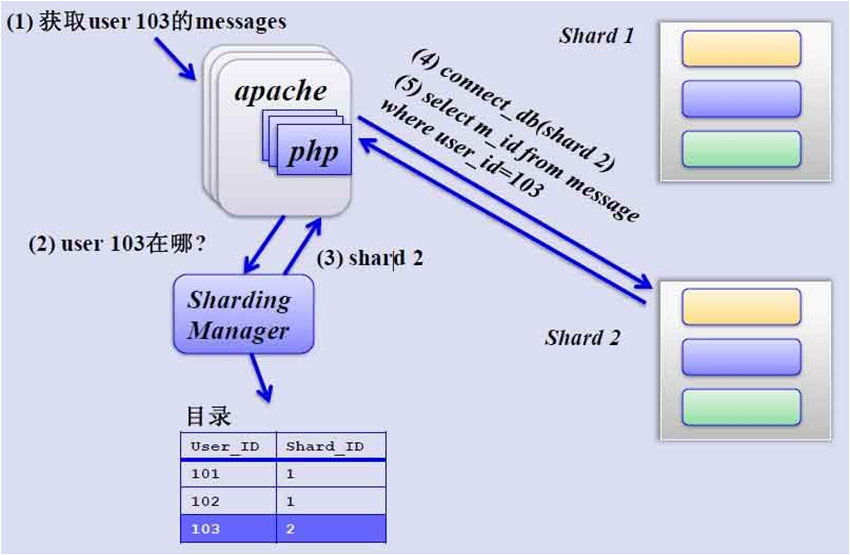
相对于垂直拆分,水平拆分不是将表做分类,而是按照某个字段的某种规则来分散到多个库之中,每个表中包含一部分数据。简单来说,我们可以将数据的水平切分理解为是按照数据行的切分,就是将表中的某些行切分 到一个数据库,而另外的某些行又切分到其他的数据库中,如图:
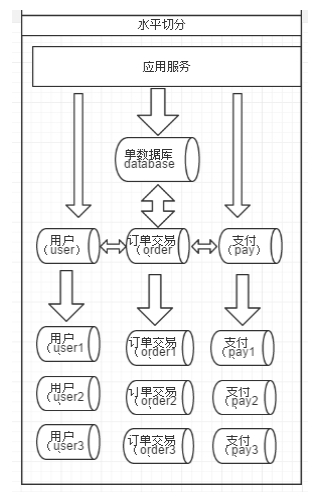
拆分数据就需要定义分片规则。关系型数据库是行列的二维模型,拆分的第一原则是找到拆分维度。比如: 从会员的角度来分析,商户订单交易类系统中查询会员某天某月某个订单,那么就需要按照会员结合日期来拆分, 不同的数据按照会员 ID 做分组,这样所有的数据查询 join 都会在单库内解决;如果从商户的角度来讲,要查询某个商家某天所有的订单数,就需要按照商户 ID 做拆分;但是如果系统既想按会员拆分,又想按商家数据,则会有 一定的困难。如何找到合适的分片规则需要综合考虑衡量。
几种典型的分片规则包括:
- 按照用户 ID 求模,将数据分散到不同的数据库,具有相同数据用户的数据都被分散到一个库中
- 按照日期,将不同月甚至日的数据分散到不同的库中
- 按照某个特定的字段求摸,或者根据特定范围段分散到不同的库中
如图,切分原则都是根据业务找到适合的切分规则分散到不同的库,下面用用户 ID 求模举例:
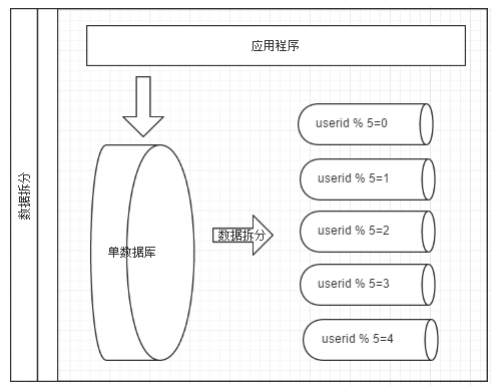
既然数据做了拆分有优点也就优缺点。
优点:
- 拆分规则抽象好,join 操作基本可以数据库做
- 不存在单库大数据,高并发的性能瓶颈
- 应用端改造较少
- 提高了系统的稳定性跟负载能力
缺点:
- 拆分规则难以抽象
- 分片事务一致性难以解决
- 数据多次扩展难度跟维护量极大
- 跨库 join 性能较差
前面讲了垂直切分跟水平切分的不同跟优缺点,会发现每种切分方式都有缺点,但共同特点缺点有:
- 引入分布式事务的问题
- 跨节点 Join 的问题
- 跨节点合并排序分页问题
- 多数据源管理问题
6.2.3 MySQL 中间件各种应用
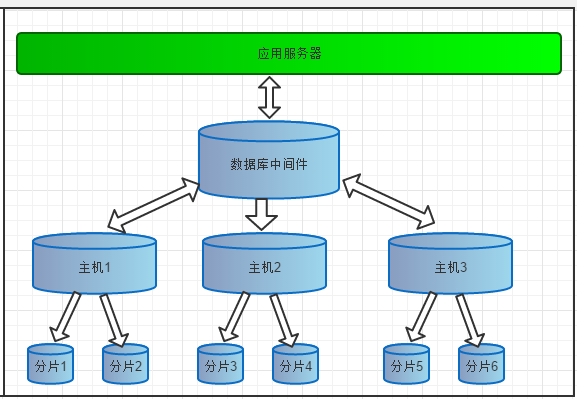
- mysql-proxy:Oracle,https://downloads.mysql.com/archives/proxy/
- Atlas:Qihoo,https://github.com/Qihoo360/Atlas/blob/master/README_ZH.md
- dbproxy:美团,https://github.com/Meituan-Dianping/DBProxy
- Cetus:网易乐得,https://github.com/Lede-Inc/cetus
- Amoeba:https://sourceforge.net/projects/amoeba/
- Cobar:阿里巴巴,Amoeba的升级版,https://github.com/alibaba/cobar
- Mycat:基于Cobar http://www.mycat.io/ (原网站)
- ProxySQL:https://proxysql.com/
6.2.4 Mycat
6.2.4.1 Mycat 介绍
在整个IT系统架构中,数据库是非常重要,通常又是访问压力较大的一个服务,除了在程序开发的本身做优化,如:SQL语句优化、代码优化,数据库的处理本身优化也是非常重要的。主从、热备、分表分库等都是系统发展迟早会遇到的技术问题问题。Mycat是一个广受好评的数据库中间件,已经在很多产品上进行使用了。
在整个IT系统架构中,数据库是非常重要,通常又是访问压力较大的一个服务,除了在程序开发的本身做优化,如:SQL语句优化、代码优化,数据库的处理本身优化也是非常重要的。主从、热备、分表分库等都是系统发展迟早会遇到的技术问题问题。Mycat是一个广受好评的数据库中间件,已经在很多产品上进行使用了。
Mycat发展到目前的版本,已经不是一个单纯的MySQL代理了,它的后端可以支持MySQL、SQLServer、Oracle、DB2、PostgreSQL等主流数据库,也支持MongoDB这种新型NoSQL方式的存储,未来还会支持更多类型的存储。而在最终用户看来,无论是那种存储方式,在MyCat里,都是一个传统的数据库表,支持标准的SQL语句进行数据的操作,这样一来,对前端业务系统来说,可以大幅降低开发难度,提升开发速度
Mycat 可以简单概括为
- 一个彻底开源的,面向企业应用开发的大数据库集群
- 支持事务、ACID、可以替代MySQL的加强版数据库
- 一个可以视为MySQL集群的企业级数据库,用来替代昂贵的Oracle集群
- 一个融合内存缓存技术、NoSQL技术、HDFS大数据的新型SQL Server
- 结合传统数据库和新型分布式数据仓库的新一代企业级数据库产品
- 一个新颖的数据库中间件产品
Mycat 官网:http://www.mycat.org.cn/
Mycat 关键特性
- 支持SQL92标准
- 遵守MySQL 原生协议,跨语言,跨平台,跨数据库的通用中间件代理
- 基于心跳的自动故障切换,支持读写分离,支持MySQL主从,以及galera cluster集群
- 支持Galera for MySQL集群,Percona Cluster或者MariaDB cluster
- 基于Nio实现,有效管理线程,高并发问题
- 支持数据的多片自动路由与聚合,支持sum,count,max等常用的聚合函数,支持跨库分页
- 支持单库内部任意join,支持跨库2表join,甚至基于caltlet的多表join
- 支持通过全局表,ER关系的分片策略,实现了高效的多表join查询
- 支持多租户方案
- 支持分布式事务(弱xa)
- 支持全局序列号,解决分布式下的主键生成问题
- 分片规则丰富,插件化开发,易于扩展
- 强大的web,命令行监控
- 支持前端作为mysq通用代理,后端JDBC方式支持Oracle、DB2、SQL Server 、 mongodb 、巨杉
- 支持密码加密
- 支持服务降级
- 支持IP白名单
- 支持SQL黑名单、sql注入攻击拦截
- 支持分表(1.6)
- 集群基于ZooKeeper管理,在线升级,扩容,智能优化,大数据处理(2.0开发版)
为什么要用MyCat
这里要先搞清楚Mycat和MySQL的区别(Mycat的核心作用)。我们可以把上层看作是对下层的抽象,例如操作系统是对各类计算机硬件的抽象。那么我们什么时候需要抽象?假如只有一种硬件的时候,我们需要开发一个操作系统吗?再比如一个项目只需要一个人完成的时候不需要leader,但是当需要几十人完成时,就应该有一个管理者,发挥沟通协调等作用,而这个管理者对于他的上层来说就是对项目组的抽象
同样的,当我们的应用只需要一台数据库服务器的时候我们并不需要Mycat,而如果你需要分库甚至分表,这时候应用要面对很多个数据库的时候,这个时候就需要对数据库层做一个抽象,来管理这些数据库,而最上面的应用只需要面对一个数据库层的抽象或者说数据库中间件就好了,这就是Mycat的核心作用。所以可以这样理解:数据库是对底层存储文件的抽象,而Mycat是对数据库的抽象
Mycat工作原理
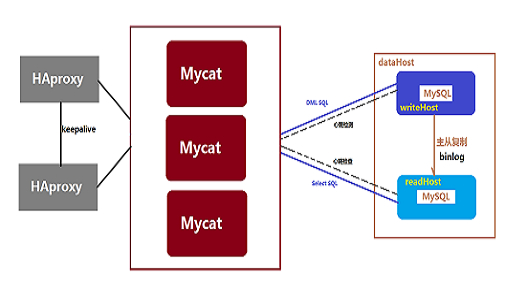
Mycat的原理中最重要的一个动词是"拦截",它拦截了用户发送过来的SQL语句,首先对SQL语句做了一些特定的分析:如分片分析、路由分析、读写分离分析、缓存分析等,然后将此SQL发往后端的真实数据库,并将返回的结果做适当的处理,最终再返回给用户
Mycat应用场景
Mycat适用的场景很丰富,以下是几个典型的应用场景
- 单纯的读写分离,此时配置最为简单,支持读写分离,主从切换
- 分表分库,对于超过1000万的表进行分片,最大支持1000亿的单表分片
- 多租户应用,每个应用一个库,但应用程序只连接Mycat,从而不改造程序本身,实现多租户化
- 报表系统,借助于Mycat的分表能力,处理大规模报表的统计
- 替代Hbase,分析大数据
- 作为海量数据实时查询的一种简单有效方案,比如100亿条频繁查询的记录需要在3秒内查询出来结果,除了基于主键的查询,还可能存在范围查询或其他属性查询,此时Mycat可能是最简单有效的选择
- Mycat长期路线图
- 强化分布式数据库中间件的方面的功能,使之具备丰富的插件、强大的数据库智能优化功能、全面的系统监控能力、以及方便的数据运维工具,实现在线数据扩容、迁移等高级功能
- 进一步挺进大数据计算领域,深度结合Spark Stream和Storm等分布式实时流引擎,能够完成快速的巨表关联、排序、分组聚合等 OLAP方向的能力,并集成一些热门常用的实时分析算法,让工程师以及DBA们更容易用Mycat实现一些高级数据分析处理功能
Mycat不适合的应用场景
- 设计使用Mycat时有非分片字段查询,请慎重使用Mycat,可以考虑放弃!
- 设计使用Mycat时有分页排序,请慎重使用Mycat,可以考虑放弃!
- 设计使用Mycat时如果要进行表JOIN操作,要确保两个表的关联字段具有相同的数据分布,否则请慎重使用Mycat,可以考虑放弃!
- 设计使用Mycat时如果有分布式事务,得先看是否得保证事务得强一致性,否则请慎重使用Mycat,可以考虑放弃!
MyCat的高可用性:
需要注意: 在生产环境中, Mycat节点最好使用双节点, 即双机热备环境, 防止Mycat这一层出现单点故障.可以使用的高可用集群方式有:
- Keepalived+Mycat+Mysql
- Keepalived+LVS+Mycat+Mysql
- Keepalived+Haproxy+Mycat+Mysql
6.2.4.2 Mycat 安装
下载安装JDK
[19:03:59 root@centos8 ~]#yum -y install java
#确认安装成功
[19:05:07 root@centos8 ~]#java -version
openjdk version "1.8.0_275"
OpenJDK Runtime Environment (build 1.8.0_275-b01)
OpenJDK 64-Bit Server VM (build 25.275-b01, mixed mode)
下载安装mycat
[19:07:42 root@centos8 ~]#wget http://dl.mycat.org.cn/1.6.7.4/Mycat-server-1.6.7.4-release/Mycat-server-1.6.7.4-release-20200105164103-linux.tar.gz
[19:08:04 root@centos8 ~]#mkdir /apps
[19:08:14 root@centos8 ~]#tar xvf Mycat-server-1.6.7.4-release-20200105164103-linux.tar.gz -C /apps/
[19:08:36 root@centos8 ~]#ls /apps/mycat/
bin catlet conf lib logs version.txt
mycat安装目录结构:
- bin mycat命令,启动、重启、停止等
- catlet catlet为Mycat的一个扩展功能
- conf Mycat 配置信息,重点关注
- lib Mycat引用的jar包,Mycat是java开发的
- logs 日志文件,包括Mycat启动的日志和运行的日志
- version.txt mycat版本说明
logs目录:
- wrapper.log mycat启动日志
- mycat.log mycat详细工作日志
Mycat的配置文件都在conf目录里面,这里介绍几个常用的文件:
- server.xml Mycat软件本身相关的配置文件,设置账号、参数等
- schema.xml Mycat对应的物理数据库和数据库表的配置,读写分离、高可用、分布式策略定制、节点控制
- rule.xml Mycat分片(分库分表)规则配置文件,记录分片规则列表、使用方法等
启动和连接
[19:08:47 root@centos8 ~]#vim /etc/profile.d/mycat.sh
PATH=/apps/mycat/bin:$PATH
[19:11:15 root@centos8 ~]#source /etc/profile.d/mycat.sh
#启动
[19:12:57 root@centos8 bin]#mycat start
#查看日志,确定成功
[19:13:03 root@centos8 bin]#cat /apps/mycat/logs/wrapper.log
INFO | jvm 1 | 2021/03/06 19:13:07 | MyCAT Server startup successfully. see logs in logs/mycat.log
#连接mycat:
[19:13:03 root@centos8 bin]mysql -uroot -p123456 -h 127.0.0.1 -P8066
6.2.4.3 Mycat 主要配置文件说明
server.xml
存放Mycat软件本身相关的配置文件,比如:连接Mycat的用户,密码,数据库名称等
server.xml文件中配置的参数解释说明:
- user 用户配置节点
- name 客户端登录MyCAT的用户名,也就是客户端用来连接Mycat的用户名。
- password 客户端登录MyCAT的密码
- schemas 数据库名,这里会和schema.xml中的配置关联,多个用逗号分开,例如:db1,db2
- privileges 配置用户针对表的增删改查的权限
- readOnly mycat逻辑库所具有的权限。true为只读,false为读写都有,默认为false
注意:
- server.xml文件里登录mycat的用户名和密码可以任意定义,这个账号和密码是为客户机登录mycat时使用的账号信息
- 逻辑库名(如上面的TESTDB,也就是登录mycat后显示的库名,切换这个库之后,显示的就是代理的真实mysql数据库的表)要在schema.xml里面也定义,否则会导致mycat服务启动失败!
- 这里只定义了一个标签,所以把多余的都注释了。如果定义多个标签,即设置多个连接mycat的用户名和密码,那么就需要在schema.xml文件中定义多个对应的库
schema.xml
是最主要的配置项,此文件关联mysql读写分离策略,读写分离、分库分表策略、分片节点都是在此文件中配置的.MyCat作为中间件,它只是一个代理,本身并不进行数据存储,需要连接后端的MySQL物理服务器,此文件就是用来连接MySQL服务器的
schema.xml文件中配置的参数解释说明:
- schema 数据库设置,此数据库为逻辑数据库,name与server.xml中schema对应
- dataNode 分片信息,也就是分库相关配置
- dataHost 物理数据库,真正存储数据的数据库
配置说明
- name属性唯一标识dataHost标签,供上层的标签使用。
- maxCon属性指定每个读写实例连接池的最大连接。也就是说,标签内嵌套的writeHost、readHost标签都会使用这个属性的值来实例化出连接池的最大连接数
- minCon属性指定每个读写实例连接池的最小连接,初始化连接池的大小
每个节点的属性逐一说明
schema:
- name 逻辑数据库名,与server.xml中的schema对应
- checkSQLschema 数据库前缀相关设置,这里为false
- sqlMaxLimit select 时默认的limit,避免查询全表
table
- name 表名,物理数据库中表名
- dataNode 表存储到哪些节点,多个节点用逗号分隔。节点为下文dataNode设置的name
- primaryKey 主键字段名,自动生成主键时需要设置
- autoIncrement 是否自增
- rule 分片规则名,具体规则下文rule详细介绍
dataNode
- name 节点名,与table中dataNode对应
- datahost 物理数据库名,与datahost中name对应
- database 物理数据库中数据库名
dataHost
- name 物理数据库名,与dataNode中dataHost对应
- balance 均衡负载的方式
- writeType 写入方式
- dbType 数据库类型
- heartbeat 心跳检测语句,注意语句结尾的分号要加
schema.xml文件中有三点需要注意:balance="1",writeType="0" ,switchType="1"
schema.xml中的balance的取值决定了负载均衡对非事务内的读操作的处理。balance 属性负载均衡类
型,目前的取值有 4 种:
- balance="0":不开启读写分离机制,所有读操作都发送到当前可用的writeHost上,即读请求仅发送到writeHost上
- balance="1":一般用此模式,读请求随机分发到当前writeHost对应的readHost和standby的writeHost上。即全部的readHost与stand by writeHost 参与 select 语句的负载均衡,简单的说,当双主双从模式(M1 ->S1 , M2->S2,并且 M1 与 M2 互为主备),正常情况下, M2,S1, S2 都参与 select语句的负载均衡
- balance="2":读请求随机分发到当前dataHost内所有的writeHost和readHost上。即所有读操作都随机的在writeHost、 readhost 上分发
- balance="3":读请求随机分发到当前writeHost对应的readHost上。即所有读请求随机的分发到wiriterHost 对应的 readhost 执行, writerHost 不负担读压力,注意 balance=3 只在 1.4 及其以后版本有,1.3 没有
writeHost和readHost 标签
这两个标签都指定后端数据库的相关配置给mycat,用于实例化后端连接池。
唯一不同的是:writeHost指定写实例、readHost指定读实例,组着这些读写实例来满足系统的要求。
在一个dataHost内可以定义多个writeHost和readHost。但是,如果writeHost指定的后端数据库宕机,那么这个writeHost绑定的所有readHost都将不可用。另一方面,由于这个writeHost宕机系统会自动的检测到,并切换到备用的writeHost上去
注意:
Mycat主从分离只是在读的时候做了处理,写入数据的时候,只会写入到writehost,需要通过mycat的主从复制将数据复制到readhost
6.2.4.4 实战案例:利用 Mycat 实现 MySQL 的读写分离
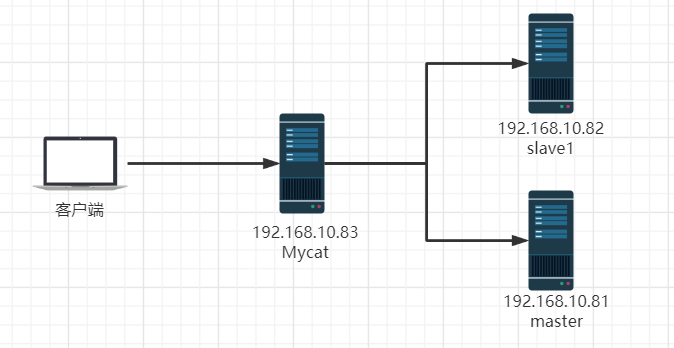
所有主机的系统环境:
cat /etc/centos-release
CentOS Linux release 8.0.1905 (Core)
服务器共三台
mycat-server 192.168.10.83 #内存建议2G以上
mysql-master 192.168.10.81 MySQL 8.0 或者Mariadb 10.3.17
mysql-slave 192.168.10.82 MySQL 8.0 或者Mariadb 10.3.17
关闭SELinux和防火墙
systemctl stop firewalld
setenforce 0
时间同步
- 创建 MySQL 主从数据库
掠过不会请查看之前文档
- 在MySQL代理服务器10.0.0.8安装mycat并启动
[19:38:02 root@centos8 ~]#yum install java wget mariadb
#确认安装
[19:38:25 root@centos8 ~]#java -version
openjdk version "1.8.0_275"
OpenJDK Runtime Environment (build 1.8.0_275-b01)
OpenJDK 64-Bit Server VM (build 25.275-b01, mixed mode)
#下载并安装
[19:38:28 root@centos8 ~]#wget http://dl.mycat.org.cn/1.6.7.4/Mycat-server-1.6.7.4-release/Mycat-server-1.6.7.4-release-20200105164103-linux.tar.gz
[19:39:10 root@centos8 ~]#mkdir /apps
[19:39:17 root@centos8 ~]#tar xvf Mycat-server-1.6.7.4-release-20200105164103-linux.tar.gz -C /apps/
#配置环境变量
[19:39:37 root@centos8 ~]#echo 'PATH=/apps/mycat/bin:$PATH' >/etc/profile.d/mycat.sh
[19:40:19 root@centos8 ~]#source /etc/profile.d/mycat.sh
#查看端口
[19:40:23 root@centos8 ~]#ss -ntl
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 0.0.0.0:22 0.0.0.0:*
LISTEN 0 128 0.0.0.0:111 0.0.0.0:*
LISTEN 0 128 [::]:22 [::]:*
LISTEN 0 128 [::]:111 [::]:*
#启动mycat
[19:40:39 root@centos8 ~]#file /apps/mycat/bin/mycat
/apps/mycat/bin/mycat: POSIX shell script, ASCII text executable
[19:40:58 root@centos8 ~]#mycat
Usage: /apps/mycat/bin/mycat { console | start | stop | restart | status | dump }
#注意: 此步启动较慢,需要等一会儿,另外如果内存太小,会导致无法启动
[19:41:06 root@centos8 ~]#mycat start
Starting Mycat-server...
#可以看到打开多个端口,其中8066端口用于连接MyCAT
[19:41:37 root@centos8 ~]#ss -ntl
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 0.0.0.0:22 0.0.0.0:*
LISTEN 0 1 127.0.0.1:32000 0.0.0.0:*
LISTEN 0 128 0.0.0.0:111 0.0.0.0:*
LISTEN 0 128 [::]:22 [::]:*
LISTEN 0 50 *:1984 *:*
LISTEN 0 50 *:32897 *:*
LISTEN 0 100 *:8066 *:*
LISTEN 0 100 *:9066 *:*
LISTEN 0 50 *:38031 *:*
LISTEN 0 128 [::]:111 [::]:*
#查看日志,确定成功,可能需要等一会儿才能看到成功的提示
[19:41:57 root@centos8 ~]#tail /apps/mycat/logs/wrapper.log
STATUS | wrapper | 2021/03/06 19:41:37 | --> Wrapper Started as Daemon
STATUS | wrapper | 2021/03/06 19:41:37 | Launching a JVM...
INFO | jvm 1 | 2021/03/06 19:41:38 | Wrapper (Version 3.2.3) http://wrapper.tanukisoftware.org
INFO | jvm 1 | 2021/03/06 19:41:38 | Copyright 1999-2006 Tanuki Software, Inc. All Rights Reserved.
INFO | jvm 1 | 2021/03/06 19:41:38 |
INFO | jvm 1 | 2021/03/06 19:41:39 | MyCAT Server startup successfully. see logs in logs/mycat.log
#用默认密码123456来连接mycat
[19:42:39 root@centos8 ~]#mysql -uroot -p123456 -h192.168.10.83 -P8066
MySQL [(none)]> show databases;
+----------+
| DATABASE |
+----------+
| TESTDB |
+----------+
MySQL [(none)]> use TESTDB
MySQL [TESTDB]> show tables;
+------------------+
| Tables in TESTDB |
+------------------+
| address |
| travelrecord |
+------------------+
MySQL [TESTDB]> select * from travelrecord;
ERROR 1105 (HY000): backend connect: java.lang.IllegalArgumentException: Invalid DataSource:0
- 在mycat 服务器上修改server.xml文件配置Mycat的连接信息
[19:49:10 root@centos8 ~]#vim /apps/mycat/conf/server.xml
#此处将8066改为3306
<property name="serverPort">3306</property>
<user name="root" defaultAccount="true"> #连接用户名
<property name="password">zhangzhuo</property> #密码
<property name="schemas">TESTDB</property> #数据库名要和schema.xml相对应
<property name="defaultSchema">TESTDB</property>
这里使用的是root,密码为magedu,逻辑数据库为TESTDB,这些信息都可以自己随意定义,读写权限都有,没有针对表做任何特殊的权限。重点关注上面这段配置,其他默认即可。
- 修改schema.xml实现读写分离策略
[19:52:54 root@centos8 ~]#vim /apps/mycat/conf/schema.xm
#最终修改效果
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1">
</schema>
<dataNode name="dn1" dataHost="localhost1" database="hellodb" />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="host1" url="192.168.10.81:3306" user="mycat"
password="123456">
<readHost host="host2" url="192.168.10.82:3306" user="mycat"
password="123456" />
</writeHost>
</dataHost>
</mycat:schema>
#账户需要在数据库新建授权
上面配置中,balance改为1,表示读写分离。以上配置达到的效果就是10.0.0.18为主库,10.0.0.28为从库
注意:要保证能使用mycat/123456权限成功登录192.168.10.81和192.168.10.82机器上面的mysql数据库。同时,也一定要授权mycat机器能使用mycat/123456权限成功登录这两台机器的mysql数据库!!这很重要,否则会导致登录mycat后,对库和表操作失败!
范例:schema.xml

- 在后端主服务器创建用户并对mycat授权
MariaDB [(none)]> create user 'mycat'@'192.168.10.%' identified by '123456';
MariaDB [(none)]> grant all privileges on *.* to 'mycat'@'192.168.10.%' identified by '123456';
- 在Mycat服务器上连接并测试
[20:05:33 root@centos8 ~]#mycat stop
[20:06:05 root@centos8 ~]#mycat start
[20:13:47 root@centos8 ~]#mysql -uroot -pzhangzhuo -h127.0.0.1
MySQL [(none)]> show databases;
+----------+
| DATABASE |
+----------+
| TESTDB |
+----------+
MySQL [(none)]> use TESTDB
#写操作是在主节点执行的
MySQL [TESTDB]> create table t1(id int);
#由于下面都是查询语句所以显示都是从节点
MySQL [TESTDB]> select @@server_id;
+-------------+
| @@server_id |
+-------------+
| 82 |
+-------------+
MySQL [TESTDB]> select @@hostname;
+----------------------+
| @@hostname |
+----------------------+
| slave1.zhangzhuo.org |
+----------------------+
- 通过通用日志确认实现读写分离
在mysql中查看通用日志
MariaDB [(none)]> show variables like 'general_log'; #查看日志是否开启
MariaDB [(none)]> set global general_log=on; #开启日志功能
MariaDB [(none)]> show variables like 'general_log_file'; #查看日志文件保存位置
+------------------+------------+
| Variable_name | Value |
+------------------+------------+
| general_log_file | master.log |
+------------------+------------+
在主和从服务器分别启用通用日志,查看读写分离
[20:30:57 root@master ~]#tail /var/lib/mysql/master.log -f
[20:30:59 root@slave1 ~]#tail -f /var/lib/mysql/slave1.log
MySQL [TESTDB]> insert into t1 values(1);
MySQL [TESTDB]> select * from t1;
+------+
| id |
+------+
| 1 |
+------+
- 停止从节点,MyCAT自动调度读请求至主节点
[20:32:11 root@slave1 ~]#systemctl stop mariadb
MySQL [TESTDB]> select @@hostname;
+----------------------+
| @@hostname |
+----------------------+
| master.zhangzhuo.org |
+----------------------+
#停止主节点,MyCAT不会自动调度写请求至从节点
MySQL [TESTDB]> insert teachers values(5,'wang',30,'M');
ERROR 1184 (HY000): java.net.ConnectException: Connection refused
- MyCAT对后端服务器的健康性检查方法select user()
#开启通用日志
[20:39:22 root@master ~]#mysql
MariaDB [(none)]> set global general_log=1;
#查看通用日志
[20:38:30 root@master ~]#tail -f /var/lib/mysql/master.log
210306 20:38:40 11 Query select user()
210306 20:38:50 14 Query select user()
6.2.5 ProxySQL
6.2.5.1 ProxySQL 介绍
ProxySQL: MySQL中间件
- 两个版本:官方版和percona版,percona版是基于官方版基础上修改
- C++语言开发,轻量级但性能优异,支持处理千亿级数据
- 具有中间件所需的绝大多数功能,包括:
- 多种方式的读/写分离
- 定制基于用户、基于schema、基于语句的规则对SQL语句进行路由
- 缓存查询结果
- 后端节点监控
官方手册:https://github.com/sysown/proxysql/wiki
6.2.5.2 ProxySQL 安装
基于YUM仓库安装
cat <<EOF | tee /etc/yum.repos.d/proxysql.repo
[proxysql_repo]
name= ProxySQL YUM repository
baseurl=http://repo.proxysql.com/ProxySQL/proxysql-1.4.x/centos/\$releasever
gpgcheck=1
gpgkey=http://repo.proxysql.com/ProxySQL/repo_pub_key
EOF
#基于RPM下载安装:https://github.com/sysown/proxysql/releases
yum install proxysql
ProxySQL组成
- 服务脚本:/etc/init.d/proxysql
- 配置文件:/etc/proxysql.cnf
- 主程序:/usr/bin/proxysql
- 基于SQLITE的数据库文件:/var/lib/proxysql/
启动ProxySQL:
service proxysql start
启动后会监听两个默认端口
- 6032:ProxySQL的管理端口
- 6033:ProxySQL对外提供服务的端口
连接ProxySQL的管理端口
使用mysql客户端连接到ProxySQL的管理接口6032,默认管理员用户和密码都是admin:
mysql -uadmin -padmin -P6032 -h127.0.0.1
数据库说明:
- main 是默认的"数据库"名,表里存放后端db实例、用户验证、路由规则等信息。表名以 runtime开头的表示
- proxysql当前运行的配置内容,不能通过dml语句修改,只能修改对应的不以 runtime_ 开头的(在内存)里的表,然后 LOAD 使其生效, SAVE 使其存到硬盘以供下次重启加载
- disk 是持久化到硬盘的配置,sqlite数据文件
- stats 是proxysql运行抓取的统计信息,包括到后端各命令的执行次数、流量、processlist、查询种类汇总/执行时间,等等
- monitor 库存储 monitor 模块收集的信息,主要是对后端db的健康/延迟检查
说明:
- 在main和monitor数据库中的表, runtime开头的是运行时的配置,不能修改,只能修改非runtime表
- 修改后必须执行LOAD … TO RUNTIME才能加载到RUNTIME生效
- 执行save … to disk 才将配置持久化保存到磁盘,即保存在proxysql.db文件中
- global_variables 有许多变量可以设置,其中就包括监听的端口、管理账号等
- 参考:https://github.com/sysown/proxysql/wiki/Global-variables
7.2.5.3 实战案例:利用 ProxySQL 实现读写分离
- 环境准备:yum安装只可以在centos7,centos8没有这个包
准备三台主机,一台ProxySQL服务器:192.168.8.7,另外两台主机实现主从复制192.168.8.17,27注意:slave节点需要设置read_only=1
- 安装ProxySQL,并向ProxySQL中添加MySQL节点,以下操作不需要use main也可成功
[11:54:48 root@proxysql ~]#cat < [proxysql_repo]
> name= ProxySQL YUM repository
> baseurl=http://repo.proxysql.com/ProxySQL/proxysql-1.4.x/centos/\$releasever
> gpgcheck=1
> gpgkey=http://repo.proxysql.com/ProxySQL/repo_pub_key
> EOF
> [12:29:13 root@proxysql ~]#yum install proxysql mariadb
> [12:27:59 root@proxysql ~]#service proxysql start
> [12:30:01 root@proxysql ~]#mysql -uadmin -padmin -h127.0.0.1 -P6032
> MySQL [(none)]> show tables;
> MySQL [(none)]> select * from sqlite_master where name='mysql_servers'\G
> MySQL [(none)]> select * from mysql_servers;
> MySQL [(none)]> insert into mysql_servers (hostgroup_id,hostname,port) values(10,'192.168.10.72',3306);
> MySQL [(none)]> insert into mysql_servers (hostgroup_id,hostname,port) values(20,'192.168.10.73',3306);
> MySQL [(none)]> load mysql servers to runtime;
> MySQL [(none)]> save mysql servers to disk;
- 添加监控后端节点的用户,连接每个节点的read_only值来自动调整主从节点是属于读组还是写组
#在master上执行
MariaDB [(none)]> grant replication client on *.* to monitor@'192.168.10.%' identified by '123456';
#ProxySQL上配置监控
MySQL [(none)]> set mysql-monitor_username='monitor';
MySQL [(none)]> set mysql-monitor_password='123456';
#加载到RUNTIME,并保存到disk
MySQL [(none)]> load mysql variables to runtime;
MySQL [(none)]> save mysql variables to disk;
- 查看监控
监控模块的指标保存在monitor库的log表中
#查看监控连接是否正常的 (对connect指标的监控),如果connect_error的结果为NULL则表示正
常
MySQL [(none)]> select * from mysql_server_connect_log;
#查看监控心跳信息 (对ping指标的监控):
MySQL [(none)]> select * from mysql_server_ping_log;
- 设置分组信息
需要修改的是main库中的mysql_replication_hostgroups表,该表有3个字段:
writer_hostgroup,reader_hostgroup,comment, 指定写组的id为10,读组的id为20
MySQL [(none)]> insert into mysql_replication_hostgroups values(10,20,"test");
#将mysql_replication_hostgroups表的修改加载到RUNTIME生效
MySQL [(none)]> load mysql servers to runtime;
MySQL [(none)]> save mysql servers to disk;
#Monitor模块监控后端的read_only值,按照read_only的值将节点自动移动到读/写组
MySQL [(none)]> select hostgroup_id,port,status,weight from mysql_servers;
+--------------+------+--------+--------+
| hostgroup_id | port | status | weight |
+--------------+------+--------+--------+
| 10 | 3306 | ONLINE | 1 |
| 20 | 3306 | ONLINE | 1 |
+--------------+------+--------+--------+
- 配置访问数据库的SQL 用户
#在master节点上创建访问用户
MariaDB [(none)]> grant all on *.* to sqluser@'192.168.10.%' identified by '123456';
#在ProxySQL配置,将用户sqluser添加到mysql_users表中, default_hostgroup默认组设置
为写组10,当读写分离的路由规则不符合时,会访问默认组的数据库
MySQL [(none)]> insert into mysql_users(username,password,default_hostgroup) values('sqluser','123456',10);
MySQL [(none)]> load mysql users to runtime;
MySQL [(none)]> save mysql users to disk;
#使用sqluser用户测试是否能路由到默认的10写组实现读、写数据
[13:10:08 root@proxysql ~]#mysql -usqluser -p123456 -P6033 -h127.0.0.1 -e'select @@server_id'
[13:10:48 root@proxysql ~]#mysql -usqluser -p123456 -P6033 -h127.0.0.1 -e'create database testdb'
[13:11:07 root@proxysql ~]#mysql -usqluser testdb -p123456 -P6033 -h127.0.0.1 -e'create table t(id int)'
- 在proxysql上配置路由规则,实现读写分离
与规则有关的表:mysql_query_rules和mysql_query_rules_fast_routing,后者是前者的扩展表,1.4.7之后支持
插入路由规则:将select语句分离到20的读组,select语句中有一个特殊语句SELECT...FOR
UPDATE它会申请写锁,应路由到10的写组
MySQL [(none)]> insert into mysql_query_rules(rule_id,active,match_digest,destination_hostgroup,apply) values(1,1,'^SELECT.*FOR UPDATE$',10,1),(2,1,'^SELECT',20,1);
MySQL [(none)]> load mysql query rules to runtime;
MySQL [(none)]> save mysql query rules to disk;
#注意:因ProxySQL根据rule_id顺序进行规则匹配,select ... for update规则的rule_id必须要小于普通的select规则的rule_id
- 测试ProxySQL
#读操作是否路由给20的读组
[13:16:49 root@proxysql ~]#mysql -usqluser -p123456 -P6033 -h127.0.0.1 -e'select @@server_id'
#测试写操作,以事务方式进行测试
[13:17:49 root@proxysql ~]#mysql -usqluser -p123456 -P6033 -h127.0.0.1 \
> -e 'start transaction;select @@server_id;commit;select @@server_id'
> [13:18:45 root@proxysql ~]#mysql -usqluser -p123456 -P6033 -h127.0.0.1 -e'insert testdb.t values (1)'
> [13:19:37 root@proxysql ~]#mysql -usqluser -p123456 -P6033 -h127.0.0.1 -e'select * from testdb.t'
> #路由的信息:查询stats库中的stats_mysql_query_digest表
> MySQL [(none)]> select hostgroup hg,sum_time,count_star,difest_text from stats_mysql_query_digest order by sum_time DESC;
6.3 MySQL 高可用
6.3.1 MySQL 高可用解决方案
MySQL官方和社区里推出了很多高可用的解决方案,大体如下,仅供参考(数据引用自Percona)
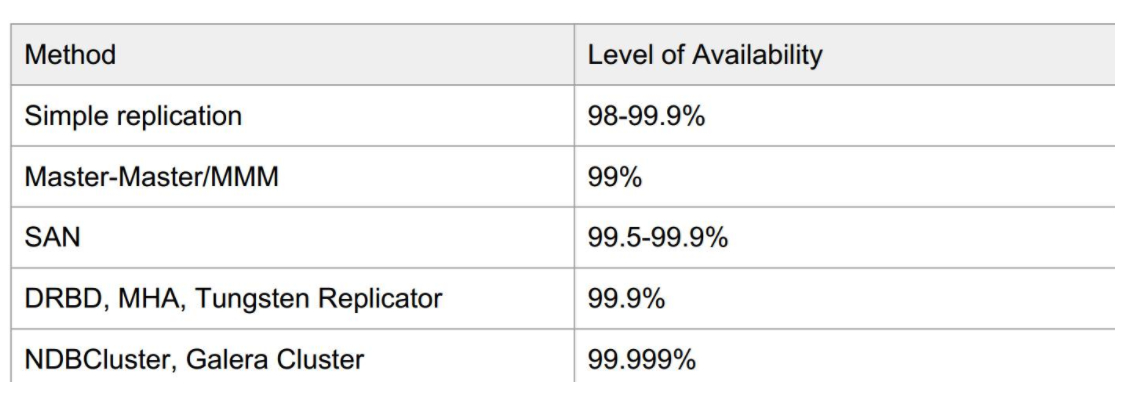
-
MMM: Multi-Master Replication Manager for MySQL,Mysql主主复制管理器是一套灵活的脚本程序,基于perl实现,用来对mysql replication进行监控和故障迁移,并能管理mysql MasterMaster复制的配置(同一时间只有一个节点是可写的)
-
MHA:Master High Availability,对主节点进行监控,可实现自动故障转移至其它从节点;通过提升某一从节点为新的主节点,基于主从复制实现,还需要客户端配合实现,目前MHA主要支持一主多从的架构,要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器,一主二从,即一台充当master,一台充当备用master,另外一台充当从库,出于机器成本的考虑,淘宝进行了改造,目前淘宝TMHA已经支持一主一从
-
Galera Cluster:wsrep(MySQL extended with the Write Set Replication)通过wsrep协议在全局实现复制;任何一节点都可读写,不需要主从复制,实现多主读写
-
GR(Group Replication):MySQL官方提供的组复制技术(MySQL 5.7.17引入的技术),基于原生复制技术Paxos算法,实现了多主更新,复制组由多个server成员构成,组中的每个server可独立地执行事务,但所有读写事务只在冲突检测成功后才会提交
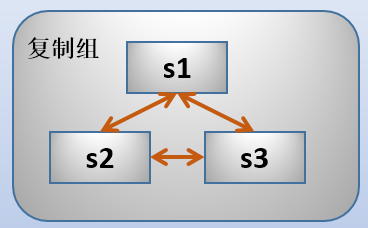
这3个节点互相通信,每当有事件发生,都会向其他节点传播该事件,然后协商,如果大多数节点都同意这次的事件,那么该事件将通过,否则该事件将失败或回滚。这些节点可以是单主模型的(single-primary),也可以是多主模型的(multi-primary)。单主模型只有一个主节点可以接受写操作,主节点故障时可以自动选举主节点。多主模型下,所有节点都可以接受写操作,所以没有master-slave的概念。
6.3.2 MHA Master High Availability
6.3.2.1 MHA 工作原理和架构
MHA集群架构
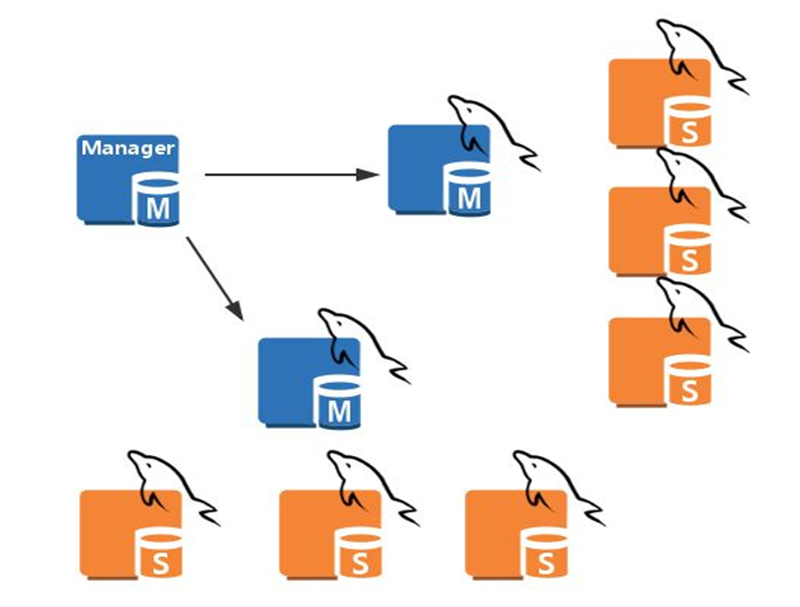
MHA工作原理
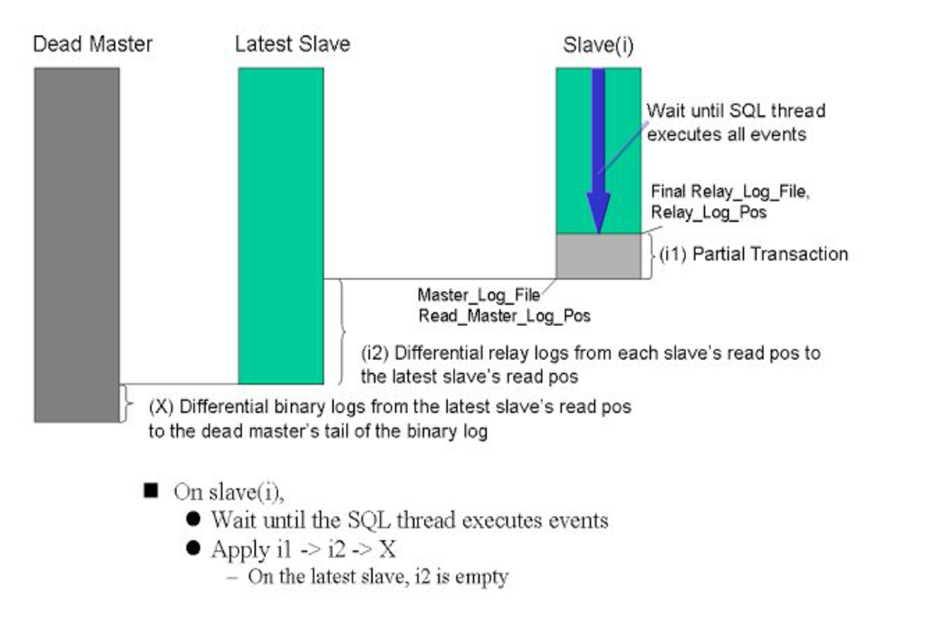
- MHA利用 SELECT 1 As Value 指令判断master服务器的健康性,一旦master 宕机,MHA 从宕机崩溃的master保存二进制日志事件(binlog events)
- 识别含有最新更新的slave
- 应用差异的中继日志(relay log)到其他的slave
- 应用从master保存的二进制日志事件(binlog events)
- 提升一个slave为新的master
- 使其他的slave连接新的master进行复制
注意:
为了尽可能的减少主库硬件损坏宕机造成的数据丢失,因此在配置MHA的同时建议配置成MySQL的半同步复制
MHA软件
MHA软件由两部分组成,Manager工具包和Node工具包
Manager工具包主要包括以下几个工具:
masterha_check_ssh 检查MHA的SSH配置状况
masterha_check_repl 检查MySQL复制状况
masterha_manger 启动MHA
masterha_check_status 检测当前MHA运行状态
masterha_master_monitor 检测master是否宕机
masterha_master_switch 故障转移(自动或手动)
masterha_conf_host 添加或删除配置的server信息
masterha_stop --conf=app1.cnf 停止MHA
masterha_secondary_check 两个或多个网络线路检查MySQL主服务器的可用
Node工具包:这些工具通常由MHA Manager的脚本触发,无需人为操作)主要包括以下几个工具:
save_binary_logs #保存和复制master的二进制日志
apply_diff_relay_logs #识别差异的中继日志事件并将其差异的事件应用于其他的slave
filter_mysqlbinlog #去除不必要的ROLLBACK事件(MHA已不再使用此工具)
purge_relay_logs #清除中继日志(不会阻塞SQL线程)
MHA配置文件:
global配置,为各application提供默认配置,默认文件路径 /etc/masterha_default.cnf
application配置:为每个主从复制集群
6.3.2.2 实现 MHA 实战案例
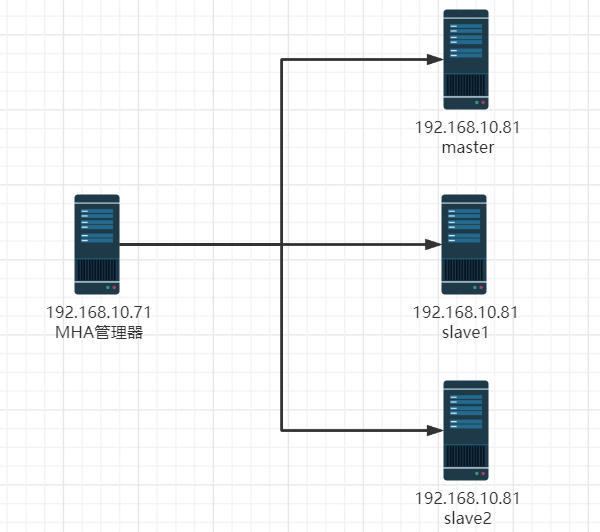
环境:四台主机
192.168.10.71 CentOS7 MHA管理端
192.168.10.81 CentOS8 MySQL8.0 Master
192.168.10.82 CentOS8 MySQL8.0 Slave1
192.168.10.83 CentOS8 MySQL8.0 Slave2
在管理节点上安装两个包mha4mysql-manager和mha4mysql-node
说明:
mha4mysql-manager-0.56-0.el6.noarch.rpm 不支持CentOS 8,只支持CentOS7 以下版本
mha4mysql-manager-0.58-0.el7.centos.noarch.rpm 支持MySQL5.7和MySQL8.0 ,但和CentOS8版本上的Mariadb -10.3.17不兼容
安装:服务端先装node在装manager
[14:31:45 root@mha ~]#yum install ./mha4mysql-node-0.58-0.el7.centos.noarch.rpm
[14:31:45 root@mha ~]#yum install ./mha4mysql-manager-0.58-0.el7.centos.noarch.rpm
在所有MySQL服务器上安装mha4mysql-node包
[14:35:08 root@master ~]#yum install ./mha4mysql-node-0.58-0.el7.centos.noarch.rpm -y
在所有节点实现相互之间ssh key验证
[14:37:38 root@mha ~]#ssh-keygen
[14:37:38 root@mha ~]#ssh-copy-id 192.168.10.71
[14:37:38 root@mha ~]#scp -r .ssh 192.168.10.81:/root/
[14:37:38 root@mha ~]#scp -r .ssh 192.168.10.82:/root/
[14:37:38 root@mha ~]#scp -r .ssh 192.168.10.83:/root/
在管理节点建立配置文件
注意: 此文件的行尾不要加空格等符号
[server default]
user=mhauser #用于远程连接MySQL所有节点的用户,需要有管理员的权限
password=123456
manager_workdir=/data/mastermha/app1/ #目录会自动生成,无需手动创建
manager_log=/data/mastermha/app1/manager.log
remote_workdir=/data/mastermha/app1/
ssh_user=root #用于实现远程ssh基于KEY的连接,访问二进制日志
repl_user=slave #主从复制的用户信息
repl_password=123456
ping_interval=1 #健康性检查的时间间隔
master_ip_failover_script=/usr/local/bin/master_ip_failover #切换VIP的perl脚本
report_script=/usr/local/bin/sendmail.sh #当执行报警脚本
check_repl_delay=0 #默认如果slave中从库落后主库relaylog超过100M,主库不会选择这个从库
为新的master,因为这个从库进行恢复需要很长的时间.通过这个参数,mha触发主从切换的时候会忽略复制
的延时,通过check_repl_delay=0这个参数,mha触发主从切换时会忽略复制的延时,对于设置
candidate_master=1的从库非常有用,这样确保这个从库一定能成为最新的master
master_binlog_dir=/var/lib/mysql/ #指定二进制日志存放的目录,mha4mysql-manager-0.58必须指定,之前版本不需要指定
[server1]
hostname=192.168.10.81
candidate_master=1
[server2]
hostname=192.168.10.82
candidate_master=1
[server3]
hostname=192.168.10.83
说明: 主库宕机谁来接管新的master
1. 所有从节点日志都是一致的,默认会以配置文件的顺序去选择一个新主
2. 从节点日志不一致,自动选择最接近于主库的从库充当新主
3. 如果对于某节点设定了权重(candidate_master=1),权重节点会优先选择。但是此节点日志量落后主库超过100M日志的话,也不会被选择。可以配合check_repl_delay=0,关闭日志量的检查,强制选择候选节点
相关脚本
[14:57:06 root@mha ~]#vim /usr/local/bin/sendmail.sh
echo "MYSQL is down" | mail -s "MHA Warning" 1191400158@qq.com
[15:00:14 root@mha ~]#chmod +x /usr/local/bin/sendmail.sh
[15:01:44 root@mha ~]#cp master_ip_failover /usr/local/bin/
[15:02:06 root@mha ~]#chmod +x /usr/local/bin/master_ip_failover
实现主从架构,这里不在记录,只记录mha所需配置
mysql> create user mhauser@'192.168.10.%' identified by '123456';
Query OK, 0 rows affected (0.02 sec)
mysql> grant all on *.* to mhauser@'192.168.10.%';
Query OK, 0 rows affected (0.01 sec)
#配置VIP
[15:12:13 root@master ~]#ifconfig eth0:1 192.168.10.100/24
检查Mha的环境
#检查环境,最后一句是下面这样的才表示通过
[15:03:24 root@mha ~]#masterha_check_ssh --conf=/etc/mastermha/app1.cnf
Sun Mar 7 15:05:50 2021 - [info] All SSH connection tests passed successfully.
[root@mha-manager ~]#masterha_check_repl --conf=/etc/mastermha/app1.cnf
MySQL Replication Health is OK.
#查看状态
[root@mha-manager ~]#masterha_check_status --conf=/etc/mastermha/app1.cnf
启动MHA
#开启MHA,默认是前台运行
[15:23:40 root@mha ~]#nohup masterha_manager --conf=/etc/mastermha/app1.cnf
nohup: ignoring input and appending output to ‘nohup.out’
#查看状态
[15:25:45 root@mha ~]#masterha_check_status --conf=/etc/mastermha/app1.cnf
app1 (pid:28968) is running(0:PING_OK), master:192.168.10.81
排错日志
[15:28:51 root@mha ~]#tail /data/mastermha/app1/manager.log
IN SCRIPT TEST====/sbin/ifconfig eth0:1 down==/sbin/ifconfig eth0:1 192.168.10.100;/sbin/arping -I eth0 -c 3 -s 192.168.10.100 192.168.10.2 >/dev/null 2>&1===
Checking the Status of the script.. OK
Sun Mar 7 15:24:59 2021 - [info] OK.
Sun Mar 7 15:24:59 2021 - [warning] shutdown_script is not defined.
Sun Mar 7 15:24:59 2021 - [info] Set master ping interval 1 seconds.
Sun Mar 7 15:24:59 2021 - [warning] secondary_check_script is not defined. It is highly recommended setting it to check master reachability from two or more routes.
Sun Mar 7 15:24:59 2021 - [info] Starting ping health check on 192.168.10.81(192.168.10.81:3306)..
Sun Mar 7 15:24:59 2021 - [info] Ping(SELECT) succeeded, waiting until MySQL doesn't respond..
模拟故障
#当 master down机后,mha管理程序自动退出
[15:26:02 root@master ~]#systemctl stop mysqld.service
[15:32:32 root@mha ~]#tail /data/mastermha/app1/manager.log
The latest slave 192.168.10.82(192.168.10.82:3306) has all relay logs for recovery.
Selected 192.168.10.82(192.168.10.82:3306) as a new master.
192.168.10.82(192.168.10.82:3306): OK: Applying all logs succeeded.
192.168.10.82(192.168.10.82:3306): OK: Activated master IP address.
192.168.10.83(192.168.10.83:3306): This host has the latest relay log events.
Generating relay diff files from the latest slave succeeded.
192.168.10.83(192.168.10.83:3306): OK: Applying all logs succeeded. Slave started, replicating from 192.168.10.82(192.168.10.82:3306)
192.168.10.82(192.168.10.82:3306): Resetting slave info succeeded.
Master failover to 192.168.10.82(192.168.10.82:3306) completed successfully.
Sun Mar 7 15:30:28 2021 - [info] Sending mail..
[15:30:28 root@mha ~]#masterha_check_status --conf=/etc/mastermha/app1.cnf
app1 is stopped(2:NOT_RUNNING).
#验证VIP漂移至新的Master上
[15:33:11 root@slave1 ~]#ifconfig eth0:1
eth0:1: flags=4163 mtu 1500
inet 192.168.10.100 netmask 255.255.255.0 broadcast 192.168.10.255
ether 00:0c:29:1a:4b:7f txqueuelen 1000 (Ethernet)
收到报警邮件
如果再次运行MHA,需要先删除下面文件
[15:36:39 root@mha ~]#ls /data/mastermha/app1/app1.failover.complete -l
-rw-r--r-- 1 root root 0 Mar 7 15:30 /data/mastermha/app1/app1.failover.complete
[15:36:49 root@mha ~]#rm -f /data/mastermha/app1/app1.failover.complete
6.3.3 Galera Cluster
6.3.3.1 Galera Cluster 介绍
Galera Cluster:集成了Galera插件的MySQL集群,是一种新型的,数据不共享的,高度冗余的高可用方案,目前Galera Cluster有两个版本,分别是Percona Xtradb Cluster及MariaDB Cluster,Galera本身是具有多主特性的,即采用multi-master的集群架构,是一个既稳健,又在数据一致性、完整性及高性能方面有出色表现的高可用解决方案
Galera Cluster特点
- 多主架构:真正的多点读写的集群,在任何时候读写数据,都是最新的
- 同步复制:集群不同节点之间数据同步,没有延迟,在数据库挂掉之后,数据不会丢失
- 并发复制:从节点APPLY数据时,支持并行执行,更好的性能
- 故障切换:在出现数据库故障时,因支持多点写入,切换容易
- 热插拔:在服务期间,如果数据库挂了,只要监控程序发现的够快,不可服务时间就会非常少。在节点故障期间,节点本身对集群的影响非常小
- 自动节点克隆:在新增节点,或者停机维护时,增量数据或者基础数据不需要人工手动备份提供,Galera Cluster会自动拉取在线节点数据,最终集群会变为一致
- 对应用透明:集群的维护,对应用程序是透明的
Galera Cluster 缺点
- 由于DDL 需全局验证通过,则集群性能由集群中最差性能节点决定(一般集群节点配置都是一样
- 的)
- 新节点加入或延后较大的节点重新加入需全量拷贝数据(SST,State Snapshot Transfer),作为donor( 贡献者,如: 同步数据时的提供者)的节点在同步过程中无法提供读写
- 只支持innodb存储引擎的表
Galera Cluster工作过程
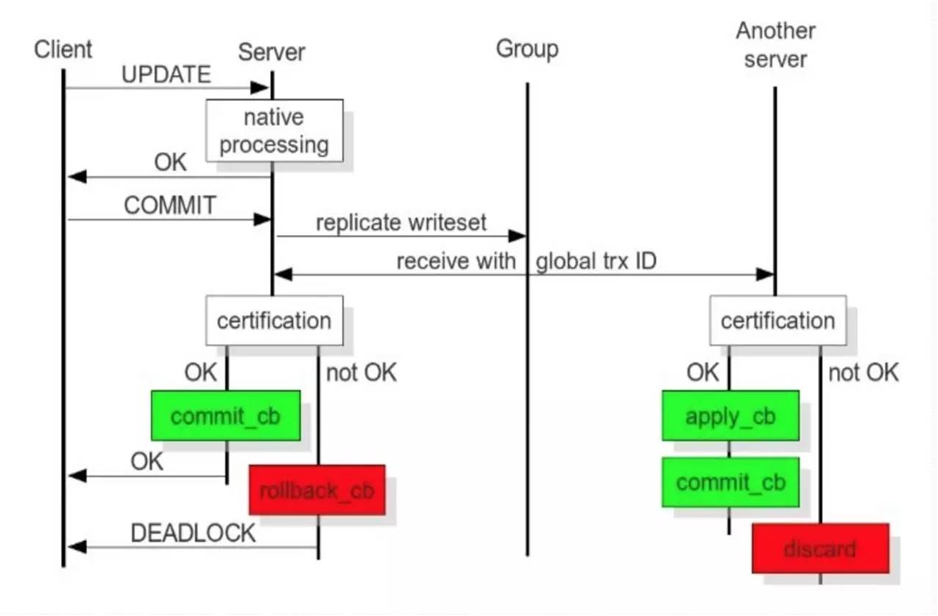
Galera Cluster官方文档:
- http://galeracluster.com/documentation-webpages/galera-documentation.pdf
- http://galeracluster.com/documentation-webpages/index.html
- https://www.percona.com/doc/percona-xtradb-cluster/LATEST/index.html
- https://mariadb.com/kb/en/library/getting-started-with-mariadb-galera-cluster/
Galera Cluster 包括两个组件
- Galera replication library (galera-3)
- WSREP:MySQL extended with the Write Set Replication
WSREP复制实现:
- PXC:Percona XtraDB Cluster,是Percona对Galera的实现
- MariaDB Galera Cluster:
注意:两者都需要至少三个节点,不能安装mysql server 或 mariadb-server
6.3.3.2 PXC 原理
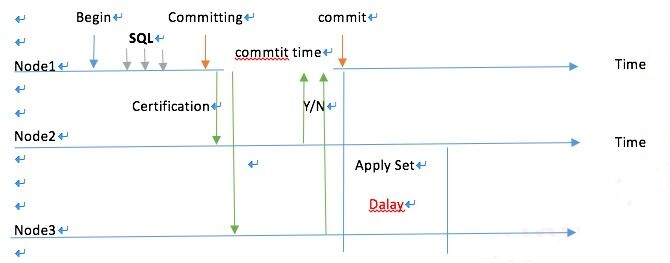
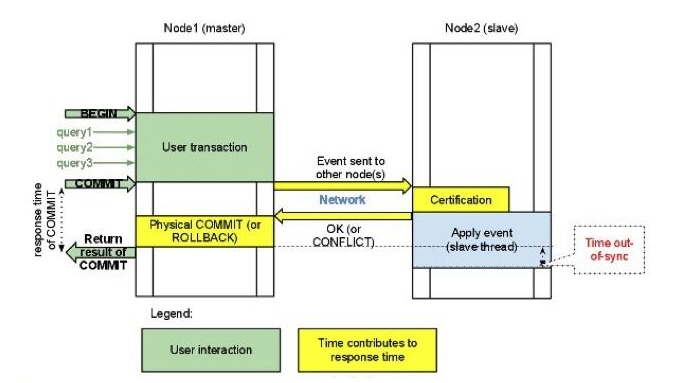
PXC最常使用如下4个端口号:
- 3306:数据库对外服务的端口号
- 4444:请求SST的端口号
- 4567:组成员之间进行沟通的端口号
- 4568:用于传输IST的端口号
PXC中涉及到的重要概念和核心参数:
(1)集群中节点的数量:整个集群中节点数量应该控制在最少3个、最多8个的范围内。最少3个节点是为了防止出现脑裂现象,因为只有在2个节点下才会出现此现象。脑裂现象的标志就是输入任何命令,返回的结果都是unknown command。节点在集群中,会因新节点的加入或故障、同步失效等原因发生状态的切换。
(2)节点状态的变化阶段:
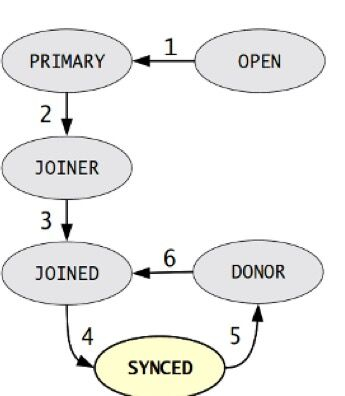
- open:节点启动成功,尝试连接到集群时的状态
- primary:节点已处于集群中,在新节点加入并选取donor进行数据同步时的状态
- joiner:节点处于等待接收同步文件时的状态
- joined:节点完成数据同步工作,尝试保持和集群进度一致时的状态
- synced:节点正常提供服务时的状态,表示已经同步完成并和集群进度保持一致
- donor:节点处于为新加入的节点提供全量数据时的状态
备注:donor节点就是数据的贡献者,如果一个新节点加入集群,此时又需要大量数据的SST数据传输,就有可能因此而拖垮整个集群的性能,所以在生产环境中,如果数据量较小,还可以使用SST全量数据传输,但如果数据量很大就不建议使用这种方式,可以考虑先建立主从关系,然后再加入集群。
(3)节点的数据传输方式:
- SST:State Snapshot Transfer,全量数据传输
- IST:Incremental State Transfer,增量数据传输
SST数据传输有xtrabackup、mysqldump和rsync三种方式,而增量数据传输就只有一种方式xtrabackup,但生产环境中一般数据量较小时,可以使用SST全量数据传输,但也只使用xtrabackup方法。
(4)GCache模块:在PXC中一个特别重要的模块,它的核心功能就是为每个节点缓存当前最新的写集。如果有新节点加入进来,就可以把新数据的增量传递给新节点,而不需要再使用SST传输方式,这样可以让节点更快地加入集群中,涉及如下参数:
- gcache.size:缓存写集增量信息的大小,它的默认大小是128MB,通过wsrep_provider_options参数设置,建议调整为2GB~4GB范围,足够的空间便于缓存更多的增量信息。
- gcache.mem_size:GCache中内存缓存的大小,适度调大可以提高整个集群的性能
- gcache.page_size:如果内存不够用(GCache不足),就直接将写集写入磁盘文件中
6.3.3.3 实战案例:Percona XtraDB Cluster(PXC 5.7)
1 环境准备
四台主机:
pxc1:192.168.10.71
pxc2:192.168.10.72
pxc3:192.168.10.73
pxc4:192.168.10.74
OS 版本目前不支持CentOS 8
[root@pxc1 ~]#cat /etc/redhat-release
CentOS Linux release 7.6.1810 (Core)
关闭防火墙和SELinux,保证时间同步
注意:如果已经安装MySQL,必须卸载
2 安装 Percona XtraDB Cluster 5.7
#此处使用清华大学yum源,官方源太慢了
[16:24:22 root@pxc1 ~]#vim /etc/yum.repos.d/pxc.repo
[percona]
name=percona_repo
baseurl=https://mirrors.tuna.tsinghua.edu.cn/percona/release/$releasever/RPMS/$basearch/
enabled=1
gpgcheck=0
[16:24:52 root@pxc1 ~]#scp /etc/yum.repos.d/pxc.repo 192.168.10.72:/etc/yum.repos.d/
[16:24:52 root@pxc1 ~]#scp /etc/yum.repos.d/pxc.repo 192.168.10.73:/etc/yum.repos.d/
#在三个节点都安装好PXC 5.7
[16:29:06 root@pxc1 ~]#yum install Percona-XtraDB-Cluster-57 -y
[16:29:06 root@pxc2 ~]#yum install Percona-XtraDB-Cluster-57 -y
[16:29:06 root@pxc3 ~]#yum install Percona-XtraDB-Cluster-57 -y
[16:30:03 root@pxc1 ~]#rpm -ql Percona-XtraDB-Cluster-server-57
3 在各个节点上分别配置mysql及集群配置文件
/etc/my.cnf为主配置文件,当前版本中,其余的配置文件都放在/etc/percona-xtradb-cluster.conf.d目录里,包括mysqld.cnf,mysqld_safe.cnf,wsrep.cnf 三个文件
#主配置文件不需要修改
[16:30:45 root@pxc1 ~]#cat /etc/my.cnf
[16:30:53 root@pxc1 ~]#ls /etc/my.cnf.d/
[16:31:16 root@pxc1 ~]#ls /etc/percona-xtradb-cluster.conf.d/
mysqld.cnf mysqld_safe.cnf wsrep.cnf
#下面配置文件不需要修改
[16:29:07 root@pxc2 ~]#vim /etc/percona-xtradb-cluster.conf.d/mysqld.cnf
[client]
socket=/var/lib/mysql/mysql.sock
[mysqld]
server-id=71 #建议各个节点不同
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
log-error=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
log-bin #建议启用,非必须项
log_slave_updates
expire_logs_days=7
symbolic-links=0
#下面配置文件不需要修改
[16:32:37 root@pxc1 ~]#cat /etc/percona-xtradb-cluster.conf.d/mysqld_safe.cnf
#PXC的配置文件必须修改
[16:37:21 root@pxc1 ~]#grep -Ev '^#|^$' /etc/percona-xtradb-cluster.conf.d/wsrep.cnf[mysqld]
wsrep_provider=/usr/lib64/galera3/libgalera_smm.so
wsrep_cluster_address=gcomm://192.168.10.71,192.168.10.72,192.168.10.73 #三个节点的IP
binlog_format=ROW
default_storage_engine=InnoDB
wsrep_slave_threads= 8
wsrep_log_conflicts
innodb_autoinc_lock_mode=2
wsrep_node_address=192.168.10.71 #各个节点,指定自已的IP
wsrep_cluster_name=pxc-cluster
wsrep_node_name=pxc-cluster-node-1 #各个节点,指定自已节点名称
pxc_strict_mode=ENFORCING
wsrep_sst_method=xtrabackup-v2
wsrep_sst_auth="sstuser:s3cretPass" #取消本行注释,同一集群内多个节点的验证用户和密码信息必须一致
[16:39:38 root@pxc2 ~]#grep -Ev '^#|^$' /etc/percona-xtradb-cluster.conf.d/wsrep.cnf[mysqld]
wsrep_provider=/usr/lib64/galera3/libgalera_smm.so
wsrep_cluster_address=gcomm://192.168.10.71,192.168.10.72,192.168.10.73
binlog_format=ROW
default_storage_engine=InnoDB
wsrep_slave_threads= 8
wsrep_log_conflicts
innodb_autoinc_lock_mode=2
wsrep_node_address=192.168.10.72
wsrep_cluster_name=pxc-cluster
wsrep_node_name=pxc-cluster-node-2
pxc_strict_mode=ENFORCING
wsrep_sst_method=xtrabackup-v2
wsrep_sst_auth="sstuser:s3cretPass"
[16:40:30 root@pxc3 ~]#grep -Ev '^#|^$' /etc/percona-xtradb-cluster.conf.d/wsrep.cnf[mysqld]
wsrep_provider=/usr/lib64/galera3/libgalera_smm.so
wsrep_cluster_address=gcomm://192.168.10.71,192.168.10.72,192.168.10.73
binlog_format=ROW
default_storage_engine=InnoDB
wsrep_slave_threads= 8
wsrep_log_conflicts
innodb_autoinc_lock_mode=2
wsrep_node_address=192.168.10.73
wsrep_cluster_name=pxc-cluster
wsrep_node_name=pxc-cluster-node-3
pxc_strict_mode=ENFORCING
wsrep_sst_method=xtrabackup-v2
wsrep_sst_auth="sstuser:s3cretPass"
注意:尽管Galera Cluster不再需要通过binlog的形式进行同步,但还是建议在配置文件中开启二进制日志功能,原因是后期如果有新节点需要加入,老节点通过SST全量传输的方式向新节点传输数据,很可能会拖垮集群性能,所以让新节点先通过binlog方式完成同步后再加入集群会是一种更好的选择
配置文件各项配置意义
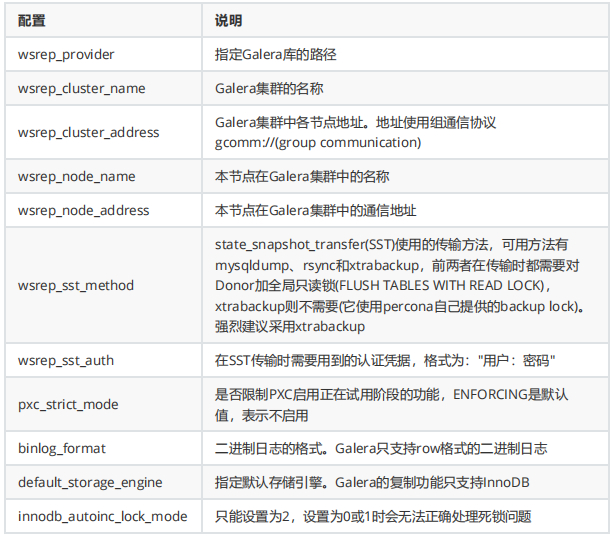
4 启动PXC集群中第一个节点
[16:40:09 root@pxc1 ~]#ss -ntul
Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port
udp UNCONN 0 0 *:111 *:*
udp UNCONN 0 0 127.0.0.1:323 *:*
udp UNCONN 0 0 *:835 *:*
udp UNCONN 0 0 [::]:111 [::]:*
udp UNCONN 0 0 [::1]:323 [::]:*
udp UNCONN 0 0 [::]:835 [::]:*
tcp LISTEN 0 128 *:111 *:*
tcp LISTEN 0 128 *:22 *:*
tcp LISTEN 0 100 127.0.0.1:25 *:*
tcp LISTEN 0 128 [::]:111 [::]:*
tcp LISTEN 0 128 [::]:22 [::]:*
tcp LISTEN 0 100 [::1]:25 [::]:*
#启动第一个节点
[16:42:12 root@pxc1 ~]#systemctl start mysql@bootstrap.service
[16:44:02 root@pxc1 ~]#ss -ntul
Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port
udp UNCONN 0 0 *:111 *:*
udp UNCONN 0 0 127.0.0.1:323 *:*
udp UNCONN 0 0 *:835 *:*
udp UNCONN 0 0 [::]:111 [::]:*
udp UNCONN 0 0 [::1]:323 [::]:*
udp UNCONN 0 0 [::]:835 [::]:*
tcp LISTEN 0 128 *:111 *:*
tcp LISTEN 0 128 *:22 *:*
tcp LISTEN 0 128 *:4567 *:*
tcp LISTEN 0 100 127.0.0.1:25 *:*
tcp LISTEN 0 128 [::]:111 [::]:*
tcp LISTEN 0 128 [::]:22 [::]:*
tcp LISTEN 0 100 [::1]:25 [::]:*
tcp LISTEN 0 80 [::]:3306 [::]:*
#查看root密码
[16:43:50 root@pxc1 ~]#grep "temporary password" /var/log/mysqld.log
2021-03-07T08:43:32.682088Z 1 [Note] A temporary password is generated for root@localhost: d15<(jfwu%hW
[16:44:59 root@pxc1 ~]#mysql -uroot -p'd15<(jfwu%hW'
#修改root密码俩种方法
mysql> set password for root@'localhost'='123456';
Query OK, 0 rows affected (0.01 sec)
mysql> alter user 'root'@'localhost' identified by '123456';
Query OK, 0 rows affected (0.01 sec)
#创建相关用户并授权
mysql> create user 'sstuser'@'localhost' identified by 's3cretPass';
mysql> grant reload,lock tables,process,replication client on *.* to 'sstuser'@'localhost';
#查看相关变量
mysql> show variables like 'wsrep%'\G
#查看相关状态变量
mysql> show status like 'wsrep%'\G
#重点关注下面内容
mysql> show status like 'wsrep%';
+----------------------------+--------------------------------------+
| Variable_name | Value |
+----------------------------+--------------------------------------+
| wsrep_local_state_uuid | aad2c02e-131c-11ea-9294-b2e80a6c08c4 |
| ... | ... |
| wsrep_local_state | 4 |
| wsrep_local_state_comment | Synced |
| ... | ... |
| wsrep_cluster_size | 1 |
| wsrep_cluster_status | Primary |
| wsrep_connected | ON |
| ... | ... |
| wsrep_ready | ON |
+----------------------------+--------------------------------------+
说明:
- wsrep_cluster_size表示,该Galera集群中只有一个节点
- wsrep_local_state_comment 状态为Synced(4),表示数据已同步完成(因为是第一个引导节点,无数据需要同步)。 如果状态是Joiner, 意味着 SST 没有完成. 只有所有节点状态是Synced,才可以加新点
- wsrep_cluster_status为Primary,且已经完全连接并准备好
5 启动PXC集群中其它所有节点
[16:40:16 root@pxc2 ~]#systemctl start mysql
[16:53:26 root@pxc2 ~]#ss -ntul
Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port
udp UNCONN 0 0 *:111 *:*
udp UNCONN 0 0 127.0.0.1:323 *:*
udp UNCONN 0 0 *:841 *:*
udp UNCONN 0 0 [::]:111 [::]:*
udp UNCONN 0 0 [::1]:323 [::]:*
udp UNCONN 0 0 [::]:841 [::]:*
tcp LISTEN 0 100 127.0.0.1:25 *:*
tcp LISTEN 0 128 *:111 *:*
tcp LISTEN 0 128 *:22 *:*
tcp LISTEN 0 128 *:4567 *:*
tcp LISTEN 0 100 [::1]:25 [::]:*
tcp LISTEN 0 80 [::]:3306 [::]:*
tcp LISTEN 0 128 [::]:111 [::]:*
tcp LISTEN 0 128 [::]:22 [::]:*
6 查看集群状态,验证集群是否成功
#在任意节点,查看集群状态
[16:54:33 root@pxc1 ~]#mysql -uroot -p'123456'
mysql> show variables like 'wsrep_node_name';
+-----------------+--------------------+
| Variable_name | Value |
+-----------------+--------------------+
| wsrep_node_name | pxc-cluster-node-1 |
+-----------------+--------------------+
mysql> show variables like 'wsrep_node_address';
+--------------------+---------------+
| Variable_name | Value |
+--------------------+---------------+
| wsrep_node_address | 192.168.10.71 |
+--------------------+---------------+
mysql> show variables like 'wsrep_on';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| wsrep_on | ON |
+---------------+-------+
#在任意节点查看数据库
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+
#在任意节点创建数据库
mysql> create database testdb1;
Query OK, 1 row affected (0.01 sec)
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
| testdb1 |
+--------------------+
#在任意其它节点验证数据是否同步
[16:58:23 root@pxc2 ~]#mysql -uroot -p123456
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
| testdb1 |
+--------------------+
#利用Xshell软件,同时在三个节点数据库,在其中一个节点成功
mysql> create database testdb2;
Query OK, 1 row affected (0.10 sec)
#在其它节点都提示失败
mysql> create database testdb2;
ERROR 1007 (HY000): Can't create database 'testdb2'; database exists
7 在PXC集群中加入节点
一个节点加入到Galera集群有两种情况:新节点加入集群、暂时离组的成员再次加入集群
- 新节点加入Galera集群
新节点加入集群时,需要从当前集群中选择一个Donor节点来同步数据,也就是所谓的state_snapshot_tranfer(SST)过程。SST同步数据的方式由选项wsrep_sst_method决定,一般选择的是xtrabackup。
必须注意,新节点加入Galera时,会删除新节点上所有已有数据,再通过xtrabackup(假设使用的是该方式)从Donor处完整备份所有数据进行恢复。所以,如果数据量很大,新节点加入过程会很慢。而且,在一个新节点成为Synced状态之前,不要同时加入其它新节点,否则很容易将集群压垮。如果是这种情况,可以考虑使用wsrep_sst_method=rsync来做增量同步,既然是增量同步,最好保证新节点上已经有一部分数据基础,否则和全量同步没什么区别,且这样会对Donor节点加上全局readonly锁。
- 旧节点加入Galera集群
如果旧节点加入Galera集群,说明这个节点在之前已经在Galera集群中呆过,有一部分数据基础,缺少的只是它离开集群时的数据。这时加入集群时,会采用IST(incremental snapshot transfer)传输机制,即使用增量传输。
但注意,这部分增量传输的数据源是Donor上缓存在GCache文件中的,这个文件有大小限制,如果缺失的数据范围超过已缓存的内容,则自动转为SST传输。如果旧节点上的数据和Donor上的数据不匹配(例如这个节点离组后人为修改了一点数据),则自动转为SST传输。
#在PXC集群中再加一台新的主机PXC4:192.168.10.74
[17:03:09 root@pxc4 ~]#yum install -y Percona-XtraDB-Cluster-57
[17:05:01 root@pxc4 ~]#vim /etc/percona-xtradb-cluster.conf.d/mysqld.cnf
server-id=74
[17:06:50 root@pxc4 ~]#grep -Ev '^#|^$' /etc/percona-xtradb-cluster.conf.d/wsrep.cnf[mysqld]
wsrep_provider=/usr/lib64/galera3/libgalera_smm.so
wsrep_cluster_address=gcomm://192.168.10.71,192.168.10.72,192.168.10.73,192.168.10.74
binlog_format=ROW
default_storage_engine=InnoDB
wsrep_slave_threads= 8
wsrep_log_conflicts
innodb_autoinc_lock_mode=2
wsrep_node_address=192.168.10.74
wsrep_cluster_name=pxc-cluster
wsrep_node_name=pxc-cluster-node-4
pxc_strict_mode=ENFORCING
wsrep_sst_method=xtrabackup-v2
wsrep_sst_auth="sstuser:s3cretPass"
[17:07:08 root@pxc4 ~]#systemctl start mysql
[17:08:00 root@pxc4 ~]#mysql -uroot -p123456
mysql> show status like 'wsrep_cluster_size';
+--------------------+-------+
| Variable_name | Value |
+--------------------+-------+
| wsrep_cluster_size | 4 |
+--------------------+-------+
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
| testdb1 |
| testdb2 |
+--------------------+
#将其它节点的配置文件加以修改
[17:09:34 root@pxc1 ~]#vim /etc/percona-xtradb-cluster.conf.d/wsrep.cnf
wsrep_cluster_address=gcomm://192.168.10.71,192.168.10.72,192.168.10.73,192.168.10.74
8 在PXC集群中修复故障节点
#在除第一个启动节点外的任意节点停止服务
[17:09:19 root@pxc4 ~]#systemctl stop mysql
#在其它任意节点查看wsrep_cluster_size变量少了一个节点
[17:10:20 root@pxc1 ~]#mysql -uroot -p123456
mysql> show status like 'wsrep_cluster_size';
+--------------------+-------+
| Variable_name | Value |
+--------------------+-------+
| wsrep_cluster_size | 3 |
+--------------------+-------+
mysql> create database testdb4;
#在其它任意节点可看到数据已同步
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
| testdb1 |
| testdb2 |
| testdb4 |
+--------------------+
#恢复服务,数据同步
[17:14:17 root@pxc4 ~]#systemctl start mysql
[17:15:46 root@pxc4 ~]#mysql -uroot -p123456
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
| testdb1 |
| testdb2 |
| testdb4 |
+--------------------+
mysql> show status like 'wsrep_cluster_size';
+--------------------+-------+
| Variable_name | Value |
+--------------------+-------+
| wsrep_cluster_size | 4 |
+--------------------+-------+
6.3.3.4 实战案例:MariaDB Galera Cluster
范例:在centos8 实现MariaDB Galera Cluster
#在三个节点上都实现
[17:27:55 root@centos8 ~]#yum install mariadb-server-galera.x86_64 -y
[17:32:39 root@centos8 ~]#vim /etc/my.cnf.d/galera.cnf
#wsrep_cluster_address="dummy://" #在此行下面加一行
wsrep_cluster_address="gcomm://192.168.10.81,192.168.10.82,192.168.10.83"
#启动第一节点
[17:32:53 root@centos8 ~]#galera_new_cluster
[17:33:42 root@centos8 ~]#systemctl enable mariadb
#再启动其它节点
[17:32:53 root@centos8 ~]#systemctl enable --now mariadb
[17:34:31 root@centos8 ~]#ss -ntul
Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port
udp UNCONN 0 0 127.0.0.1:323 0.0.0.0:*
udp UNCONN 0 0 0.0.0.0:111 0.0.0.0:*
udp UNCONN 0 0 [::1]:323 [::]:*
udp UNCONN 0 0 [::]:111 [::]:*
tcp LISTEN 0 80 0.0.0.0:3306 0.0.0.0:*
tcp LISTEN 0 128 0.0.0.0:111 0.0.0.0:*
tcp LISTEN 0 128 0.0.0.0:22 0.0.0.0:*
tcp LISTEN 0 128 0.0.0.0:4567 0.0.0.0:*
tcp LISTEN 0 128 [::]:111 [::]:*
tcp LISTEN 0 128 [::]:22 [::]:*
[17:34:36 root@centos8 ~]#mysql
MariaDB [(none)]> show status like 'wsrep_ready';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| wsrep_ready | ON |
+---------------+-------+
1 row in set (0.001 sec)
MariaDB [(none)]> show status like 'wsrep_cluster_size';
+--------------------+-------+
| Variable_name | Value |
+--------------------+-------+
| wsrep_cluster_size | 3 |
+--------------------+-------+
1 row in set (0.001 sec)
范例:CentOS 7 实现 MariaDB Galera Cluster 5.5
#参考仓库:https://mirrors.tuna.tsinghua.edu.cn/mariadb/mariadb-5.5.X/yum/centos7-
amd64/
yum install MariaDB-Galera-server
vim /etc/my.cnf.d/server.cnf
[galera]
wsrep_provider = /usr/lib64/galera/libgalera_smm.so
wsrep_cluster_address="gcomm://10.0.0.7,10.0.0.17,10.0.0.27"
binlog_format=row
default_storage_engine=InnoDB
innodb_autoinc_lock_mode=2
bind-address=0.0.0.0
#下面配置可选项
wsrep_cluster_name = 'mycluster' 默认my_wsrep_cluster
wsrep_node_name = 'node1'
wsrep_node_address = '10.0.0.7'
#首次启动时,需要初始化集群,在其中一个节点上执行命令
/etc/init.d/mysql start --wsrep-new-cluster
#而后正常启动其它节点
service mysql start
#查看集群中相关系统变量和状态变量
SHOW VARIABLES LIKE 'wsrep_%';
SHOW STATUS LIKE 'wsrep_%';
SHOW STATUS LIKE 'wsrep_cluster_size';
6.3.4 TiDB 概述
TiDB 是 PingCAP 公司受 Google Spanner / F1 论文启发而设计的开源分布式 HTAP (HybridTransactional and Analytical Processing) 数据库,结合了传统的 RDBMS 和NoSQL 的最佳特性。TiDB 兼容 MySQL,支持无限的水平扩展,具备强一致性和高可用性。TiDB和mysql几乎完全兼容
TiDB 是一个分布式 NewSQL 数据库。它支持水平弹性扩展、ACID 事务、标准 SQL、MySQL 语法和MySQL 协议,具有数据强一致的高可用特性,是一个不仅适合 OLTP 场景还适合 OLAP 场景的混合数据库。TiDB年可用性达到99.95%
TiDB 的目标是为 OLTP(Online Transactional Processing) 和 OLAP (Online Analytical Processing) 场景提供一站式的解决方案。
6.3.4.1 TiDB 核心特点
- 高度兼容 MySQL 大多数情况下,无需修改代码即可从 MySQL 轻松迁移至 TiDB,分库分表后的MySQL 集群亦可通过 TiDB 工具进行实时迁移
- 水平弹性扩展 通过简单地增加新节点即可实现 TiDB 的水平扩展,按需扩展吞吐或存储,轻松应对高并发、海量数据场景
- 分布式事务 TiDB 100% 支持标准的 ACID 事务
- 真正金融级高可用 相比于传统主从 (M-S) 复制方案,基于 Raft 的多数派选举协议可以提供金融级的 100% 数据强一致性保证,且在不丢失大多数副本的前提下,可实现故障的自动恢复 (autofailover),无需人工介入
- 一站式 HTAP 解决方案 TiDB 作为典型的 OLTP 行存数据库,同时兼具强大的 OLAP 性能,配合TiSpark,可提供一站式 HTAP解决方案,一份存储同时处理OLTP & OLAP(OLAP、OLTP的介绍和比较 )无需传统繁琐的 ETL 过程
- 云原生 SQL 数据库 TiDB 是为云而设计的数据库,同 Kubernetes 深度耦合,支持公有云、私有云和混合云,使部署、配置和维护变得十分简单。TiDB 的设计目标是 100% 的 OLTP 场景和 80%的 OLAP 场景,更复杂的 OLAP 分析可以通过 TiSpark 项目来完成。 TiDB 对业务没有任何侵入性,能优雅的替换传统的数据库中间件、数据库分库分表等 Sharding 方案。同时它也让开发运维人员不用关注数据库 Scale 的细节问题,专注于业务开发,极大的提升研发的生产力
6.3.4.2 TiDB整体架构
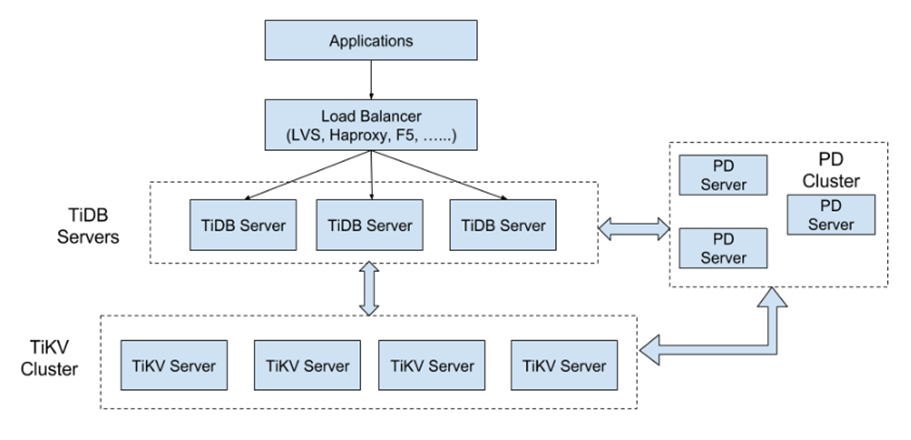
TiDB Server
TiDB Server 负责接收SQL请求,处理SQL相关的逻辑,并通过PD找到存储计算所需数据的TiKV地址,与TiKV交互获取数据,最终返回结果。TiDB Server 是无状态的,其本身并不存储数据,只负责计算,可以无限水平扩展,可以通过负载均衡组件(LVS、HAProxy或F5)对外提供统一的接入地址。
PD Server
Placement Driver(简称PD)是整个集群的管理模块,其主要工作有三个:一是存储集群的元信息(某个Key存储在那个TiKV节点);二是对TiKV集群进行调度和负载均衡(如数据的迁移、Raft groupleader的迁移等);三是分配全局唯一且递增的事务ID
PD 是一个集群,需要部署奇数个节点,一般线上推荐至少部署3个节点。PD在选举的过程中无法对外提供服务,这个时间大约是3秒
TiKV Server
TiKV Server 负责存储数据,从外部看TiKV是一个分布式的提供事务的Key-Value存储引擎。存储数据的基本单位是Region,每个Region负责存储一个Key Range(从StartKey到EndKey的左闭右开区间)的数据,每个TiKV节点会负责多个Region。TiKV使用Raft协议做复制,保持数据的一致性和容灾。副本以Region为单位进行管理,不同节点上的多个Region构成一个Raft Group,互为副本。数据在多个TiKV之间的负载均衡由PD调度,这里也就是以Region为单位进行调度
七、性能优化
数据库服务衡量指标:
- Qps:query per second
- Tps:transaction per second
7.1 压力测试工具
7.1.1 常见 MySQL 压力测试工具
- mysqlslap
- Sysbench:功能强大,官网: https://github.com/akopytov/sysbench
- tpcc-mysql
- MySQL Benchmark Suite
- MySQL super-smack
- MyBench
7.1.2 mysqlslap
mysqlslap:来自于mariadb包,测试的过程默认生成一个mysqlslap的schema,生成测试表t1,查询和插入测试数据,mysqlslap库自动生成,如果已经存在则先删除。用--only-print来打印实际的测试过程,整个测试完成后不会在数据库中留下痕迹
使用格式:
mysqlslap [options]
常用参数 [options] 说明:
--auto-generate-sql, -a #自动生成测试表和数据,表示用mysqlslap工具自己生成的SQL脚本来测试并发压力
--auto-generate-sql-load-type=type #测试语句的类型。代表要测试的环境是读操作还是写操作还是两者混合的。取值包括:read,key,write,update和mixed(默认)
--auto-generate-sql-add-auto-increment #代表对生成的表自动添加auto_increment列,从5.1.18版本开始支持
--number-char-cols=N, -x N #自动生成的测试表中包含多少个字符类型的列,默认1
--number-int-cols=N, -y N #自动生成的测试表中包含多少个数字类型的列,默认1
--number-of-queries=N #总的测试查询次数(并发客户数×每客户查询次数)
--query=name,-q #使用自定义脚本执行测试,例如可以调用自定义的存储过程或者sql语句来执行测试
--create-schema #代表自定义的测试库名称,测试的schema
--commint=N #多少条DML后提交一次
--compress, -C #如服务器和客户端都支持压缩,则压缩信息
--concurrency=N, -c N #表示并发量,即模拟多少个客户端同时执行select。可指定多个值,以逗号或者--delimiter参数指定值做为分隔符,如:--concurrency=100,200,500
--engine=engine_name, -e engine_name #代表要测试的引擎,可以有多个,用分隔符隔开。例如:--engines=myisam,innodb
--iterations=N, -i N #测试执行的迭代次数,代表要在不同并发环境下,各自运行测试多少次
--only-print #只打印测试语句而不实际执行。
--detach=N #执行N条语句后断开重连
--debug-info, -T #打印内存和CPU的相关信息
mysqlslap示例
#单线程测试
mysqlslap -a -uroot -pmagedu
#多线程测试。使用--concurrency来模拟并发连接
mysqlslap -a -c 100 -uroot -pmagedu
#迭代测试。用于需要多次执行测试得到平均值
mysqlslap -a -i 10 -uroot -pmagedu
mysqlslap ---auto-generate-sql-add-autoincrement -a
mysqlslap -a --auto-generate-sql-load-type=read
mysqlslap -a --auto-generate-secondary-indexes=3
mysqlslap -a --auto-generate-sql-write-number=1000
mysqlslap --create-schema world -q "select count(*) from City"
mysqlslap -a -e innodb -uroot -pmagedu
mysqlslap -a --number-of-queries=10 -uroot -pmagedu
#测试同时不同的存储引擎的性能进行对比
mysqlslap -a --concurrency=50,100 --number-of-queries 1000 --iterations=5 --engine=myisam,innodb --debug-info -uroot -pmagedu
#执行一次测试,分别50和100个并发,执行1000次总查询
mysqlslap -a --concurrency=50,100 --number-of-queries 1000 --debug-info -uroot -pmagedu
#50和100个并发分别得到一次测试结果(Benchmark),并发数越多,执行完所有查询的时间越长。为了准确起见,可以多迭代测试几次
mysqlslap -a --concurrency=50,100 --number-of-queries 1000 --iterations=5 --debug-info -uroot -pmagedu
7.2 生产环境 my.cnf 配置案例
配置文件生成工具参考链接:https://imysql.com/my_cnf_generator
参考硬件:内存 32G
#打开独立表空间
innodb_file_per_table = 1
#MySQL 服务所允许的同时会话数的上限,经常出现Too Many Connections的错误提示,则需要增大此值
max_connections = 8000
#所有线程所打开表的数量
open_files_limit = 10240
#back_log 是操作系统在监听队列中所能保持的连接数
back_log = 300
#每个客户端连接最大的错误允许数量,当超过该次数,MYSQL服务器将禁止此主机的连接请求,直到MYSQL服务器重启或通过flush hosts命令清空此主机的相关信息
max_connect_errors = 1000
#每个连接传输数据大小.最大1G,须是1024的倍数,一般设为最大的BLOB的值
max_allowed_packet = 32M
#指定一个请求的最大连接时间
wait_timeout = 10
# 排序缓冲被用来处理类似ORDER BY以及GROUP BY队列所引起的排序
sort_buffer_size = 16M
#不带索引的全表扫描.使用的buffer的最小值
join_buffer_size = 16M
#查询缓冲大小
query_cache_size = 128M
#指定单个查询能够使用的缓冲区大小,缺省为1M
query_cache_limit = 4M
# 设定默认的事务隔离级别
transaction_isolation = REPEATABLE-READ
# 线程使用的堆大小. 此值限制内存中能处理的存储过程的递归深度和SQL语句复杂性,此容量的内存在每次连接时被预留.
thread_stack = 512K
# 二进制日志功能
log-bin=/data/mysqlbinlogs/
#二进制日志格式
binlog_format=row
#InnoDB使用一个缓冲池来保存索引和原始数据, 可设置这个变量到物理内存大小的80%
innodb_buffer_pool_size = 24G
#用来同步IO操作的IO线程的数量
innodb_file_io_threads = 4
#在InnoDb核心内的允许线程数量,建议的设置是CPU数量加上磁盘数量的两倍
innodb_thread_concurrency = 16
# 用来缓冲日志数据的缓冲区的大小
innodb_log_buffer_size = 16M
在日志组中每个日志文件的大小
innodb_log_file_size = 512M
# 在日志组中的文件总数
innodb_log_files_in_group = 3
# SQL语句在被回滚前,InnoDB事务等待InnoDB行锁的时间
innodb_lock_wait_timeout = 120
#慢查询时长
long_query_time = 2
#将没有使用索引的查询也记录下来
log-queries-not-using-indexes
7.3 MySQL配置最佳实践
高并发大数据的互联网业务,架构设计思路是"解放数据库CPU,将计算转移到服务层",并发量大的情况下,这些功能很可能将数据库拖死,业务逻辑放到服务层具备更好的扩展性,能够轻易实现"增机器就加性能"
参考资料:
- 阿里巴巴Java开发手册:https://developer.aliyun.com/topic/java2020
- 58到家数据库30条军规解读:http://zhuanlan.51cto.com/art/201702/531364.htm
以下规范适用场景:并发量大、数据量大的互联网业务
7.3.1 基础规范
(1)必须使用InnoDB存储引擎
解读:支持事务、行级锁、并发性能更好、CPU及内存缓存页优化使得资源利用率更高
(2)使用UTF8MB4字符集
解读:万国码,无需转码,无乱码风险,节省空间,支持表情包及生僻字
(3)数据表、数据字段必须加入中文注释
解读:N年后谁知道这个r1,r2,r3字段是干嘛的
(4)禁止使用存储过程、视图、触发器、Event
解读:高并发大数据的互联网业务,架构设计思路是"解放数据库CPU,将计算转移到服务层",并发量大的情况下,这些功能很可能将数据库拖死,业务逻辑放到服务层具备更好的扩展性,能够轻易实现"增机器就加性能"。数据库擅长存储与索引,CPU计算还是上移吧!
(5)禁止存储大文件或者大照片
解读:为何要让数据库做它不擅长的事情?大文件和照片存储在文件系统,数据库里存URI多好。
7.3.2 命名规范
(6)只允许使用内网域名,而不是ip连接数据库
(7)线上环境、开发环境、测试环境数据库内网域名遵循命名规范
业务名称:xxx
线上环境:xxx.db
开发环境:xxx.rdb
测试环境:xxx.tdb
从库在名称后加-s标识,备库在名称后加-ss标识
线上从库:xxx-s.db
线上备库:xxx-sss.db
(8)库名、表名、字段名:小写,下划线风格,不超过32个字符,必须见名知意,禁止拼音英文混用
(9)库名与应用名称尽量一致,表名:t_业务名称_表的作用,主键名:pk_xxx,非唯一索引名:idx_xxx,唯一键索引名:uk_xxx
7.3.3 表设计规范
(10)单实例表数目必须小于500
单表行数超过500万行或者单表容量超过2GB,才推荐进行分库分表。
说明:如果预计三年后的数据量根本达不到这个级别,请不要在创建表时就分库分表
(11)单表列数目必须小于30
(12)表必须有主键,例如自增主键
解读:
a)主键递增,数据行写入可以提高插入性能,可以避免page分裂,减少表碎片提升空间和内存的使用
b)主键要选择较短的数据类型, Innodb引擎普通索引都会保存主键的值,较短的数据类型可以有效的减少索引的磁盘空间,提高索引的缓存效率
c) 无主键的表删除,在row模式的主从架构,会导致备库夯住
(13)禁止使用外键,如果有外键完整性约束,需要应用程序控制
解读:外键会导致表与表之间耦合,update与delete操作都会涉及相关联的表,十分影响sql 的性能,甚至会造成死锁。高并发情况下容易造成数据库性能,大数据高并发业务场景数据库使用以性能优先
7.3.4 字段设计规范
(14)必须把字段定义为NOT NULL并且提供默认值
解读:
a)null的列使索引/索引统计/值比较都更加复杂,对MySQL来说更难优化
b)null 这种类型MySQL内部需要进行特殊处理,增加数据库处理记录的复杂性;同等条件下,表中有较多空字段的时候,数据库的处理性能会降低很多
c)null值需要更多的存储空,无论是表还是索引中每行中的null的列都需要额外的空间来标识
d)对null 的处理时候,只能采用is null或is not null,而不能采用=、in、<、<>、!=、not in这些操作符号。如:where name!='shenjian',如果存在name为null值的记录,查询结果就不会包含name为null值的记录
(15)禁止使用TEXT、BLOB类型
解读:会浪费更多的磁盘和内存空间,非必要的大量的大字段查询会淘汰掉热数据,导致内存命中率急剧降低,影响数据库性能
(16)禁止使用小数存储货币
解读:使用整数吧,小数容易导致钱对不上
(17)必须使用varchar(20)存储手机号
解读:
a)涉及到区号或者国家代号,可能出现+-()
b)手机号会去做数学运算么?
c)varchar可以支持模糊查询,例如:like"138%"
(18)禁止使用ENUM,可使用TINYINT代替
解读:
a)增加新的ENUM值要做DDL操作
b)ENUM的内部实际存储就是整数,你以为自己定义的是字符串?
7.3.5索引设计规范
(19)单表索引建议控制在5个以内
(20)单索引字段数不允许超过5个
解读:字段超过5个时,实际已经起不到有效过滤数据的作用了
(21)禁止在更新十分频繁、区分度不高的属性上建立索引
解读:
a)更新会变更B+树,更新频繁的字段建立索引会大大降低数据库性能
b)"性别"这种区分度不大的属性,建立索引是没有什么意义的,不能有效过滤数据,性能与全表扫描类似
(22)建立组合索引,必须把区分度高的字段放在前面
解读:能够更加有效的过滤数据
7.3.6 SQL使用规范
(23)禁止使用SELECT *,只获取必要的字段,需要显示说明列属性
解读:
a)读取不需要的列会增加CPU、IO、NET消耗
b)不能有效的利用覆盖索引
c)使用SELECT *容易在增加或者删除字段后出现程序BUG
(24)禁止使用INSERT INTO t_xxx VALUES(xxx),必须显示指定插入的列属性
解读:容易在增加或者删除字段后出现程序BUG
(25)禁止使用属性隐式转换
解读:SELECT uid FROM t_user WHERE phone=13812345678 会导致全表扫描,而不能命中phone索引,猜猜为什么?(这个线上问题不止出现过一次)
(26)禁止在WHERE条件的属性上使用函数或者表达式
解读:SELECT uid FROM t_user WHERE from_unixtime(day)>='2017-02-15' 会导致全表扫描
正确的写法是:SELECT uid FROM t_user WHERE day>= unix_timestamp('2017-02-15 00:00:00')
(27)禁止负向查询,以及%开头的模糊查询
解读:
a)负向查询条件:NOT、!=、<>、!<、!>、NOT IN、NOT LIKE等,会导致全表扫描
b)%开头的模糊查询,会导致全表扫描
(28)禁止大表使用JOIN查询,禁止大表使用子查询
解读:会产生临时表,消耗较多内存与CPU,极大影响数据库性能
(29)禁止使用OR条件,必须改为IN查询
解读:旧版本Mysql的OR查询是不能命中索引的,即使能命中索引,为何要让数据库耗费更多的CPU帮助实施查询优化呢?
(30)应用程序必须捕获SQL异常,并有相应处理