

一、OpenKruise介绍
OpenKruise是一个基于Kubernetes的扩展套件,他提供的绝大部分能力都是基于CRD扩展来定义,他们不存在任何外部依赖,可以运行在任意纯净的Kubernetes集群中。简单来说OpenKruise对于Kubernetes是一个辅助扩展角色。Kubernetes自身已经提供了一些应用部署管理的功能,比如一些基础工作负载。 但对于大规模应用与集群的场景,这些基础功能是远远不够的。OpenKruise可以被很容易地安装到任意Kubernetes集群中,它弥补了Kubernetes在应用部署、升级、防护、运维等领域的不足。
- OpenKruise包含了一系列增强版本的Workloads(工作负载),比如CloneSet、Advanced StatefulSet、Advanced DaemonSet、BroadcastJob等,它们不仅支持类似于 Kubernetes 原生 Workloads 的基础功能,还提供了如原地升级、可配置的扩缩容/发布策略、并发操作等。其中,原地升级是一种升级应用容器镜像甚至环境变量的全新方式,它只会用新的镜像重建 Pod 中的特定容器,整个 Pod 以及其中的其他容器都不会被影响。因此它带来了更快的发布速度,以及避免了对其他 Scheduler、CNI、CSI 等组件的负面影响。
- OpenKruise提供了多种通过旁路管理应用sidecar容器、多区域部署的方式,“旁路”意味着你可以不需要修改应用的Workloads来实现它们。比如,SidecarSet能帮助你在所有匹配的Pod创建的时候都注入特定的sidecar容器,甚至可以原地升级已经注入的sidecar容器镜像、并且对Pod中其他容器不造成影响。而WorkloadSpread可以约束无状态Workload扩容出来Pod的区域分布,赋予单一workload的多区域和弹性部署的能力。
- OpenKruise在为应用的高可用性防护方面也做出了很多努力。目前它可以保护你的Kubernetes资源不受级联删除机制的干扰,包括CRD、Namespace、以及几乎全部的Workloads类型资源。相比于Kubernetes原生的PDB只提供针对Pod Eviction的防护,PodUnavailableBudget能够防护 Pod Deletion、Eviction、Update 等许多种 voluntary disruption 场景。
- OpenKruise 也提供了很多高级的运维能力来帮助你更好地管理应用。你可以通过ImagePullJob来在任意范围的节点上预先拉取某些镜像,或者指定某个 Pod中的一个或多个容器被原地重启。
1.1 系统架构
它是一个Kubernetes的标准扩展套件,目前包括 kruise-manager 和 kruise-daemon 两个组件。 PaaS 平台可以通过使用 OpenKruise 提供的这些扩展功能,来使得应用部署、管理流程更加强大与高效。
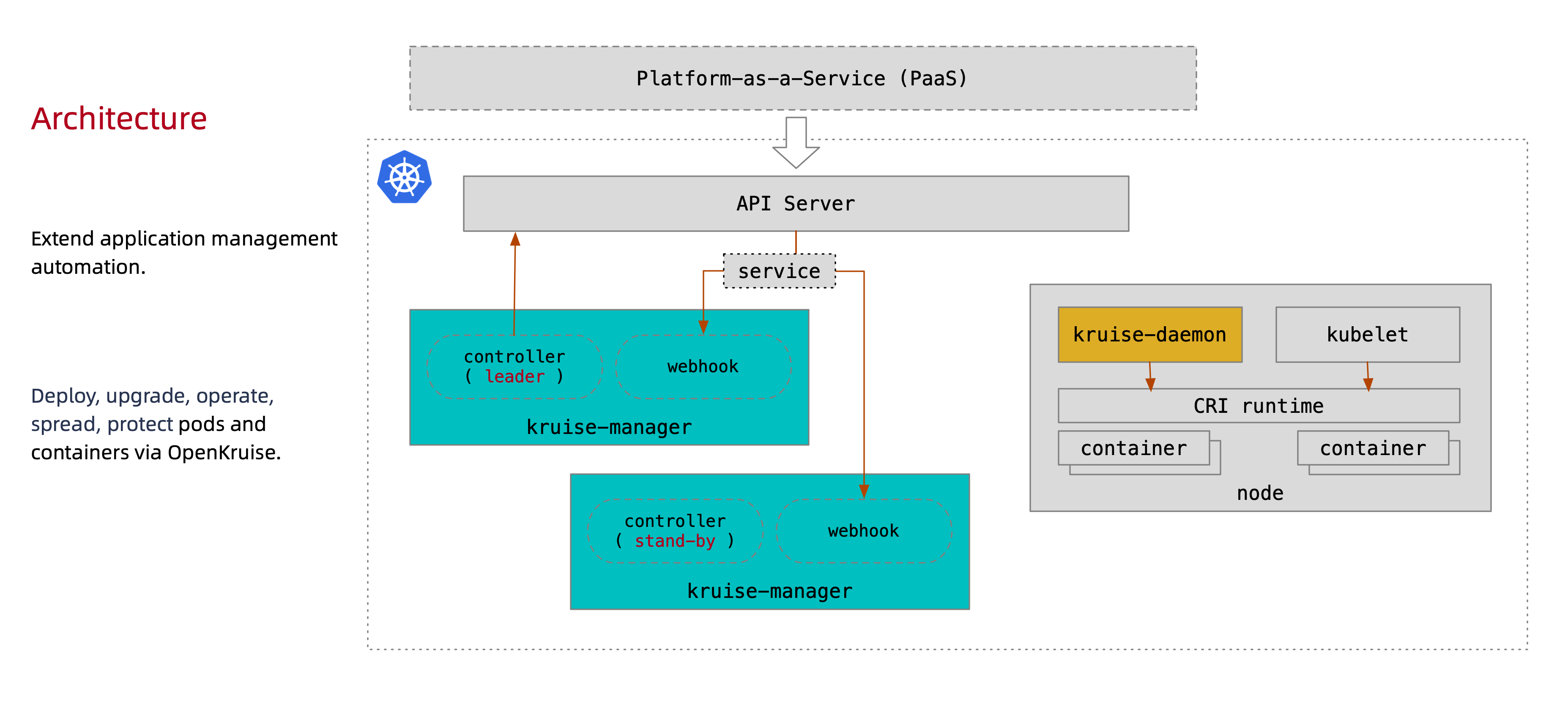
所有 OpenKruise 的功能都是通过 Kubernetes API 来提供
$ kubectl get crd | grep kruise.io
advancedcronjobs.apps.kruise.io 2022-09-01T02:24:53Z
broadcastjobs.apps.kruise.io 2022-09-01T02:24:53Z
clonesets.apps.kruise.io 2022-09-01T02:24:53Z
containerrecreaterequests.apps.kruise.io 2022-09-01T02:24:53Z
daemonsets.apps.kruise.io 2022-09-01T02:24:53Z
imagepulljobs.apps.kruise.io 2022-09-01T02:24:53Z
nodeimages.apps.kruise.io 2022-09-01T02:24:53Z
persistentpodstates.apps.kruise.io 2022-09-01T02:24:53Z
podunavailablebudgets.policy.kruise.io 2022-09-01T02:24:53Z
resourcedistributions.apps.kruise.io 2022-09-01T02:24:53Z
sidecarsets.apps.kruise.io 2022-09-01T02:24:53Z
statefulsets.apps.kruise.io 2022-09-01T02:24:53Z
uniteddeployments.apps.kruise.io 2022-09-01T02:24:53Z
workloadspreads.apps.kruise.io 2022-09-01T02:24:53Z
Kruise-manager 是一个运行 controller 和 webhook 中心组件,它通过 Deployment 部署在 kruise-system 命名空间中。
$ kubectl get pod -n kruise-system -l control-plane=controller-manager
NAME READY STATUS RESTARTS AGE
kruise-controller-manager-5df958b8c7-29xlv 1/1 Running 0 3m10s
kruise-controller-manager-5df958b8c7-wmqr4 1/1 Running 0 3m10s
除了 controller 之外,kruise-controller-manager-xxx 中还包含了针对 Kruise CRD 以及 Pod 资源的 admission webhook。Kruise-manager 会创建一些 webhook configurations 来配置哪些资源需要感知处理、以及提供一个 Service 来给 kube-apiserver 调用。
$ kubectl get svc -n kruise-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kruise-webhook-service ClusterIP 172.20.84.74 <none> 443/TCP 4m16s
上述的 kruise-webhook-service 非常重要,是提供给 kube-apiserver 调用的。
它通过 DaemonSet 部署到每个 Node 节点上,提供镜像预热、容器重启等功能。
$ kubectl get pod -n kruise-system -l control-plane=daemon
NAME READY STATUS RESTARTS AGE
kruise-daemon-4f2dh 1/1 Running 0 5m1s
kruise-daemon-4fhtz 1/1 Running 0 5m1s
kruise-daemon-4k2fp 1/1 Running 0 5m1s
kruise-daemon-4sdzz 1/1 Running 0 5m1s
kruise-daemon-5cm9b 1/1 Running 0 5m1s
kruise-daemon-7lr9j 1/1 Running 0 5m1s
kruise-daemon-8rnzw 1/1 Running 0 5m1s
kruise-daemon-bcpn4 1/1 Running 0 5m1s
kruise-daemon-f99jj 1/1 Running 0 5m1s
kruise-daemon-ftp22 1/1 Running 0 5m1s
kruise-daemon-g67jb 1/1 Running 0 5m1s
kruise-daemon-l6dpt 1/1 Running 0 5m1s
kruise-daemon-mm6sn 1/1 Running 0 5m1s
kruise-daemon-mskn9 1/1 Running 0 5m1s
kruise-daemon-nn56x 1/1 Running 0 5m1s
kruise-daemon-q57ws 1/1 Running 0 5m1s
kruise-daemon-qvmgr 1/1 Running 0 5m1s
kruise-daemon-rsj2w 1/1 Running 0 5m1s
kruise-daemon-ssfzv 1/1 Running 0 5m1s
kruise-daemon-z48z5 1/1 Running 0 5m1s
kruise-daemon-z76px 1/1 Running 0 5m1s
1.2 OpenKruise部署
OpenKruise要求在 Kubernetes >= 1.16 以上版本的集群中安装和使用。建议采用 helm v3.5+ 来安装 Kruise。
#添加仓库
helm repo add openkruise https://openkruise.github.io/charts/
#下载chart包
helm pull openkruise/kruise
#解压包
tar xf kruise-1.2.0.tgz
#修改配置主要修改values.yaml中镜像
image:
repository: 192.168.6.77:5000/kruise-manager
tag: v1.2.0
#部署
helm install kruise .
#验证
kubectl get pod -n kruise-system
以上部署都已默认配置部署,如果需要修改请查看官方文档:https://openkruise.io/zh/docs/installation#%E5%8F%AF%E9%80%89-chart-%E5%AE%89%E8%A3%85%E5%8F%82%E6%95%B0
二、OpenKruise使用详解
2.1 原地升级
原地升级是 OpenKruise 提供的核心功能之一,目前支持原地升级的Workload:
- CloneSet
- Advanced StatefulSet
- Advanced DaemonSet
- SidecarSet
重建升级时我们要删除旧 Pod、创建新 Pod:
- Pod 名字和 uid 发生变化,因为它们是完全不同的两个 Pod 对象(比如 Deployment 升级)
- Pod 名字可能不变、但 uid 变化,因为它们是不同的 Pod 对象,只是复用了同一个名字(比如 StatefulSet 升级)
- Pod 所在 Node 名字发生变化,因为新 Pod 很大可能性是不会调度到之前所在的 Node 节点的
- Pod IP 发生变化,因为新 Pod 很大可能性是不会被分配到之前的 IP 地址的
但是对于原地升级,我们仍然复用同一个 Pod 对象,只是修改它里面的字段。因此:
- 可以避免如 调度、分配 IP、分配、挂载盘 等额外的操作和代价
- 更快的镜像拉取,因为开源复用已有旧镜像的大部分 layer 层,只需要拉取新镜像变化的一些 layer
- 当一个容器在原地升级时,Pod 中的其他容器不会受到影响,仍然维持运行
提供了三种升级方式:
ReCreate: 控制器会删除旧 Pod 和它的 PVC,然后用新版本重新创建出来。InPlaceIfPossible: 控制器会优先尝试原地升级 Pod,如果不行再采用重建升级。InPlaceOnly: 控制器只允许采用原地升级。因此,用户只能修改上一条中的限制字段,如果尝试修改其他字段会被 Kruise 拒绝。
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
spec:
# ...
updateStrategy:
type: InPlaceIfPossible
# ...
- 修改
app-image:v1镜像,会触发原地升级。 - 修改 annotations 中
app-config的 value 内容,会触发原地升级。 - 同时修改上述两个字段,会在原地升级中同时更新镜像和环境变量。
- 直接修改 env 中
APP_NAME的 value 内容或者新增 env 等其他操作,会触发 Pod 重建升级。
2.2 CloneSet
CloneSet控制器提供了高效管理无状态应用的能力,它可以对标原生的 Deployment,但 CloneSet 提供了很多增强功能。
文件示例
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
metadata:
labels:
app: cloneset-dev
name: cloneset-dev
namespace: kri-dev
spec:
replicas: 1
scaleStrategy:
podsToDelete:
- cloneset-dev-r25n8
selector:
matchLabels:
app: cloneset-dev
template:
metadata:
labels:
app: cloneset-dev
spec:
containers:
- name: net
image: 192.168.6.77:5000/alpine:net
- name: alpine
image: 192.168.6.77:5000/riped/alpine:3.8
command:
- sh
- -c
- "sleep 360000"
volumeMounts:
- name: cloneset-data
mountPath: /data1
volumeClaimTemplates:
- metadata:
name: cloneset-data
spec:
accessModes: [ "ReadWriteMany" ]
storageClassName: "managed-nfs-storage"
resources:
requests:
storage: 1Gi
1.支持PVC模板
CloneSet 允许用户配置 PVC 模板 volumeClaimTemplates,用来给每个 Pod 生成独享的 PVC,这是 Deployment 所不支持的。 如果用户没有指定这个模板,CloneSet 会创建不带 PVC 的 Pod。
- 每个被自动创建的PVC会有一个ownerReference指向CloneSet,因此CloneSet被删除时,它创建的所有Pod和PVC都会被删除。
- 每个被CloneSet创建的Pod和PVC,都会带一个
apps.kruise.io/cloneset-instance-id: xxx的 label。关联的Pod和PVC会有相同的 instance-id,且它们的名字后缀都是这个 instance-id。 - 如果一个Pod被CloneSet controller缩容删除时,这个Pod关联的PVC都会被一起删掉。
- 如果一个Pod被外部直接调用删除或驱逐时,这个Pod关联的PVC还都存在;并且CloneSet controller发现数量不足重新扩容时,新扩出来的 Pod 会复用原Pod的instance-id 并关联原来的PVC。
- 当Pod被重建升级时,关联的PVC会跟随Pod一起被删除、新建。
- 当Pod被原地升级时,关联的PVC会持续使用。
- 注意必须配置访问模式,否则会报错。
2.指定Pod缩容
当一个 CloneSet 被缩容时,有时候用户需要指定一些 Pod 来删除。这对于 StatefulSet 或者 Deployment 来说是无法实现的,因为 StatefulSet 要根据序号来删除 Pod,而 Deployment/ReplicaSet 目前只能根据控制器里定义的排序来删除。
CloneSet 允许用户在缩小 replicas 数量的同时,指定想要删除的 Pod 名字。
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
#...
spec:
replicas: 1 #指定缩容后的副本
scaleStrategy: #添加
podsToDelete: #指定缩容被删除的pod名称
- cloneset-dev-r25n8
#...
如果你只把 Pod 名字加到 podsToDelete,但没有修改 replicas 数量,那么控制器会先把指定的 Pod 删掉,然后再扩一个新的 Pod。 另一种直接删除 Pod 的方式是在要删除的 Pod 上打 apps.kruise.io/specified-delete: true 标签。
kubectl label pod -n kri-dev cloneset-dev-dkbmb apps.kruise.io/specified-delete=true
3.扩容相关
CloneSet 扩容时可以指定 ScaleStrategy.MaxUnavailable 来限制扩容的步长,以达到服务应用影响最小化的目的。 它可以设置为一个绝对值或者百分比,如果不填,则 Kruise 会设置为默认值为 nil,即表示不设限制。
该字段可以配合 Spec.MinReadySeconds 字段使用。
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
metadata:
#..
spec:
replicas: 10
minReadySeconds: 15
scaleStrategy:
maxUnavailable: 1
#..
上述配置能达到的效果是:在扩容时,只有当上一个扩容出的 Pod 已经 Ready 超过15秒后,CloneSet 才会执行创建下一个 Pod 的操作。
2.3 Advanced StatefulSet
这个控制器基于原生StatefulSet上增强了发布能力,比如 maxUnavailable 并行发布、原地升级等。
如果你对原生StatefulSet不是很了解,我们强烈建议你先阅读它的文档(在学习 Advanced StatefulSet 之前):
注意 Advanced StatefulSet 是一个 CRD,kind 名字也是 StatefulSet,但是 apiVersion 是 apps.kruise.io/v1beta1。 这个 CRD 的所有默认字段、默认行为与原生 StatefulSet 完全一致,除此之外还提供了一些 optional 字段来扩展增强的策略。
示例文件:
apiVersion: v1
kind: Service
metadata:
name: statefulset
namespace: kri-dev
spec:
clusterIP: None
selector:
app: statefulset
---
apiVersion: apps.kruise.io/v1beta1
kind: StatefulSet
metadata:
name: statefulset
namespace: kri-dev
spec:
replicas: 3
selector:
matchLabels:
app: statefulset
serviceName: statefulset
template:
metadata:
labels:
app: statefulset
spec:
containers:
- name: net
image: 192.168.6.77:5000/alpine:net
- name: alpine
image: 192.168.6.77:5000/riped/alpine:3.8
command:
- sh
- -c
- "sleep 360000"
1.MaxUnavailable最大不可用
Advanced StatefulSet 在 RollingUpdateStatefulSetStrategy 中新增了 maxUnavailable 策略来支持并行 Pod 发布,它会保证发布过程中最多有多少个 Pod 处于不可用状态。注意,maxUnavailable 只能配合 podManagementPolicy 为 Parallel 来使用。
apiVersion: apps.kruise.io/v1beta1
kind: StatefulSet
metadata:
#...
spec:
podManagementPolicy: Parallel
updateStrategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 50%
#...
2.原地升级
Advanced StatefulSet 增加了 podUpdatePolicy 来允许用户指定重建升级还是原地升级。
ReCreate: 控制器会删除旧 Pod 和它的 PVC,然后用新版本重新创建出来。InPlaceIfPossible: 控制器会优先尝试原地升级 Pod,如果不行再采用重建升级。具体参考下方阅读文档。InPlaceOnly: 控制器只允许采用原地升级。因此,用户只能修改上一条中的限制字段,如果尝试修改其他字段会被 Kruise 拒绝。
我们还在原地升级中提供了 graceful period 选项,作为优雅原地升级的策略。用户如果配置了 gracePeriodSeconds 这个字段,控制器在原地升级的过程中会先把 Pod status 改为 not-ready,然后等一段时间(gracePeriodSeconds),最后再去修改 Pod spec 中的镜像版本。 这样,就为 endpoints-controller 这些控制器留出了充足的时间来将 Pod 从 endpoints 端点列表中去除。
更重要的是,如果使用 InPlaceIfPossible 或 InPlaceOnly 策略,必须要增加一个 InPlaceUpdateReady readinessGate,用来在原地升级的时候控制器将 Pod 设置为 NotReady。
apiVersion: apps.kruise.io/v1beta1
kind: StatefulSet
metadata:
name: statefulset
namespace: kri-dev
spec:
podManagementPolicy: Parallel
updateStrategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 50%
podUpdatePolicy: InPlaceIfPossible
inPlaceUpdateStrategy:
gracePeriodSeconds: 10
replicas: 5
selector:
matchLabels:
app: statefulset
serviceName: statefulset
template:
metadata:
labels:
app: statefulset
spec:
readinessGates:
- conditionType: InPlaceUpdateReady
containers:
- name: net
image: 192.168.6.77:5000/alpine:net
- name: alpine
image: 192.168.6.77:5000/riped/alpine:3.8
command:
- sh
- -c
- "sleep 360000"
2.4 BroadcastJob
这个控制器将 Pod 分发到集群中每个 node 上,类似于 DaemonSet, 但是 BroadcastJob 管理的 Pod 并不是长期运行的 daemon 服务,而是类似于 Job的任务类型 Pod。最终在每个 node 上的 Pod 都执行完成退出后,BroadcastJob 和这些 Pod 并不会占用集群资源。 这个控制器非常有利于做升级基础软件、巡检等过一段时间需要在整个集群中跑一次的工作。此外,BroadcastJob 还可以维持每个 node 跑成功一个 Pod 任务。如果采取这种模式,当后续集群中新增 node 时 BroadcastJob 也会分发 Pod 任务上去执行。
示例文件:
apiVersion: apps.kruise.io/v1alpha1
kind: BroadcastJob
metadata:
name: broadcastjob
namespace: kri-dev
spec:
template:
spec:
containers:
- name: ps
image: 192.168.6.77:5000/alpine:net
command:
- sh
- -c
- ps
restartPolicy: Never
hostPID: true
completionPolicy:
type: Always
ttlSecondsAfterFinished: 30 #pod执行完成多少秒后被删除
activeDeadlineSeconds: 10 #pod执行多久被判断为失败
验证状态
[root@k8s-master-1-kty-sc test]# kubectl get bcj -n kri-dev
NAME DESIRED ACTIVE SUCCEEDED FAILED AGE
broadcastjob 20 0 20 0 99s
2.5 AdvancedCronJob
AdvancedCronJob 是对于原生 CronJob 的扩展版本。 后者根据用户设置的 schedule 规则,周期性创建 Job 执行任务,而 AdvancedCronJob 的 template 支持多种不同的job资源。
示例文件:
apiVersion: apps.kruise.io/v1alpha1
kind: AdvancedCronJob
metadata:
name: advancedcronjob
namespace: kri-dev
spec:
schedule: "*/1 * * * *"
template:
broadcastJobTemplate:
spec:
template:
spec:
containers:
- name: ps
image: 192.168.6.77:5000/alpine:net
command:
- sh
- -c
- ps
restartPolicy: Never
hostPID: true
completionPolicy:
type: Always
activeDeadlineSeconds: 10
ttlSecondsAfterFinished: 30
2.6 SidecarSet
这个控制器支持通过 admission webhook 来自动为集群中创建的符合条件的 Pod 注入 sidecar 容器。 这个注入过程和 istio的自动注入方式很类似。 除了在 Pod 创建时候注入外,SidecarSet 还提供了为运行时 Pod 原地升级其中已经注入的 sidecar 容器镜像的能力。
示例文件:
apiVersion: apps.kruise.io/v1alpha1
kind: SidecarSet
metadata:
name: test-sidecarset
namespace: kri-dev
spec:
updateStrategy: #更新策略
type: RollingUpdate #滚动更新
maxUnavailable: 20% #最大不可用数量
injectionStrategy: #暂停注入
paused: true
selector:
matchLabels:
zhangzhuo: zhangzhuo
containers:
- name: sidecar1
image: 192.168.6.77:5000/alpine:net
command: ["sleep", "999d"] # do nothing at all
podInjectPolicy: BeforeAppContainer #注入方式,默认为BeforeAppContainer注入到源pod的containers前面,AfterAppContainer后面
shareVolumePolicy: #共享注入pod的所有挂载卷
type: enabled
transferEnv: #共享容器环境变量
- sourceContainerName: main #那个容器
envName: PROXY_IP #那个变量
2.7 WorkloadSpread
WorkloadSpread能够将workload的Pod按一定规则分布到不同类型的Node节点上,赋予单一workload多区域部署和弹性部署的能力。
常见的一些规则包括:
- 水平打散(比如按host、az等维度的平均打散)。
- 按指定比例打散(比如按比例部署Pod到几个指定的 az 中)。
- 带优先级的分区管理,比如:
- 优先部署到ecs,资源不足时部署到eci。
- 优先部署固定数量个pod到ecs,其余到eci。
- 定制化分区管理,比如:
- 控制workload部署不同数量的Pod到不同的cpu架构上。
- 确保不同的cpu架构上的Pod配有不同的资源配额。
示例文件如下:
apiVersion: apps.kruise.io/v1alpha1
kind: WorkloadSpread
metadata:
name: workloadspread-demo
spec:
targetRef: #管理的资源
apiVersion: apps/v1 | apps.kruise.io/v1alpha1
kind: Deployment | CloneSet
name: workload-xxx
subsets:
- name: subset-a #区域名称
requiredNodeSelectorTerm: #强制匹配到某个zone
matchExpressions:
- key: topology.kubernetes.io/zone
operator: In
values:
- zone-a
preferredNodeSelectorTerms: #尽量匹配到某个zone
- weight: 1
preference:
matchExpressions:
- key: another-node-label-key
operator: In
values:
- another-node-label-value
maxReplicas: 3 #该subset所期望调度的最大副本数
tolerations: #改区域下的pod容忍度
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
patch: #定制改subset中pod配置
metadata:
labels:
xxx-specific-label: xxx
- name: subset-b
requiredNodeSelectorTerm:
matchExpressions:
- key: topology.kubernetes.io/zone
operator: In
values:
- zone-b
scheduleStrategy: #调度策略配置,workload严格按照subsets定义分布,Adaptive不严格规定。默认为Fixed
type: Adaptive | Fixed
adaptive:
rescheduleCriticalSeconds: 30
WorkloadSpread 功能默认是关闭的,你需要在安装/升级 Kruise 的时候打开 feature-gate:WorkloadSpread
helm upgrade kruise --set featureGates="WorkloadSpread=true" .
1.弹性部署
zone-a固定部署2个Pod,其余部署到zone-b中。
apiVersion: apps.kruise.io/v1alpha1
kind: WorkloadSpread
metadata:
name: ws-demo
namespace: kri-dev
spec:
targetRef: #选择匹配的控制器
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
name: cloneset-dev
subsets: #调度配置
- name: zone-a #zone-a定义为只允许调度2个pod副本
requiredNodeSelectorTerm:
matchExpressions:
- key: topology.application.deploy/zone
operator: In
values:
- zone-a
maxReplicas: 2
patch: #pod注入label
metadata:
labels:
topology.application.deploy/zone: zone-a
- name: zone-b #zone-b定义为其余pod调度到zone-b
requiredNodeSelectorTerm:
matchExpressions:
- key: topology.application.deploy/zone
operator: In
values:
- zone-b
patch: #pod注入lable
metadata:
labels:
topology.application.deploy/zone: zone-b